01 动机
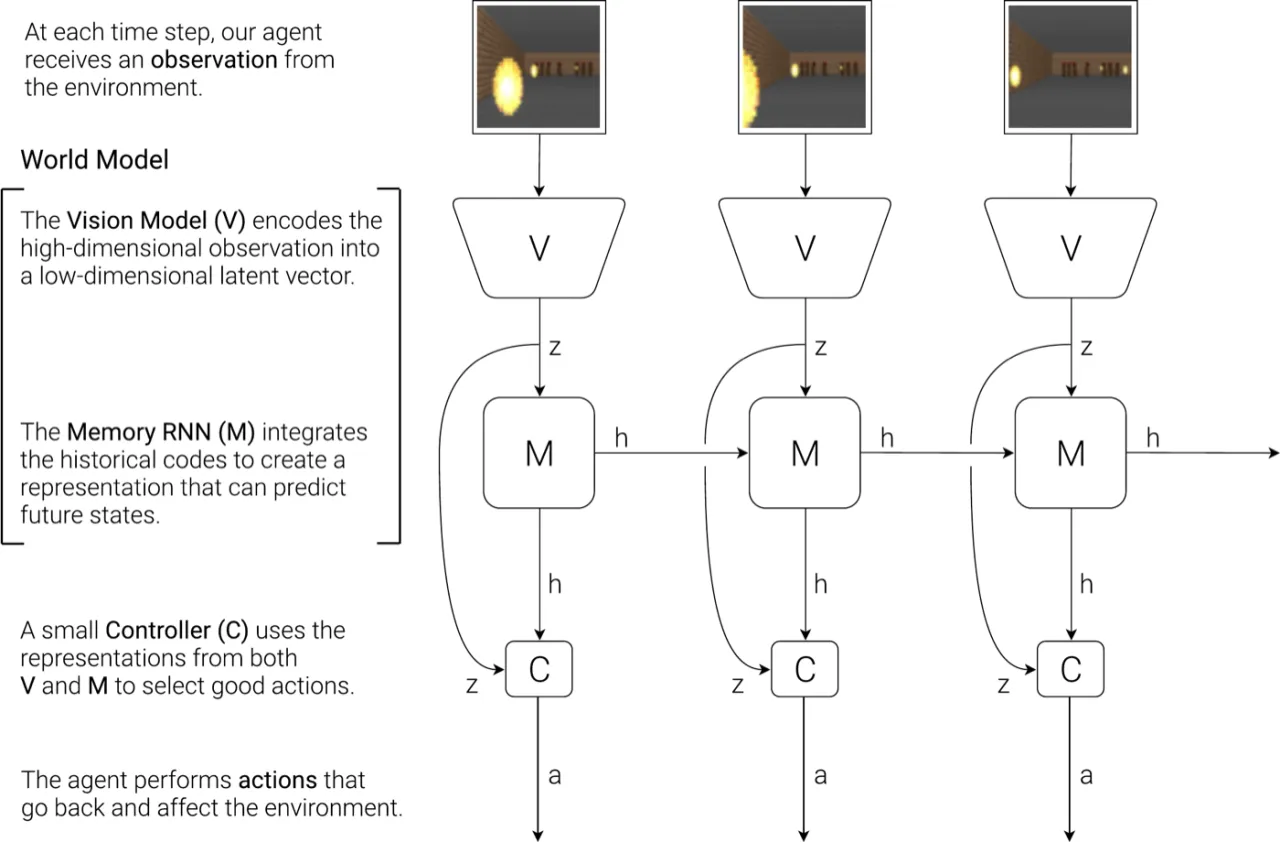
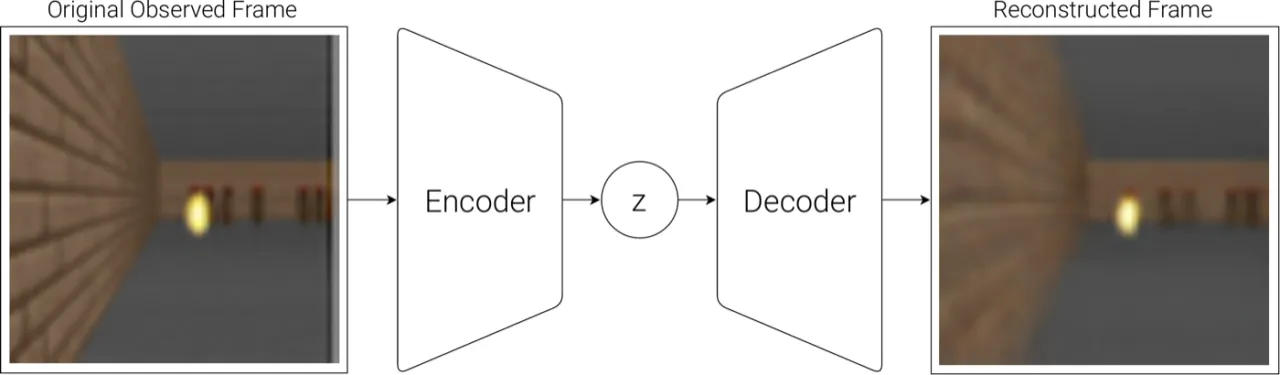
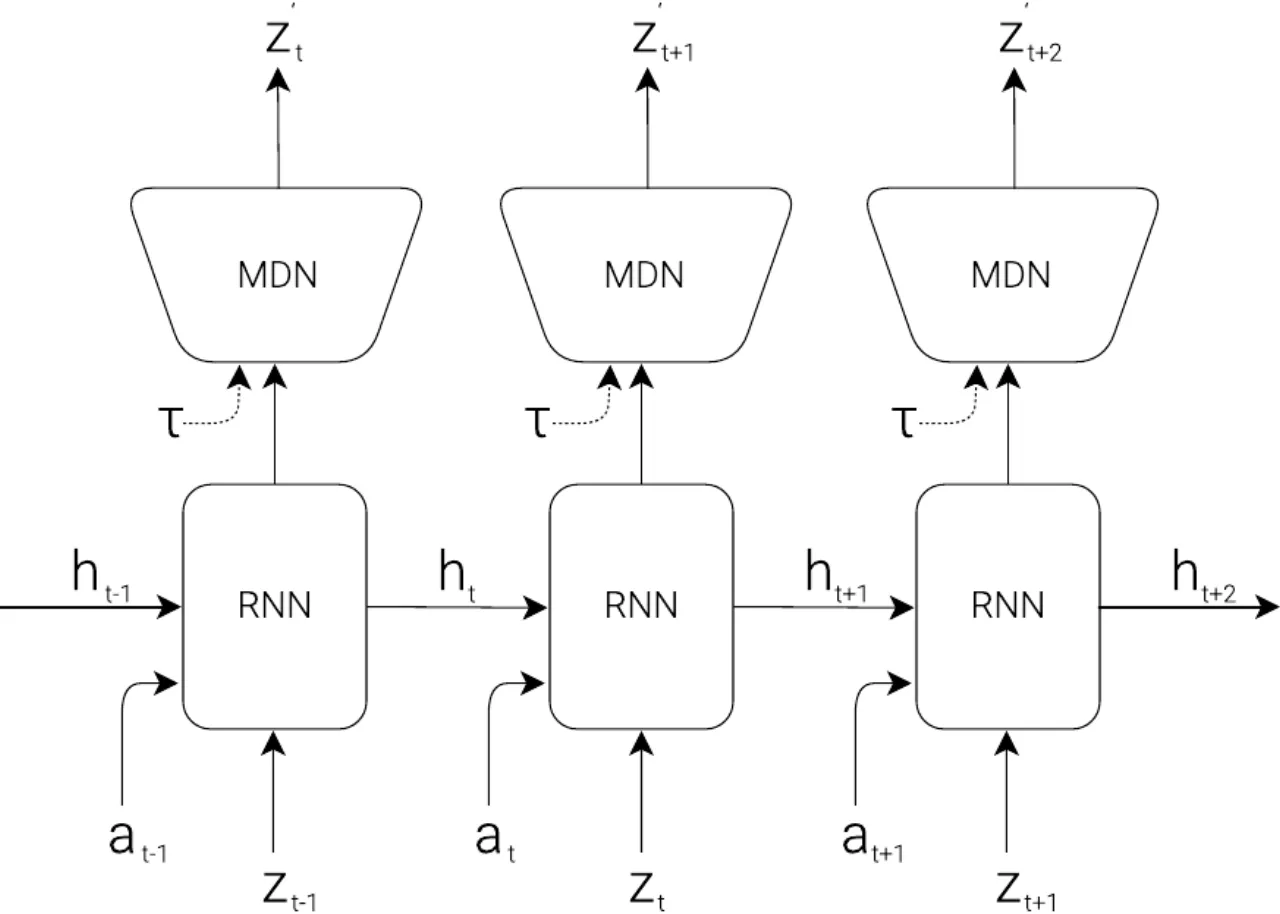
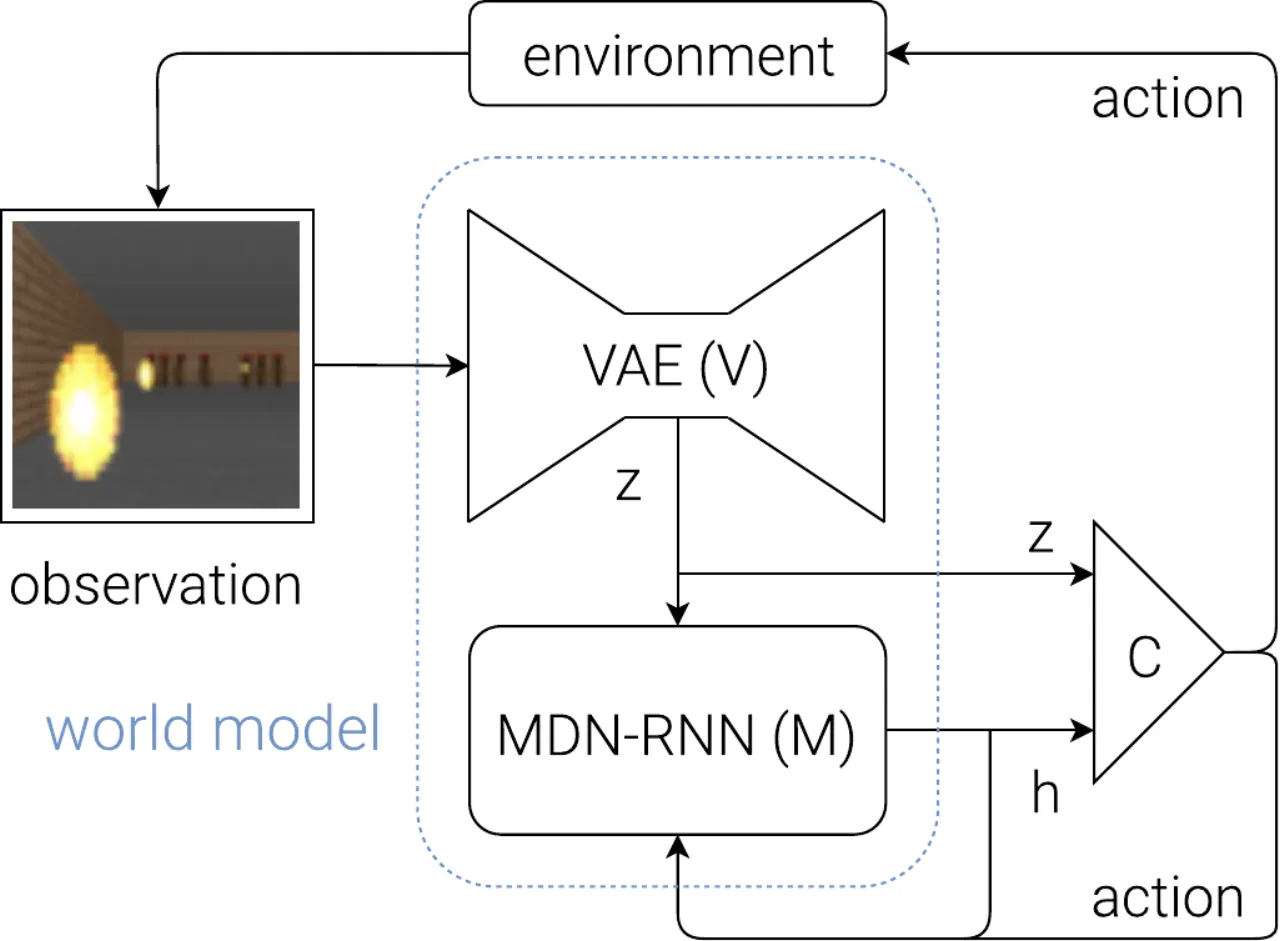
现实中的 model-free 强化学习方法通常只使用参数量较少的小型网络, 因为信用分配问题(credit assignment problem)使得在百万参数量的大模型上进行直接 RL 训练极为困难。 人类依靠内部"心理模型"(mental model)做出快速决策,无需在脑中显式规划所有未来情景—— 本文受此启发,构建能预测未来的世界模型,并以此为"舞台"训练极简的控制策略。
"We explore building generative neural network models of popular reinforcement learning environments. Our world model can be trained quickly in an unsupervised manner to learn a compressed spatial and temporal representation of the environment. By using features extracted from the world model as inputs to an agent, we can train a very compact and simple policy that can solve the required task. We can even train our agent entirely inside of its own hallucinated dream generated by its world model, and transfer this policy back into the actual environment."

906±21CarRacing-v0 最终得分(满分 900 为 "solved")
1092±556VizDoom Take Cover 最佳生存步数(τ=1.15)
867Controller 参数量(线性层,极度紧凑)
10,000初始随机 rollouts 用于训练世界模型