01 动机
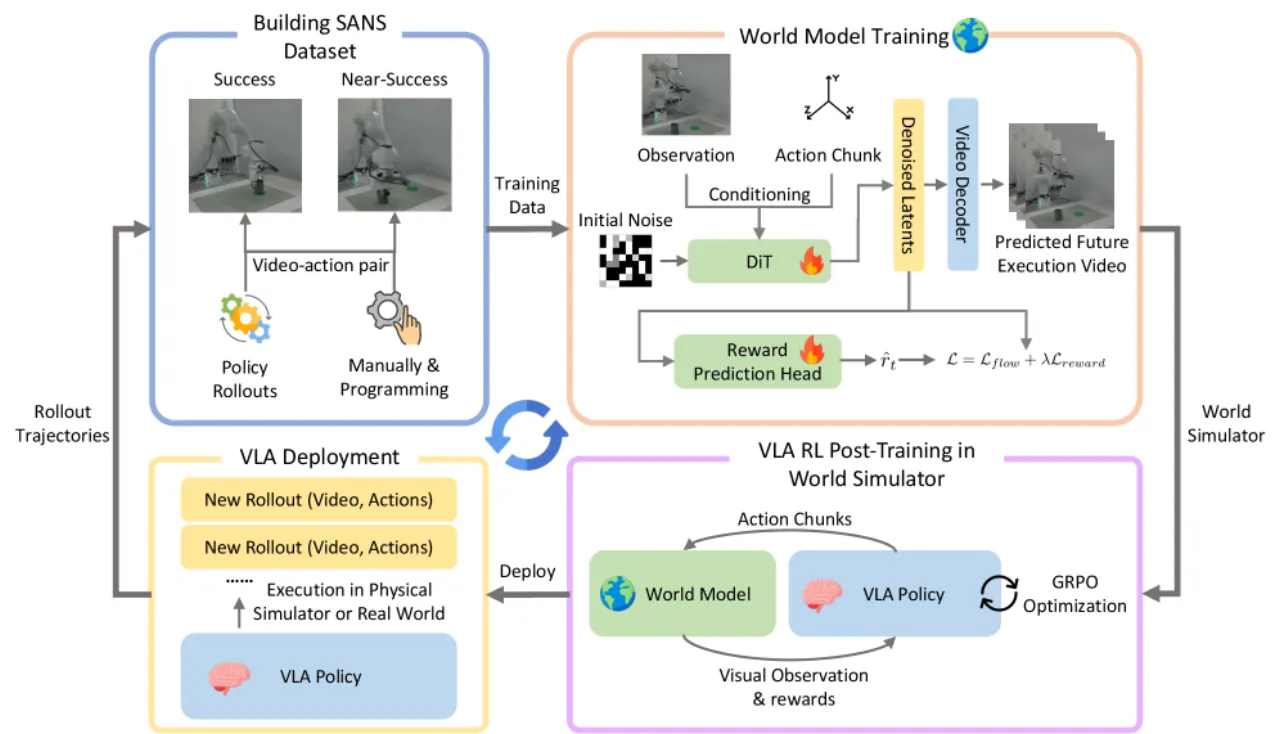
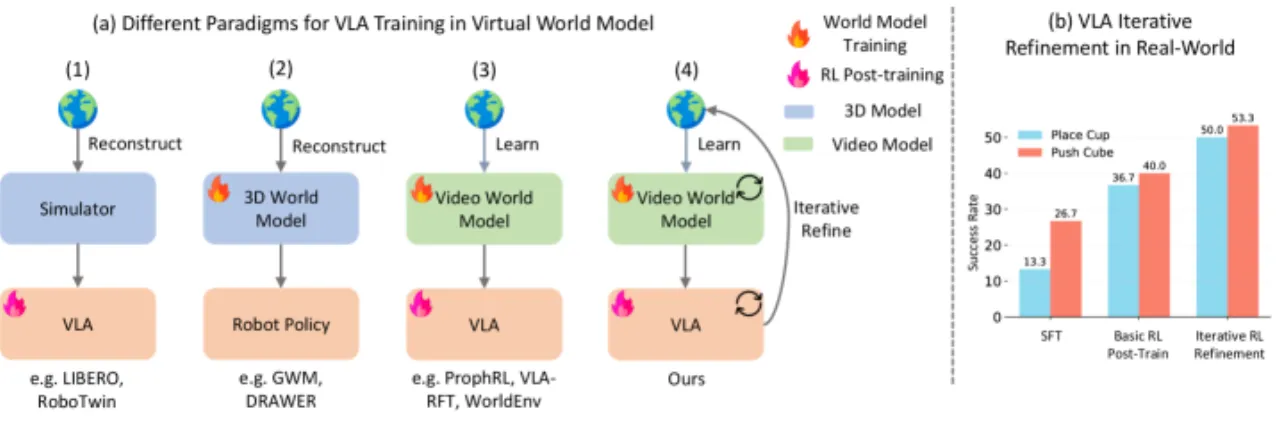
在真实物理环境中对VLA(Vision-Language-Action)策略进行强化学习,需要大量机器人交互,代价极高且存在安全风险。 视频世界模型作为虚拟环境是一条有吸引力的替代路径,但现有方案存在两个关键瓶颈,导致实际效果受限。
问题一:动作感知不精准
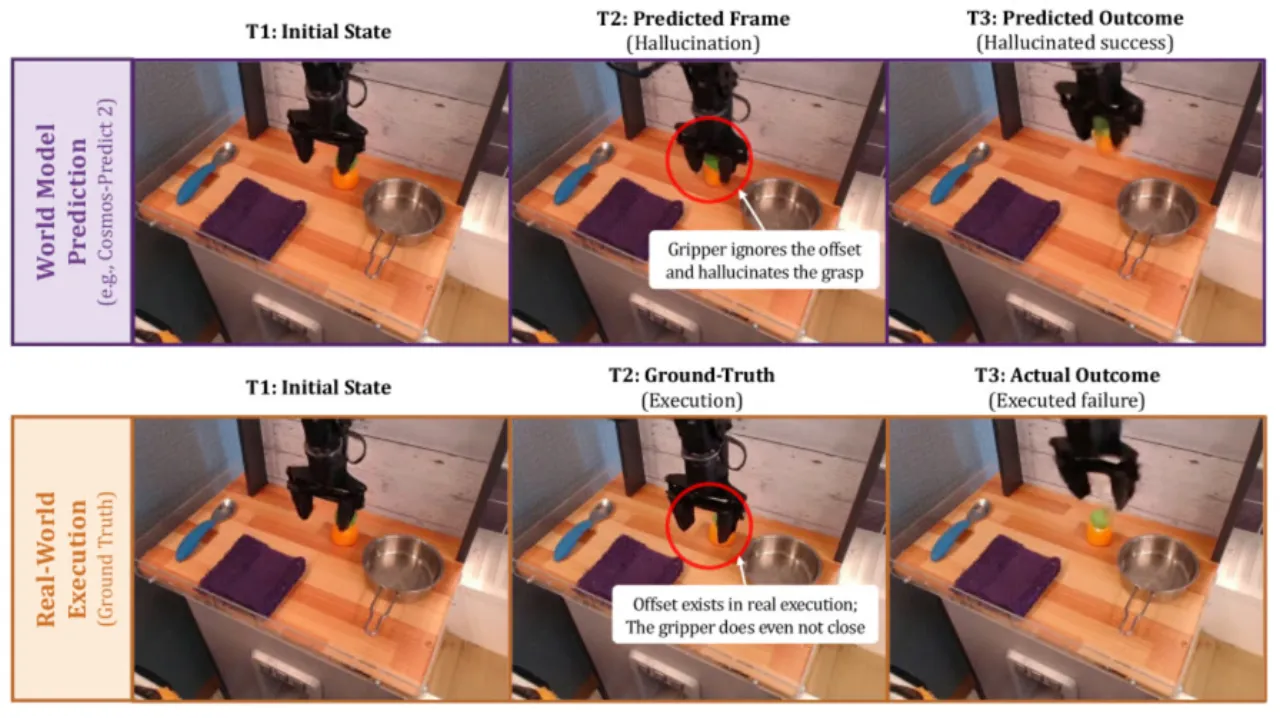
当机器人动作存在微小误差("近成功"情形,例如差一点就能抓到物体)时,现有视频世界模型 "frequently hallucinate successful outcomes even under erroneous actions, reflecting weak grounding in fine-grained physical dynamics"(论文原话)。 这意味着用于RL训练的虚拟rollout质量低,导致策略无法从失败中学习。
问题二:缺乏原生奖励信号
奖励需要通过另一个模块(如VLM)从生成的视频帧中提取。由于视频质量本身就存在幻觉, 计算出来的奖励信号不可靠,策略优化方向失真。 此外,随着VLA策略在RL训练中不断改进,其失败模式也随之改变,固定的世界模型无法跟上,造成分布偏移。
"Current video generation-based world models, when used as RL environments for VLA policies, struggle with two critical limitations: imprecise action-following, especially in near-success failure cases, and the absence of a reliable native reward signal."
+24.0%LIBERO-Object 成功率提升
+10.0%LIBERO-Spatial 成功率提升
+23.4%真实场景 Pick Cup 提升
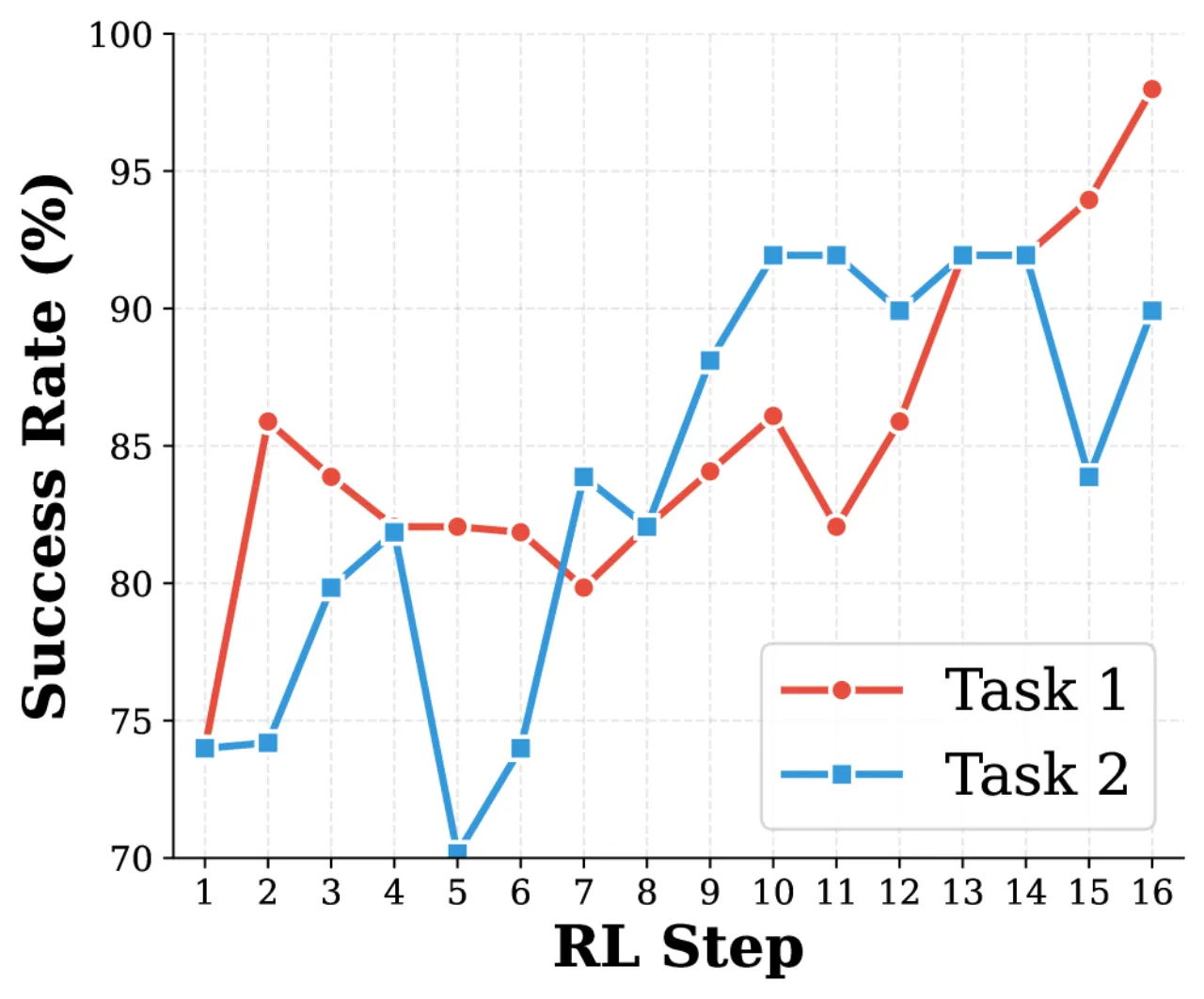
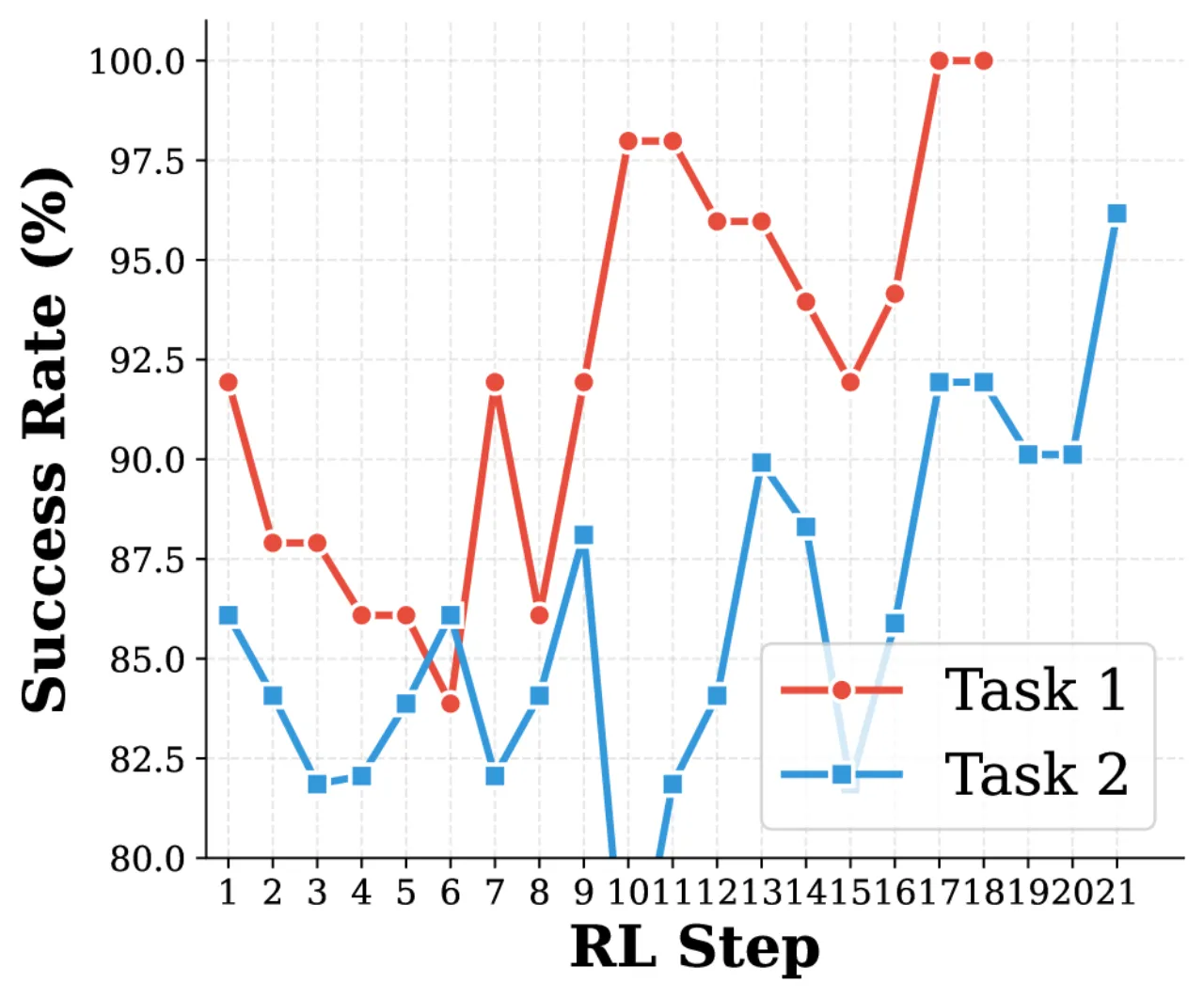
+13.3%第二次迭代额外相对提升