01 动机
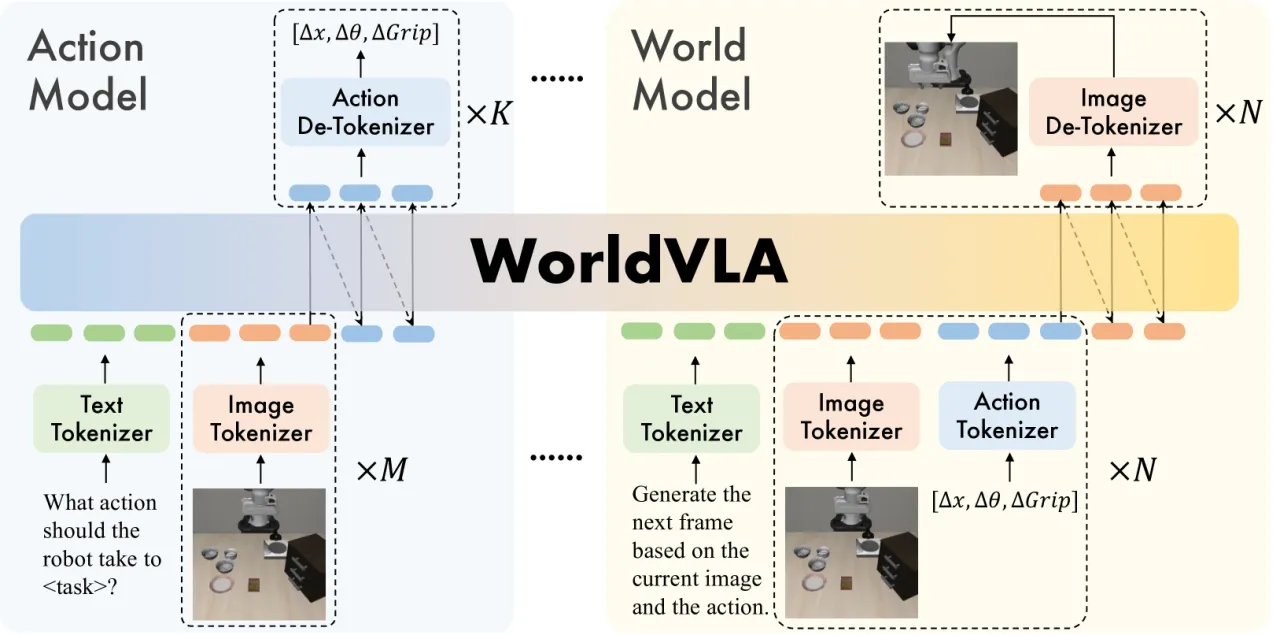
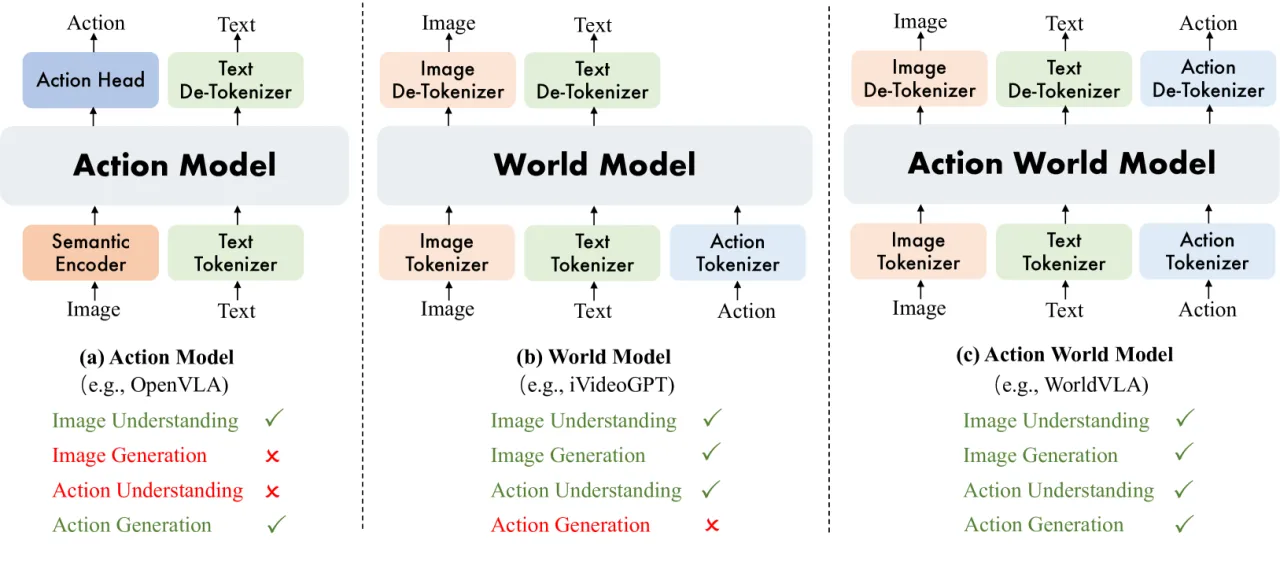
当前机器人学习中,动作模型(VLA)与世界模型被视为两个相互独立的范式:VLA 从图像和文本预测动作,世界模型从图像和动作预测未来帧。这两者的能力存在天然互补性,但此前没有工作将它们真正统一在同一框架中并验证相互增益。
"We integrate action model and world model into a unified framework, demonstrate that action and image generation mutually enhance each other, and propose an attention mask strategy that selectively masks prior actions during the generation of the current action."
81.8%WorldVLA 512×512
LIBERO 平均 SR
LIBERO 平均 SR
76.5%OpenVLA 基线
LIBERO 平均 SR
LIBERO 平均 SR
−10%FVD 改善
vs. 纯世界模型(50 帧)
vs. 纯世界模型(50 帧)
+4%抓取成功率提升
vs. 同骨干动作模型
vs. 同骨干动作模型
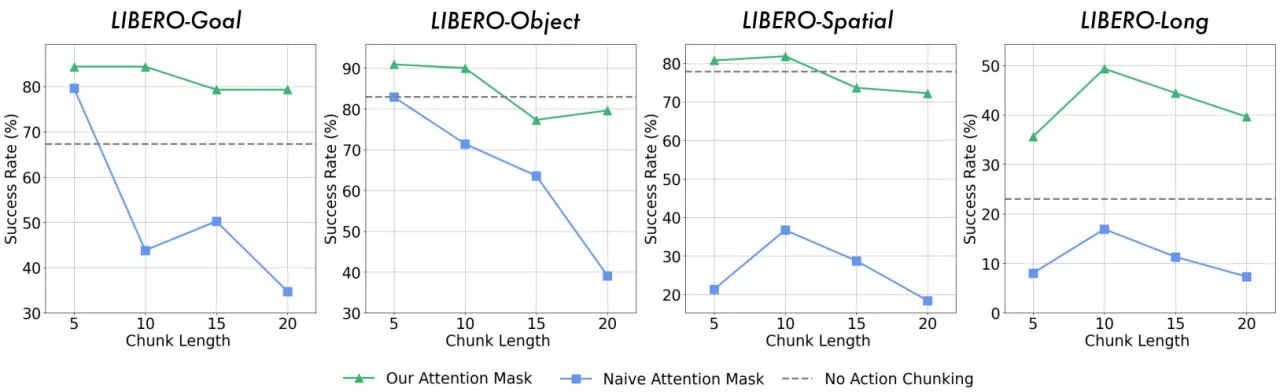
核心问题:动作块生成中的误差累积
在自回归生成多步动作块(action chunk)时,每一步动作都依赖前一步的输出。若前一步出现误差,后续动作会受到污染,导致整体性能显著下降。实验表明,在不加干预的情况下加入 action chunking 会导致成功率下降 10–50 个百分点。