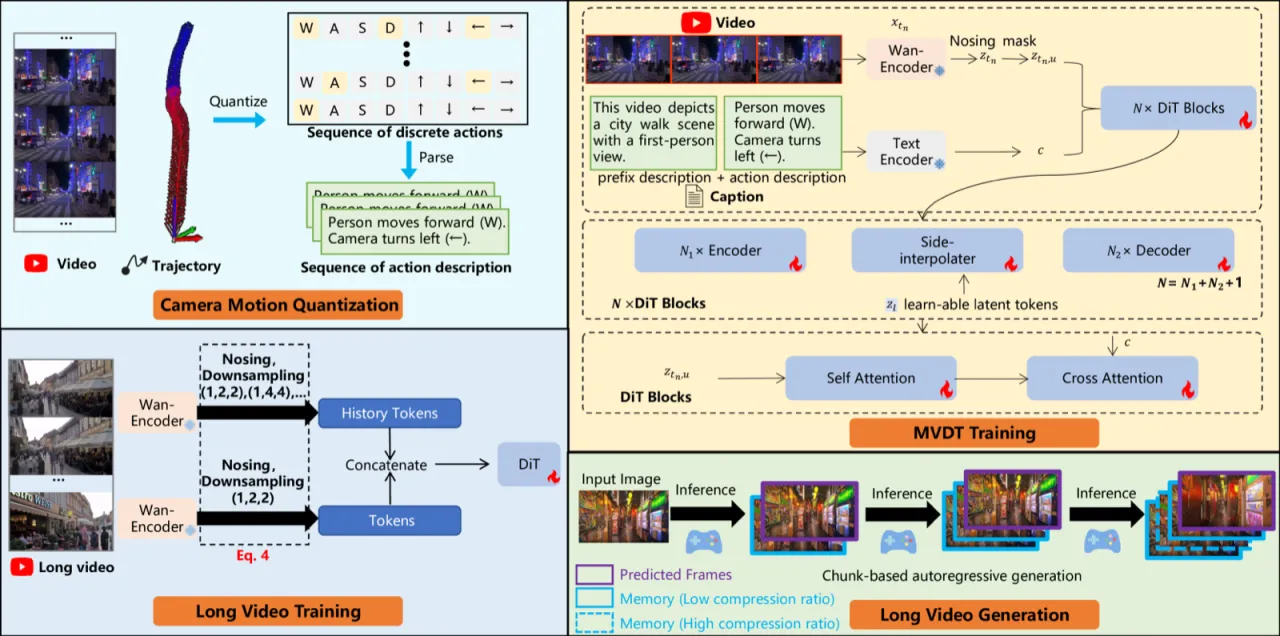
"Yume aims to use images, text, or videos to create an interactive, realistic, and dynamic world, which allows exploration and control using peripheral devices or neural signals."
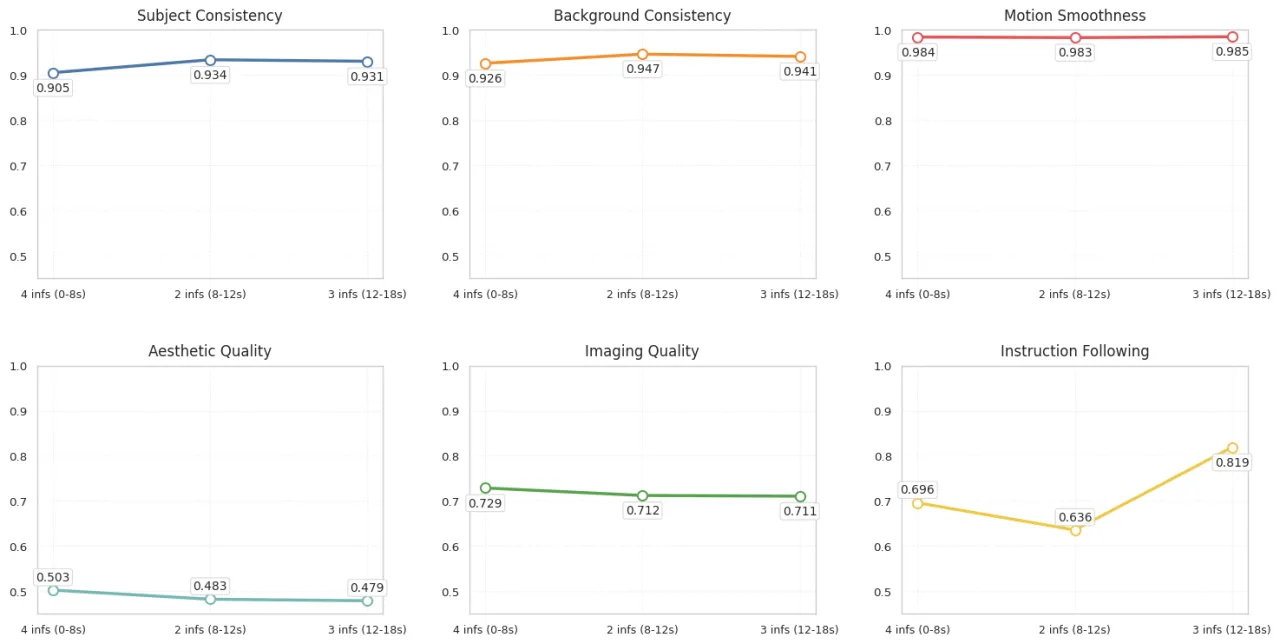
论文明确指出:"it does not perform well on autoregressive long video generation due to a lack of V2V foundation models"。AAM 的高频精修机制依赖单段视频的去噪结构,在多段自回归拼接场景下效果退化,作者计划在下一版本中解决。
作者在结论中坦承:"Yume is a long-term project that has established a solid foundation, yet still faces numerous challenges to address, such as the visual quality, runtime efficiency, and control accuracy. Moreover, many functions need to be achieved, such as interaction with objects."本次发布为 preview 版本,将以月度迭代方式持续更新。