01 动机
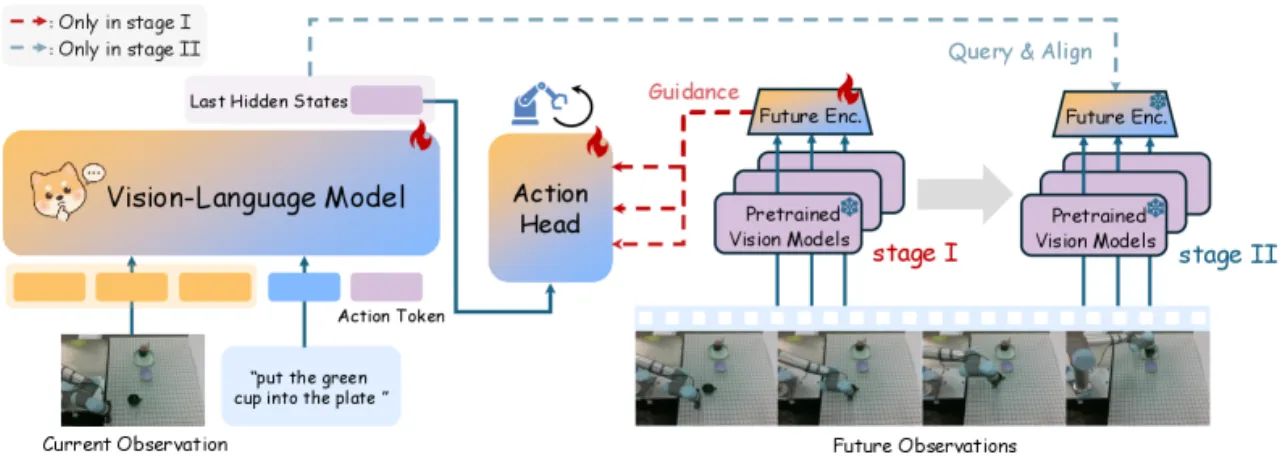
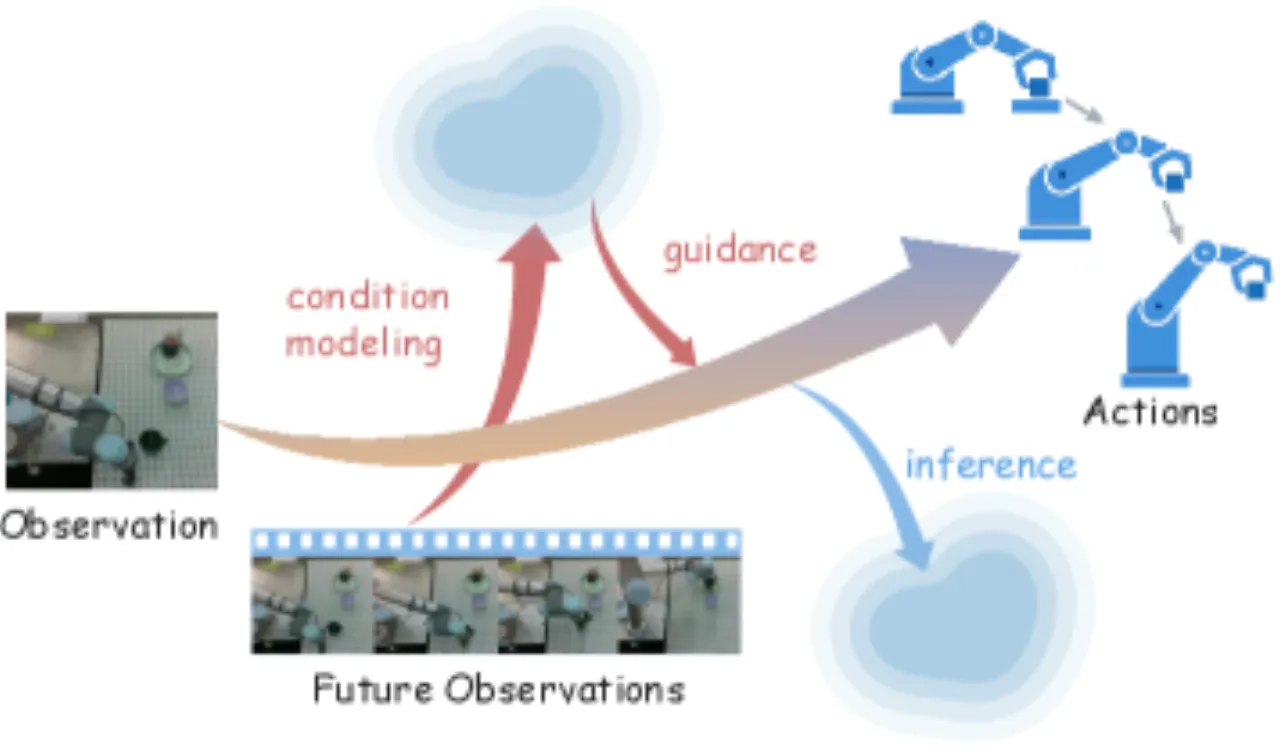
现有 VLA 模型在"未来预测"与"精细动作生成"之间存在根本矛盾:World Action Models 显式预测未来图像/视频,信息冗余大,难以应用于现实操控;Latent Action Models 将未来压缩为稀疏隐变量,精度不足,无法支撑需要厘米级控制的任务。
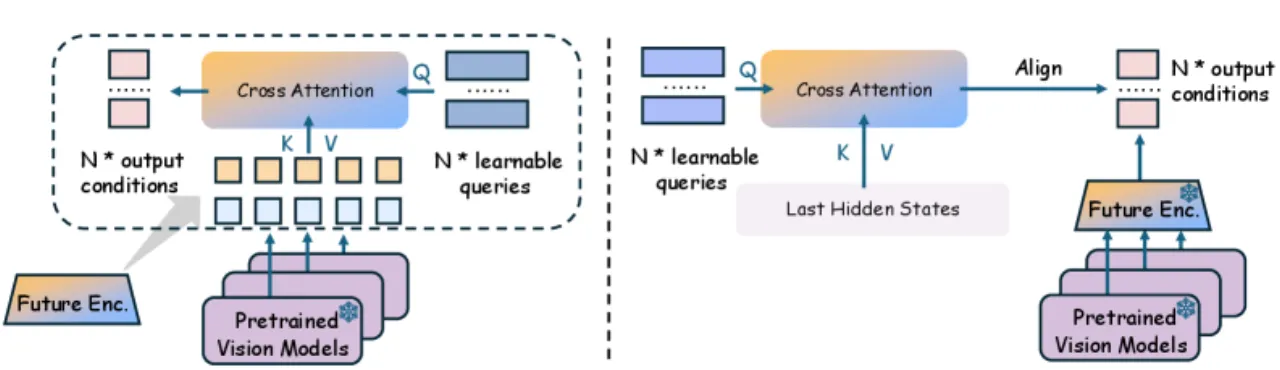
"WoG maps future observations into compact conditions by injecting them into the action inference pipeline." ——论文摘要
78.0%Google Robot 平均成功率(WoG vs. 59.2% Moto)
63.5%WidowX 平均成功率(WoG vs. 62.5% ViPRA)
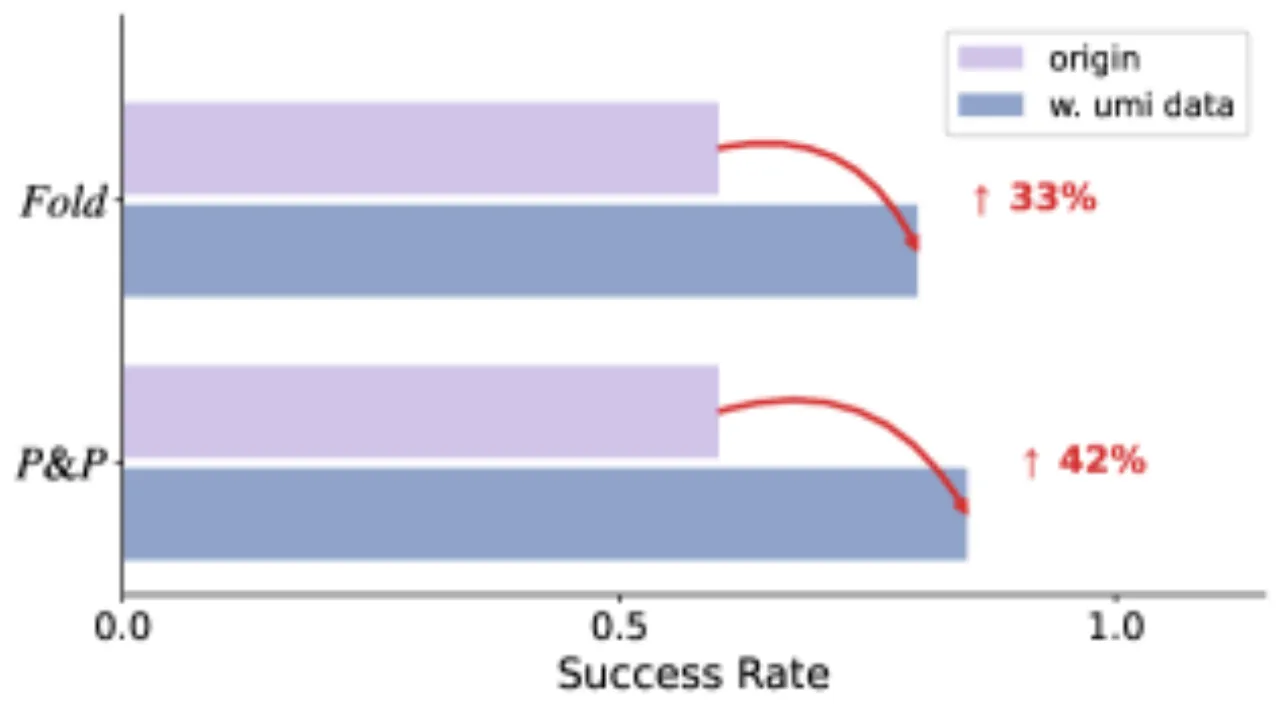
+42%引入 UMI 人类数据后 Pick & Place 提升
+33%引入 UMI 人类数据后 Fold Towel 提升