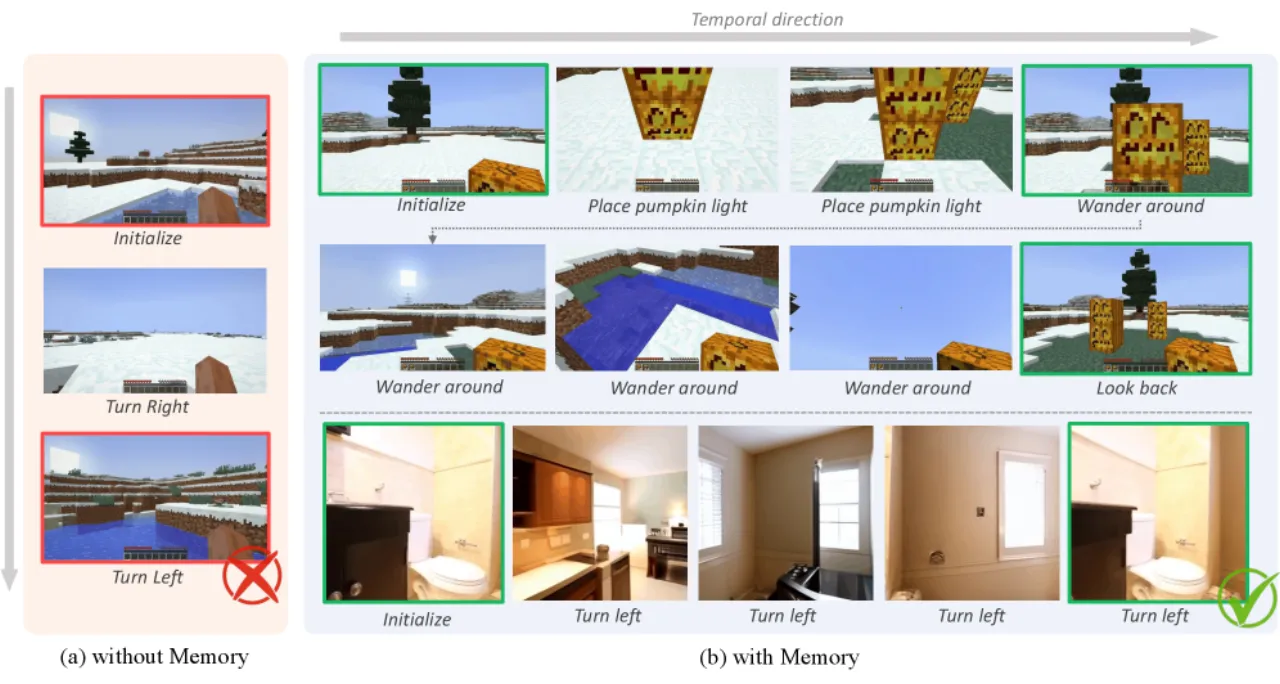
02 方法
WorldMem 以 Conditional Diffusion Transformer(CDiT)与 Diffusion Forcing 为基础,在其上引入三个核心组件:记忆库(Memory Bank)、置信度检索(Confidence-based Retrieval)和状态感知记忆注意力(State-aware Memory Attention),共同实现对历史场景的高效感知与忠实重建。
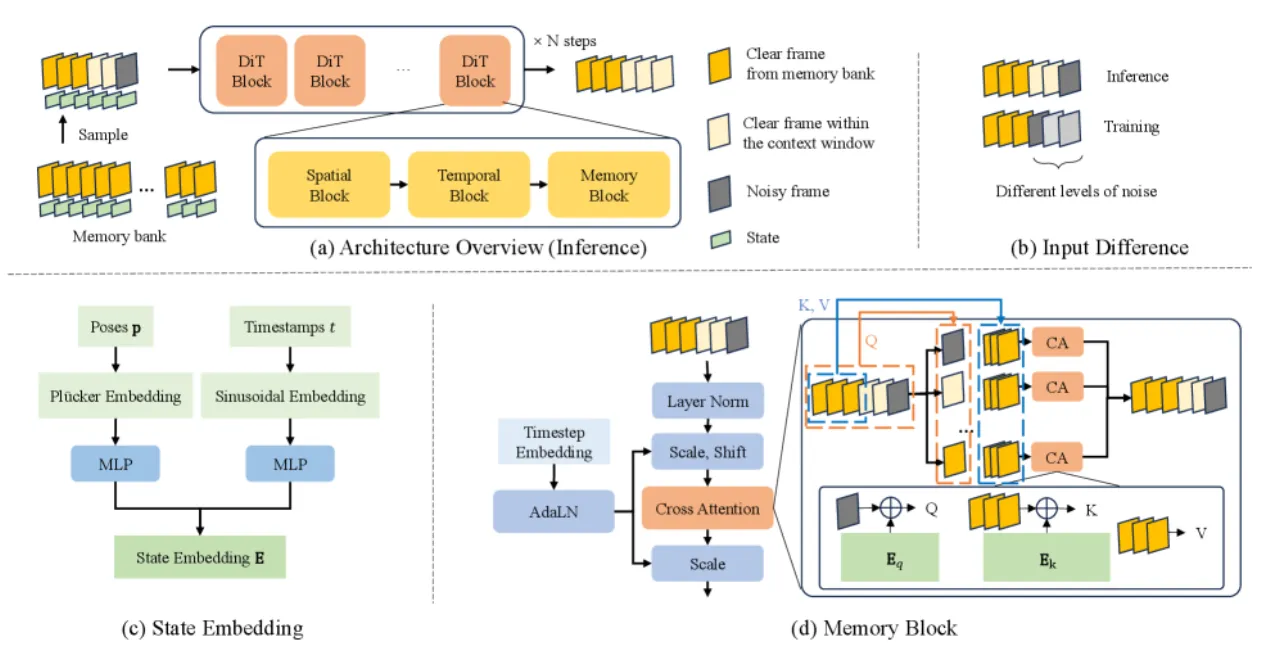 图2 · 架构总览:生成时,模型维护一个记忆库,存储历史帧的 latent token 及对应 5D 姿态与时间戳三元组 {(x_i, p_i, t_i)}。每步推理通过置信度检索选取 L_M 帧记忆,经状态感知 cross-attention 注入当前生成过程。
图2 · 架构总览:生成时,模型维护一个记忆库,存储历史帧的 latent token 及对应 5D 姿态与时间戳三元组 {(x_i, p_i, t_i)}。每步推理通过置信度检索选取 L_M 帧记忆,经状态感知 cross-attention 注入当前生成过程。
记忆库设计(Memory Bank)
记忆库以元组序列 {(𝐱ᵢᵐ, 𝐩ᵢ, tᵢ)} 的形式保存所有已生成帧的 latent token、5D 相机姿态(x, y, z, pitch, yaw)和时间戳。这种几何无关(geometry-free)表示无需维护显式三维结构,天然支持动态场景。存储 600 帧仅需约 21 MB,检索延迟在 1000 个候选帧时也仅为 0.16 秒。
基于置信度的检索(Confidence-based Retrieval)
检索算法综合三项打分维度为每个记忆单元计算置信度:
- FOV 重叠率:通过 Monte Carlo 采样估算当前视角与历史帧视野的空间交叠,优先选取"能看到当前场景"的历史帧;
- 时间临近度权重:近期帧与当前生成更相关;
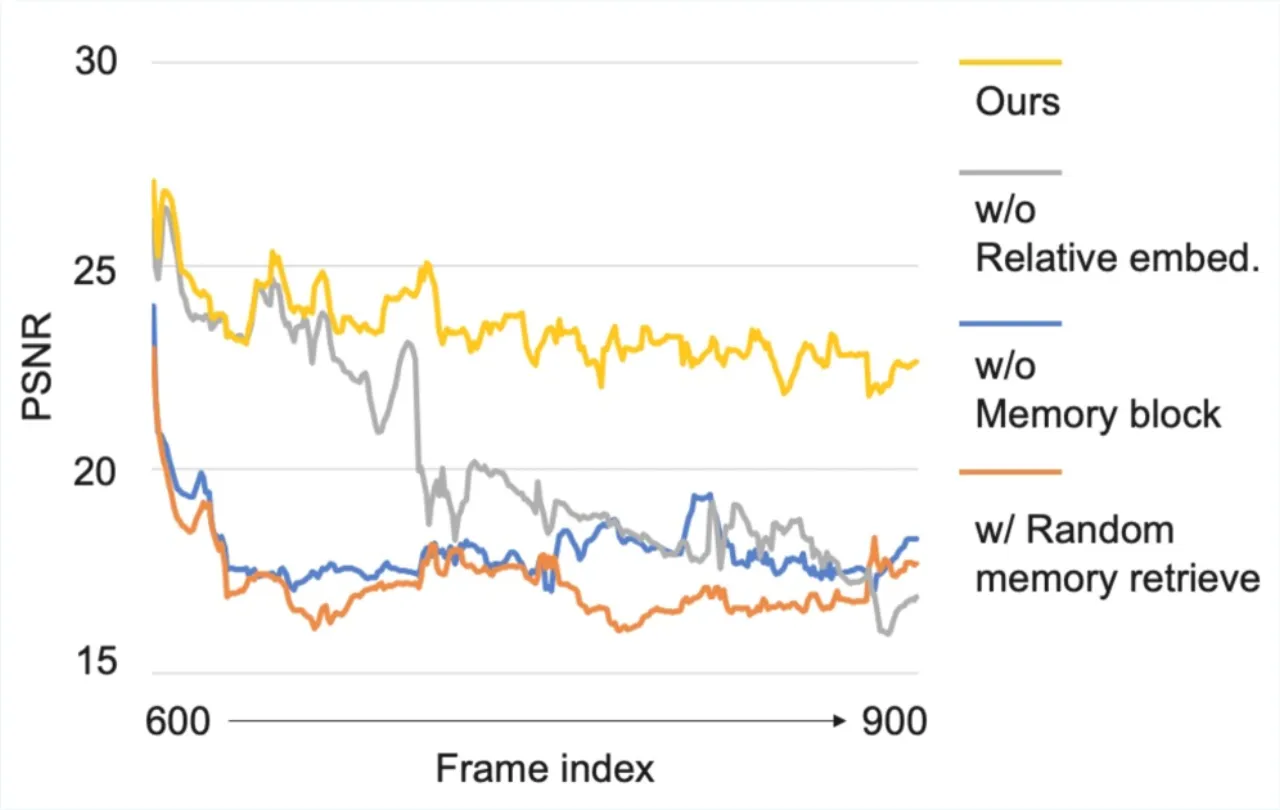
- 相似度过滤(Similarity Filtering):剔除冗余帧,确保 L_M 帧记忆覆盖多样视角。消融实验中加入相似度过滤后 rFID 从 24.33 降至 15.37。
状态感知记忆注意力(State-aware Memory Attention)
与单纯视觉 token 注意力不同,WorldMem 将显式时空状态嵌入融入 cross-attention 的 Q/K 计算:
- Plücker embedding:对相机姿态进行空间编码,提供每帧的射线级别位置感知;
- 时间戳 sinusoidal embedding:允许模型区分同一位置在不同时刻的状态(如白天/夜晚、植被生长);
- 相对状态表达:将当前帧设为零参考,所有历史帧姿态转换为相对坐标,提升泛化性(PSNR: 23.63 → 23.98, LPIPS: 0.1830 → 0.1429)。
Cross-attention 公式为:CrossAttn(Q=p_q(X̃_q), K=p_k(X̃_k), V=p_v(X_k)),其中 Q/K 融合状态嵌入,V 保留纯视觉特征。
训练策略
记忆帧使用最低噪声等级 k_min,上下文帧则在 [k_min, k_max] 范围内采样;时序注意力掩码防止记忆单元互相影响,保持因果性。训练时采用渐进式距离采样(Progressive Sampling):从小范围(2m)逐渐扩展至大范围(8m),使模型学会处理大视角跨度的重访场景,相比固定 8m 采样 PSNR 提升 2.87(21.11 → 23.98)。