01 动机
当前 VLA 模型在跨平台联合训练时面临严峻的异构性挑战:不同机器人平台的观测空间、动作空间、相机配置差异显著,简单混合训练反而会损害单平台性能。如何在利用多平台数据规模优势的同时,保留各平台的专有特征,是实现真正通用机器人策略的关键瓶颈。
"The success of VLA models, particularly their ability to rapidly adapt to out-of-distribution (OOD) domains, hinges on pretraining with large and diverse robotics datasets that span multiple robotic architectures and task scenarios."
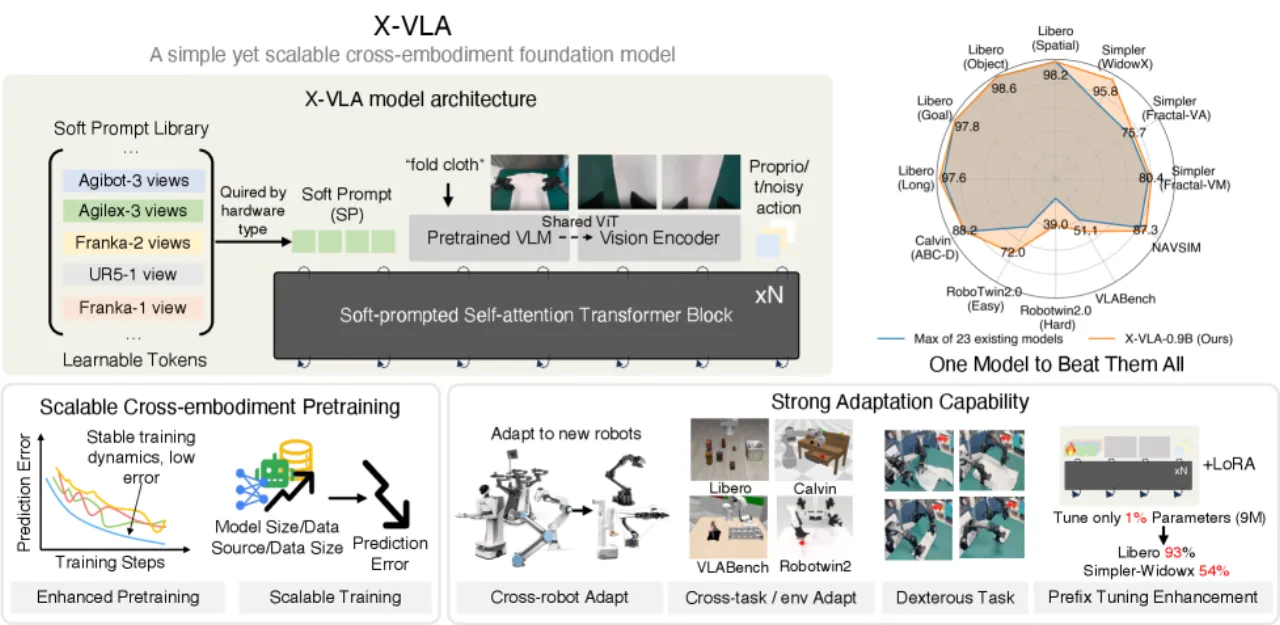
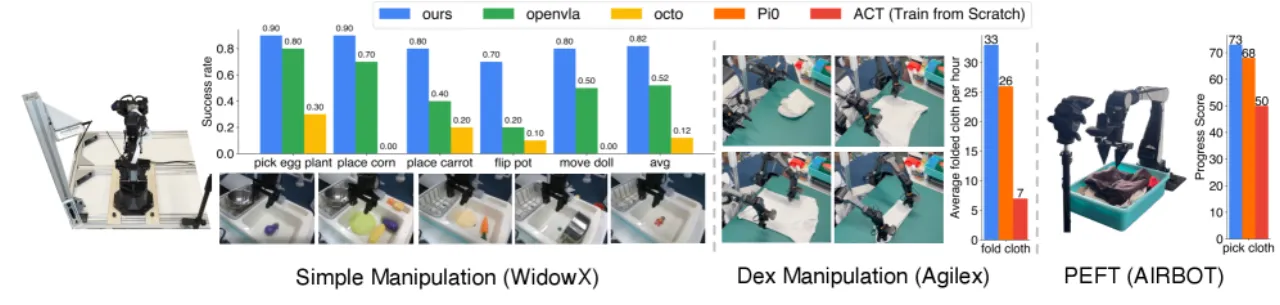
5/5仿真基准达 SOTA
0.9B预训练参数量
9MPEFT 可调参数(仅 1%)
290K预训练 episodes
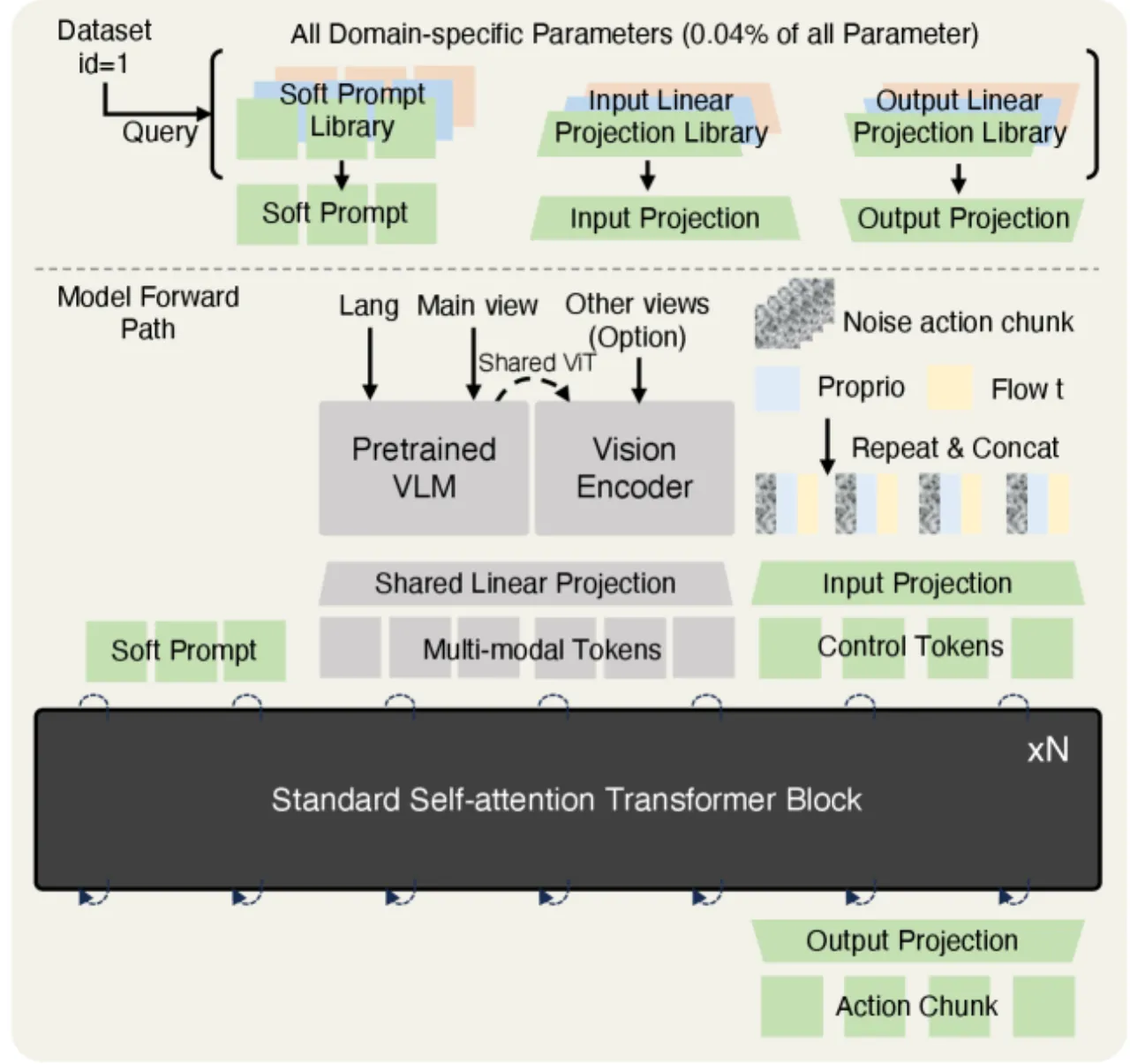
四种异构处理策略的对比
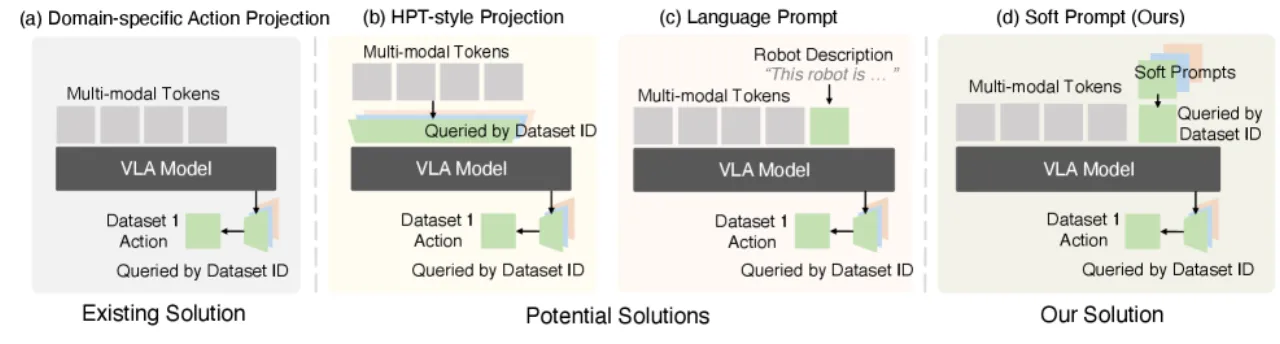
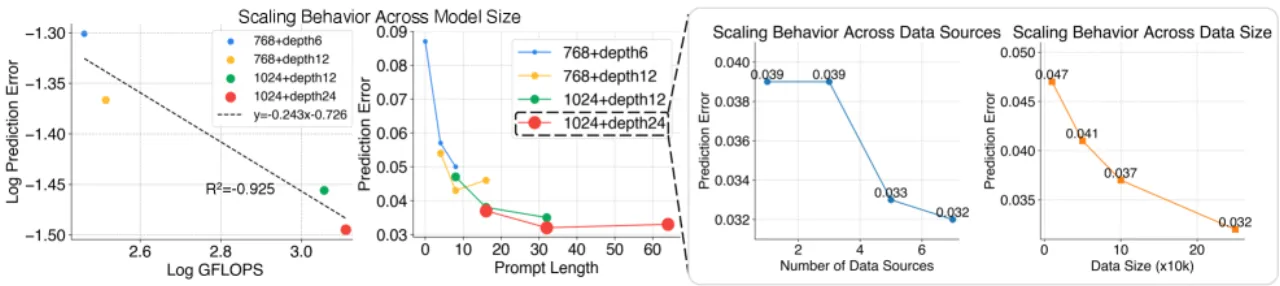
论文在 Table 1 的消融路径中系统验证了各设计选择的贡献:从无预训练基线(验证误差 4.1,适配成功率 39.6%)出发,逐步引入动作对齐、意图抽象、平衡采样、Transformer encoder 替换 DiT、编码 pipeline 改进,最终加入软提示,将适配成功率提升至 73.0%,验证误差降至 0.038。