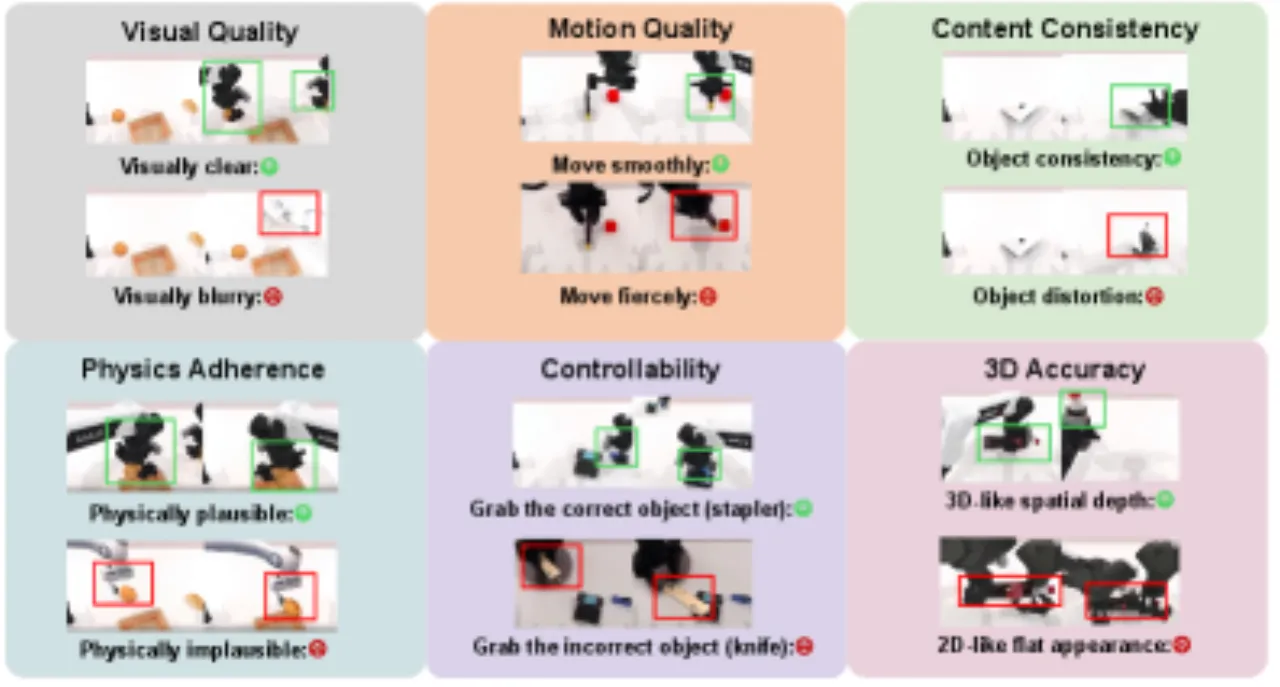
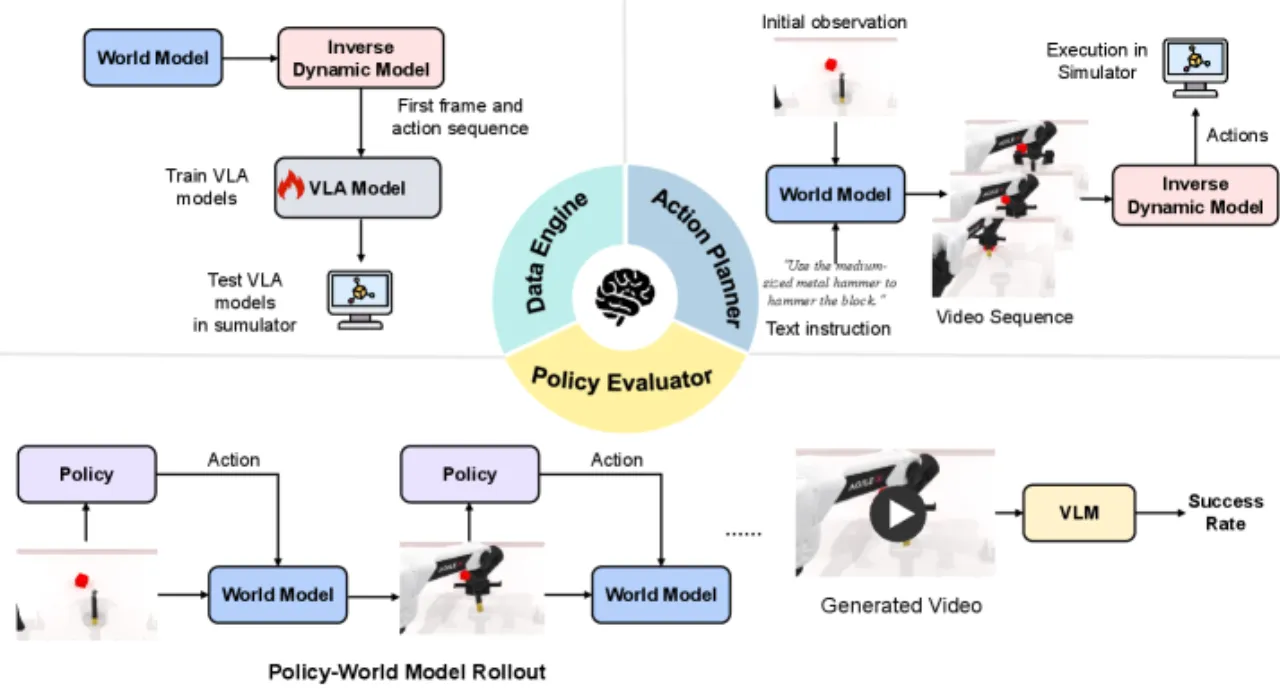
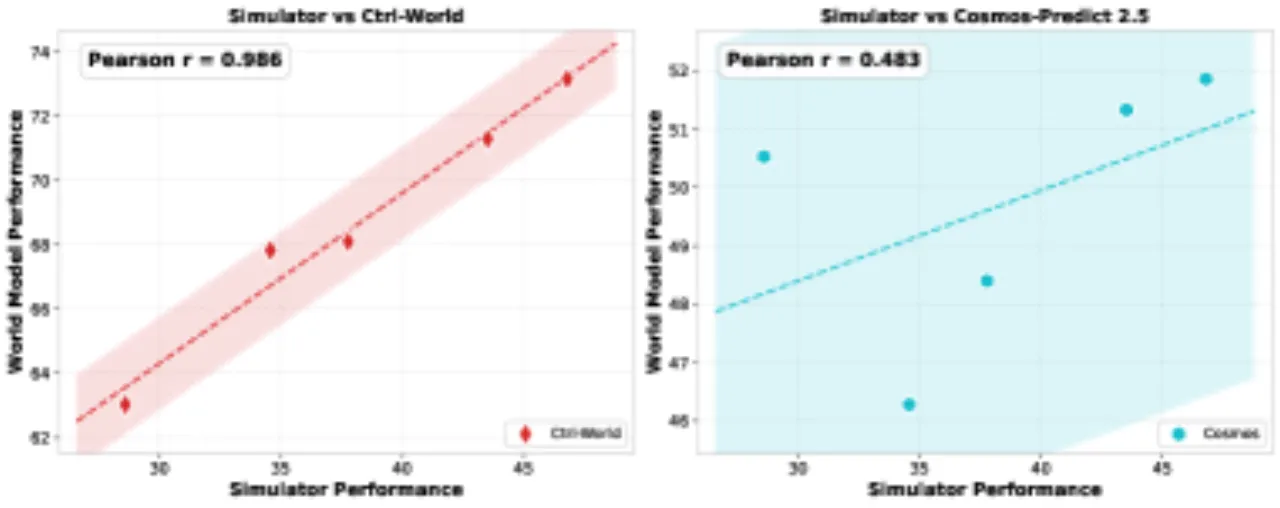
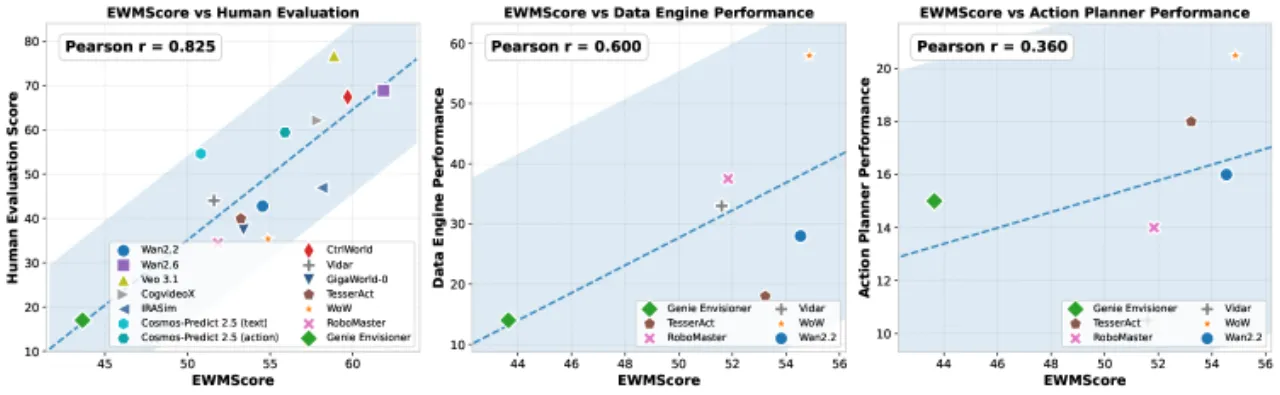
01 动机
现有具身世界模型评测存在三大核心问题:只关注视频生成质量(perceptual fidelity),忽略功能性(functional utility);单次评测覆盖模型数量少(通常不超过 10 个);缺乏统一框架将感知质量与下游任务效果关联起来。
"Current evaluation of embodied world models has largely focused on perceptual fidelity (e.g., video generation quality), overlooking the functional utility of these models in downstream decision-making tasks."
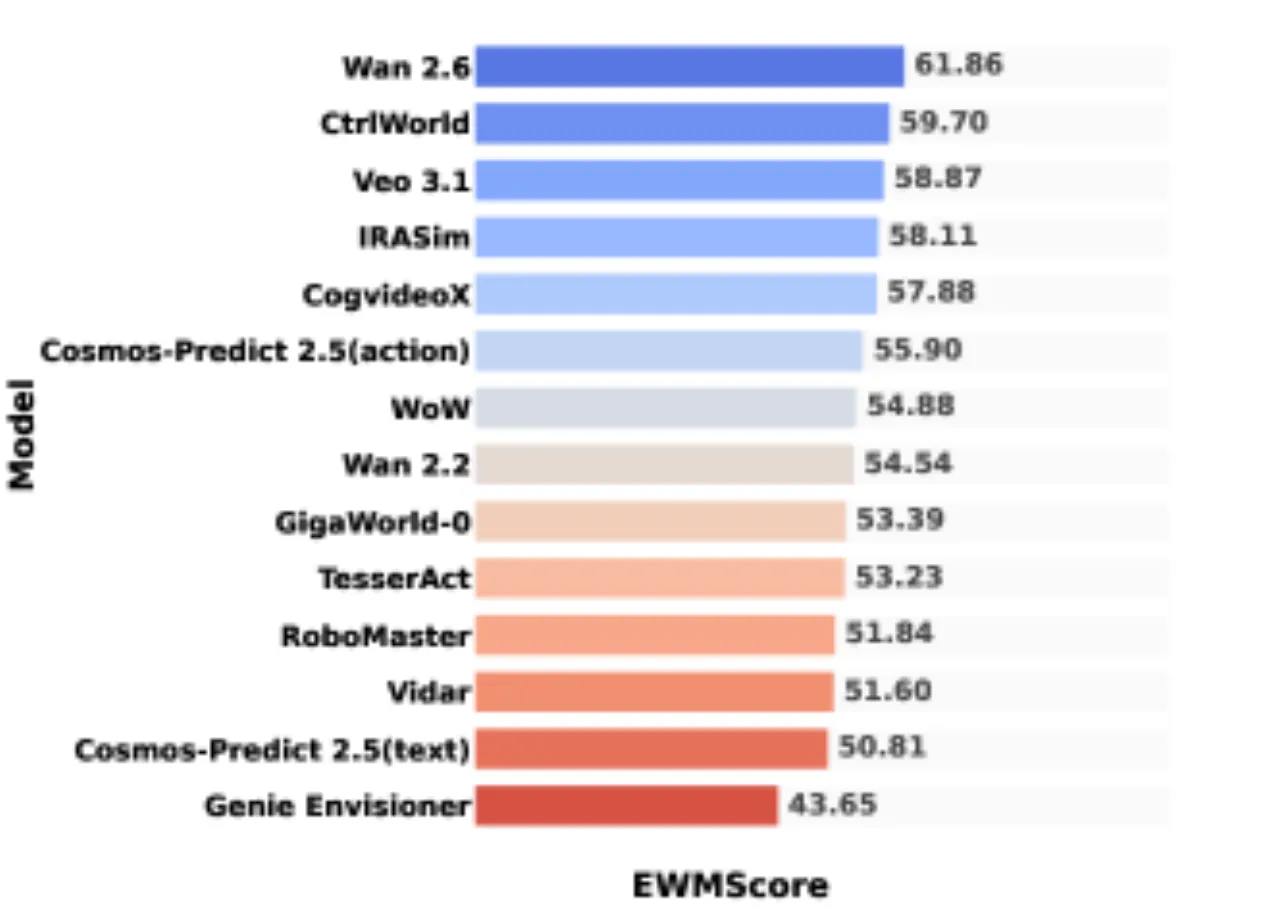
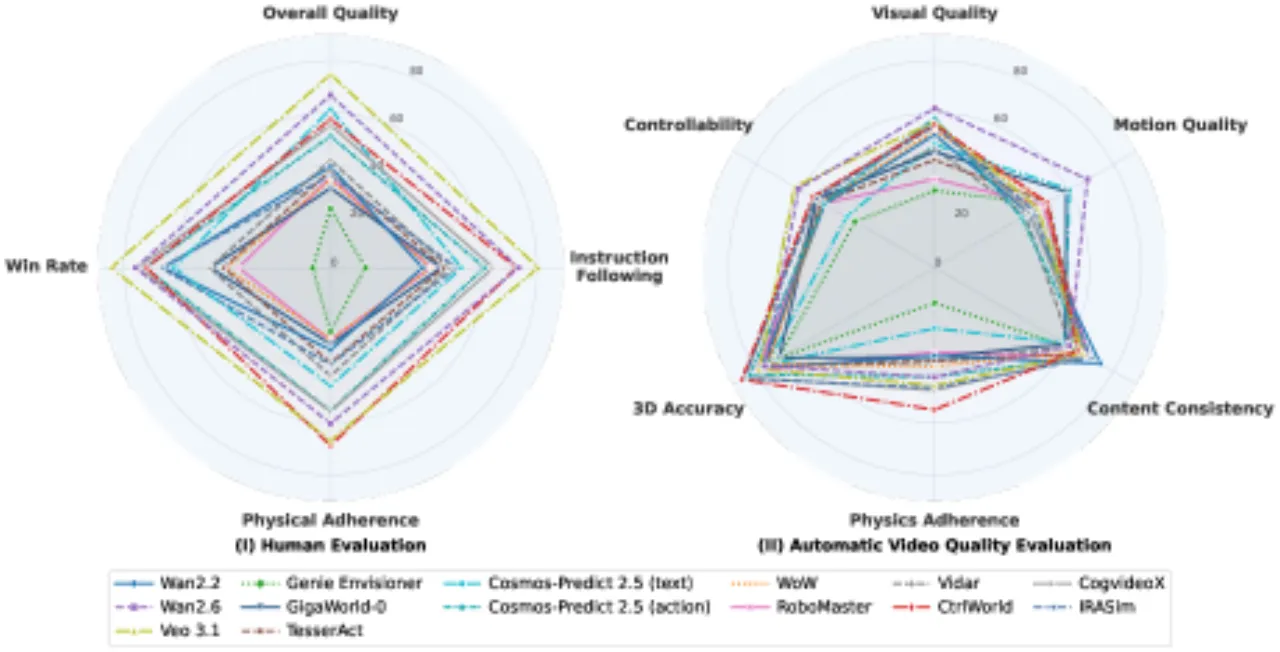
14被评测模型数量(通用 + 具身专用)
16视频质量自动化评测指标数量
0.825EWMScore 与人工评测相关系数 r
3,500人工标注视频数(70 位标注员)