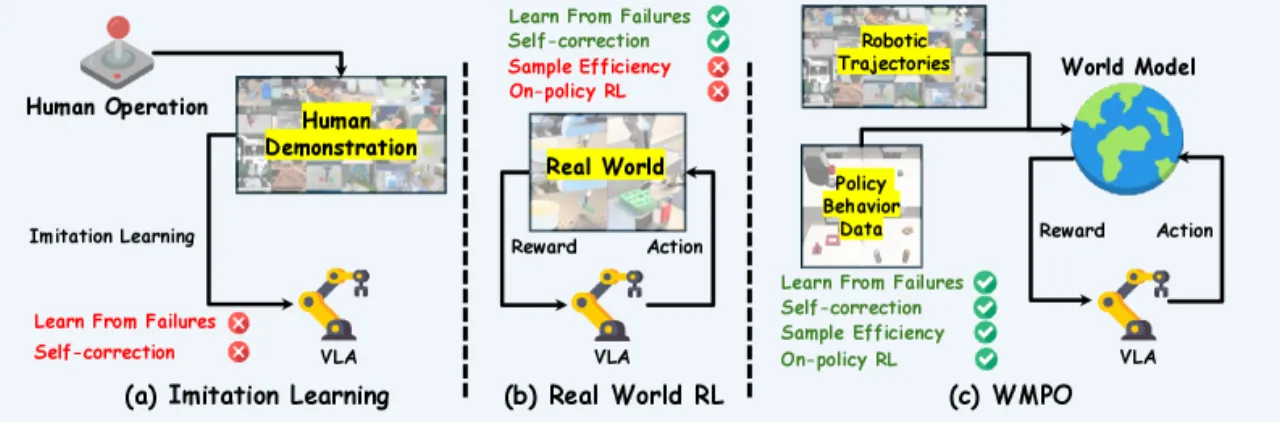
02 方法WMPO 框架由三个核心模块组成:像素级视频世界模型、轻量级 reward model 和基于 GRPO 的 on-policy 策略优化。整体思路是让 policy 在世界模型生成的"想象轨迹"中进行 on-policy 更新,从而规避真实机器人交互的高成本。
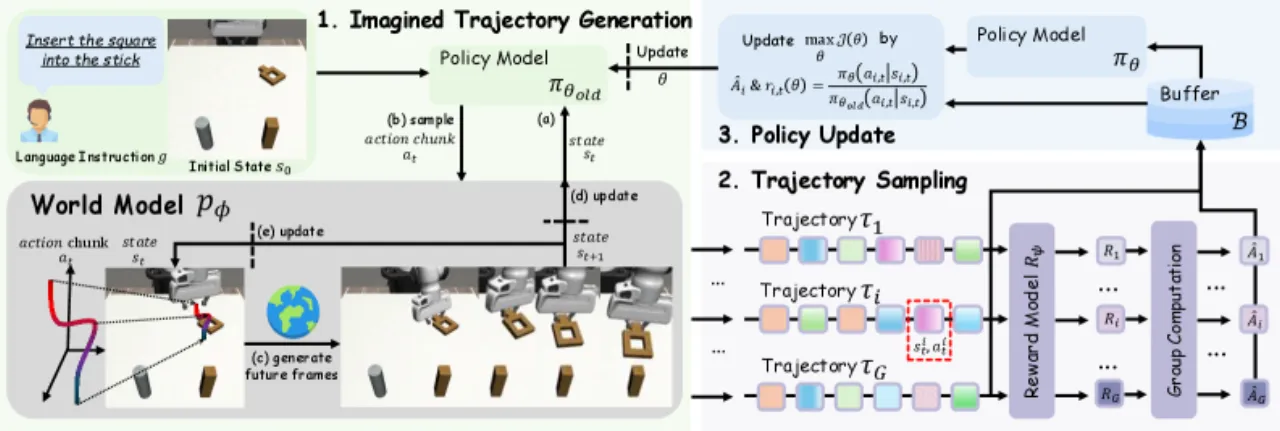
图 2:WMPO 整体训练流程。从初始状态 s₀ 出发,世界模型生成 G 条想象轨迹;reward model 对每条轨迹评分;GRPO 计算 normalized advantage 并更新 VLA policy。三个组件交替迭代,实现 on-policy 的自我提升。
像素级视频世界模型(Pixel-Space World Model)
与常见的 latent world model 不同,WMPO 采用像素级预测,使"想象"轨迹与 VLA 预训练特征(基于海量网络图像)保持对齐。世界模型基于 video diffusion 架构:将 OpenSora 的 3D VAE 替换为来自 SDXL 的 2D VAE,以更好地保留运动细节。模型首先在 Open X-Embodiment(OXE)数据集上预训练,再通过 Policy Behavior Alignment 在策略自身采集的真实轨迹上微调,以解决 state-distribution mismatch 问题——确保模型能准确模拟当前 policy 产生的失败模式。两项技术增强保证了质量:(1) Noisy-frame conditioning :条件帧加入 50/1000 步扩散噪声,增强鲁棒性;(2) Frame-level action control :通过扩展的 AdaLN block 实现精确的动作-帧对齐,支持 clip-level 自回归视频生成。
轻量级 Reward Model
Reward model 在真实轨迹上训练,以二元信号(成功/失败)预测任务完成情况,为 GRPO 提供 sparse reward 信号。在所有仿真任务上的 F1 score 均超过 0.95,确保了训练信号的可靠性。
On-Policy GRPO 策略优化
WMPO 采用 Group Relative Policy Optimization(GRPO)进行 on-policy 学习。对每个初始状态采样 G 条想象轨迹,reward model 评分后计算 normalized advantage,再通过 clipped policy gradient 更新 policy:
𝒥(θ) = 𝔼[1/G ∑ min(r_i,t(θ) Â_i, clip(r_i,t(θ), 1−ε_low, 1+ε_high) Â_i)]
为保证有效学习,采用 dynamic sampling 策略:丢弃结果完全一致(全成功或全失败)的 group,确保每个 batch 包含成功与失败轨迹的混合,从而产生有意义的梯度信号。VLA backbone 为 OpenVLA-OFT,动作空间离散化为每维度 256 个 bin。
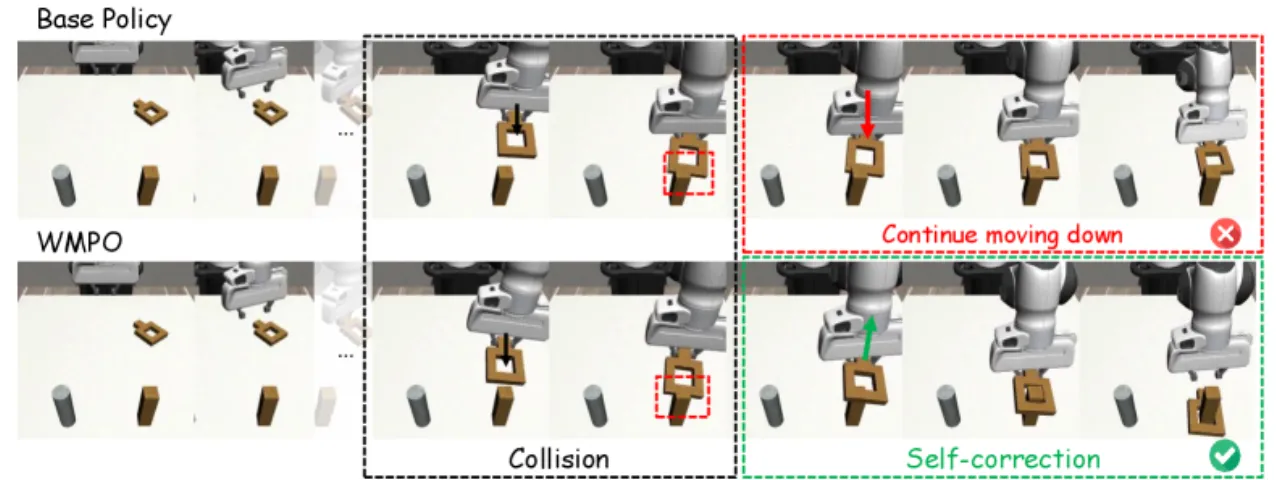
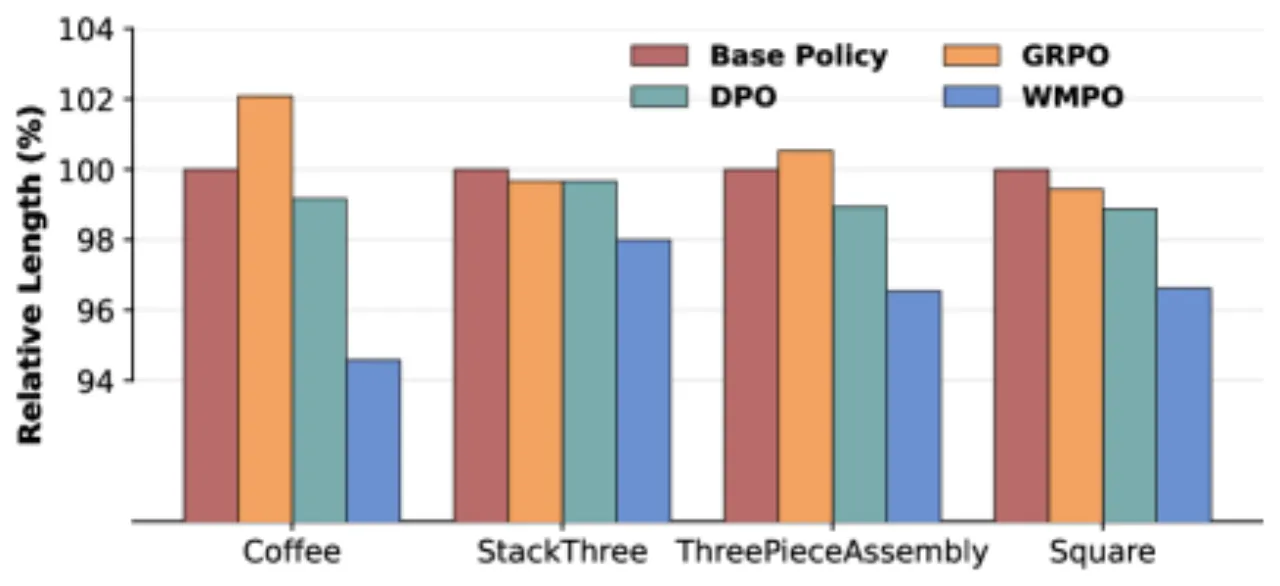
图 3:Square 任务中 WMPO 的自我纠错能力分析。WMPO 在遭遇失败后能主动调整策略、恢复到正确轨迹,而 base policy 和 DPO 则无法做到。