01 动机
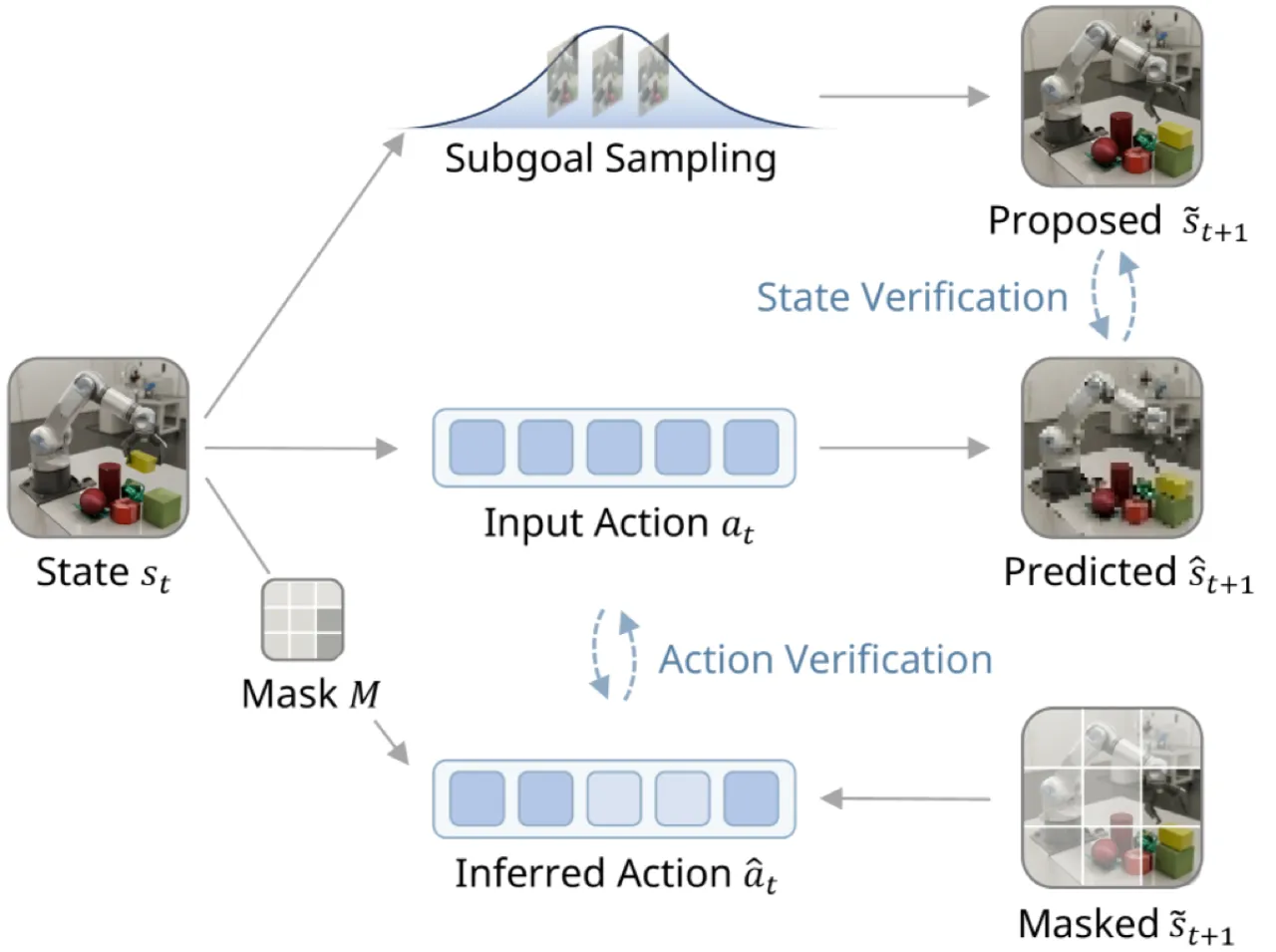
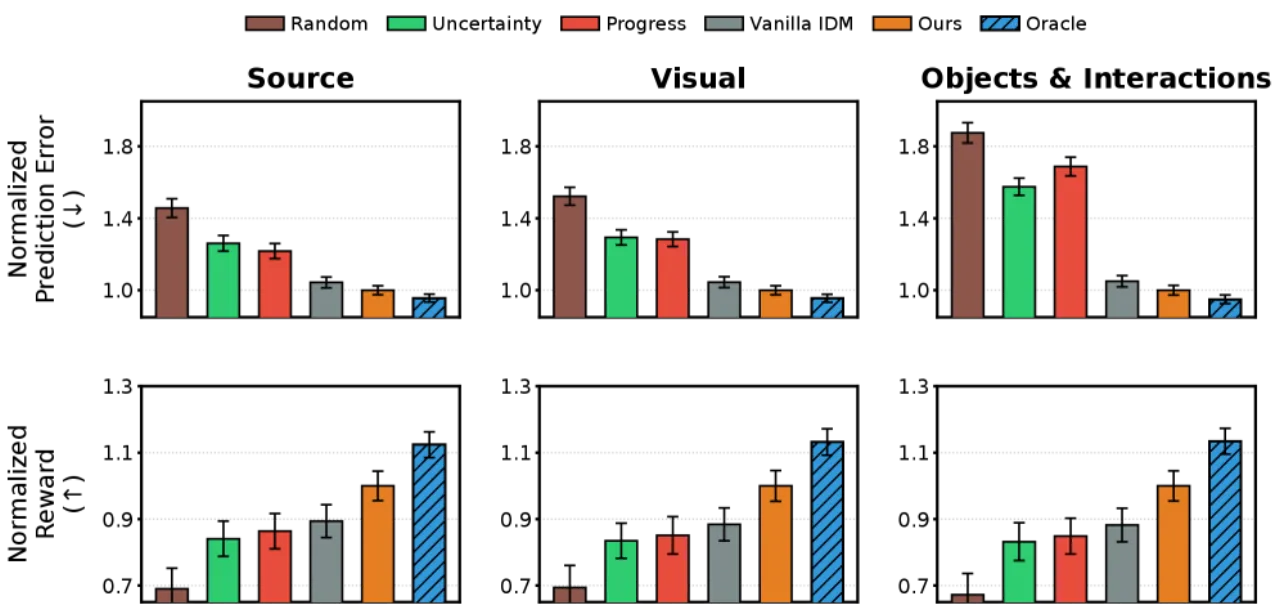
通用世界模型要在策略学习中发挥作用,必须在包括次优动作和探索性动作在内的多样动作分布下稳定准确地预测结果。然而,现有方法在探索不足的状态区域难以识别哪些 transition 最具信息量,验证(verification)机制的缺失导致模型在分布外(OOD)场景下显著退化。
"General-purpose world models promise scalable policy evaluation, optimization, and planning, yet achieving the required level of robustness remains challenging."
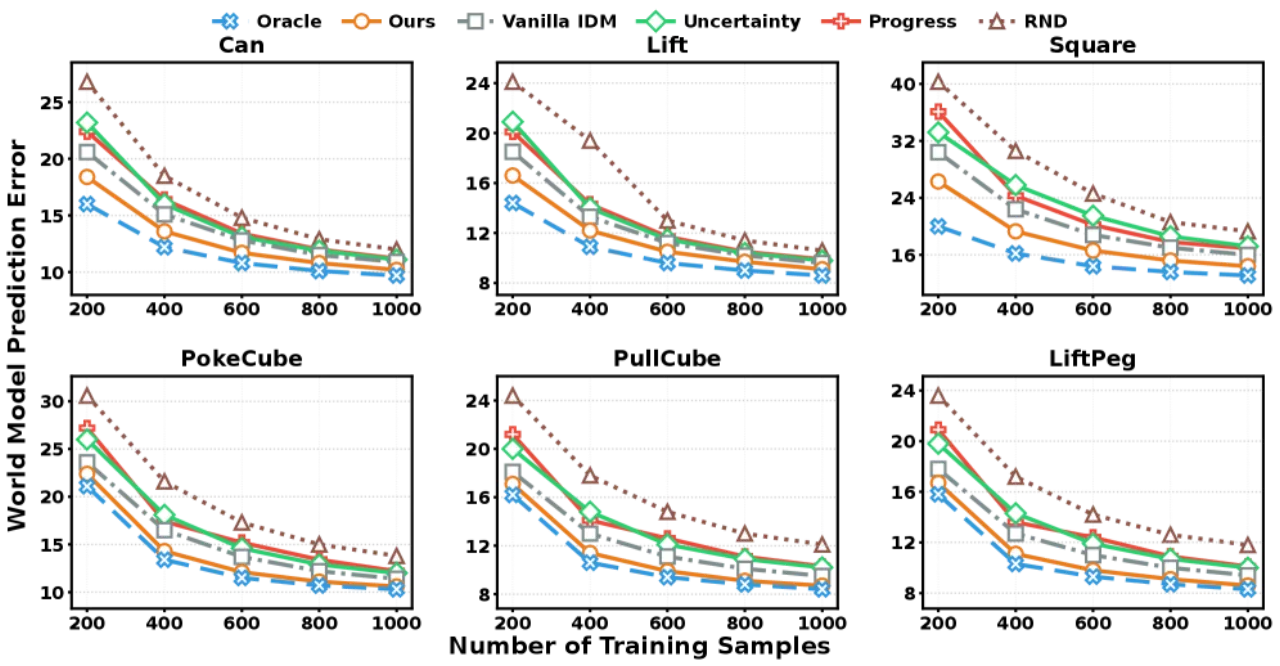
2×采样效率提升(sample efficiency)
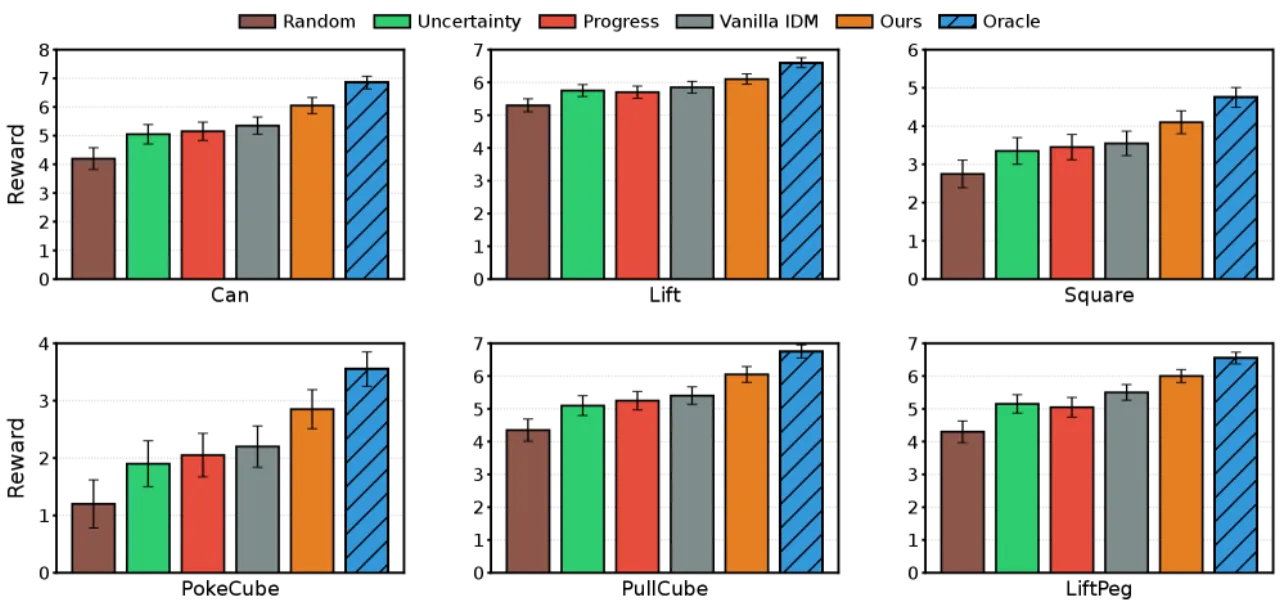
>22%下游策略性能提升
9涵盖任务数
3评测平台(MiniGrid / RoboMimic / ManiSkill)
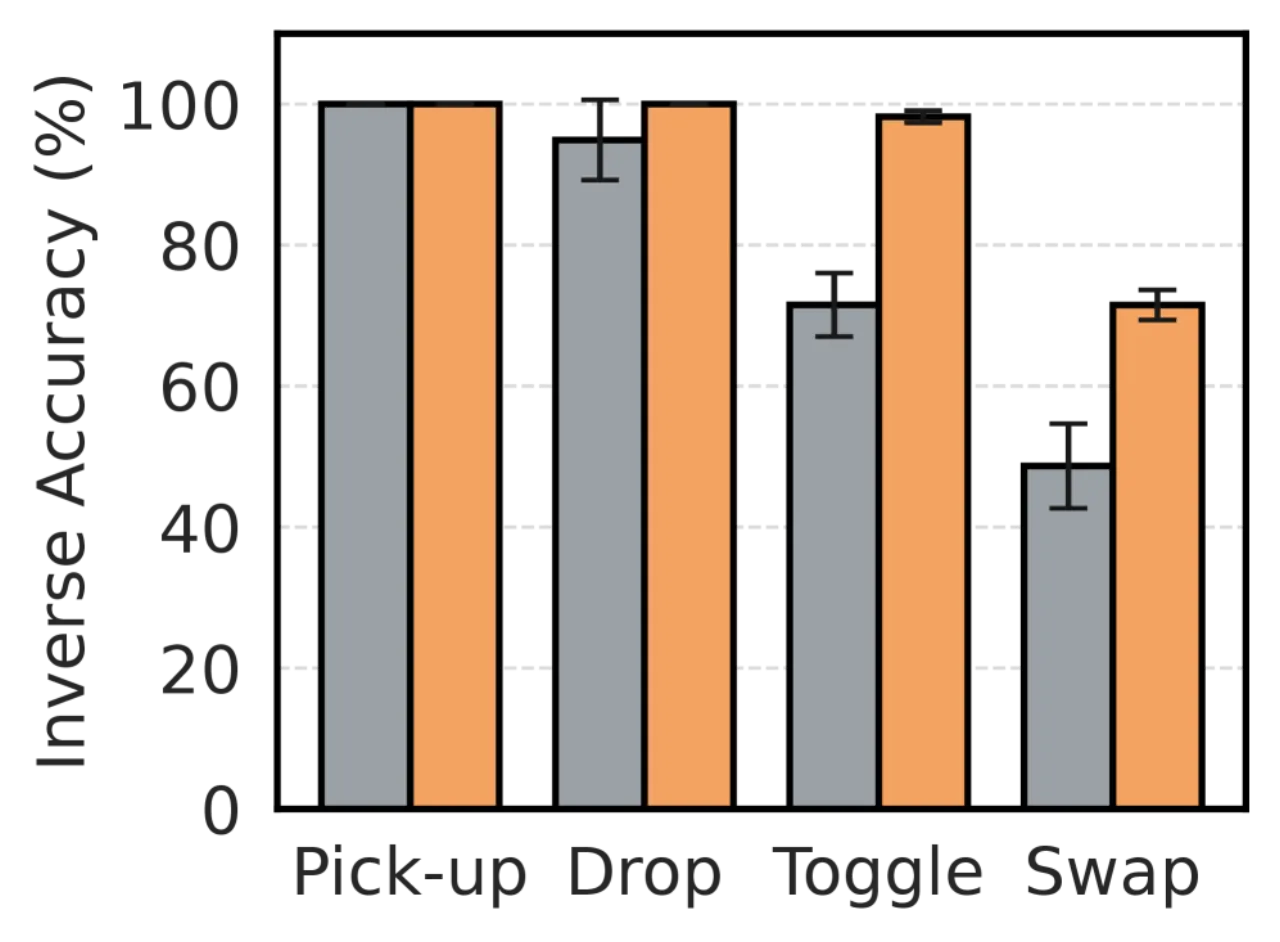
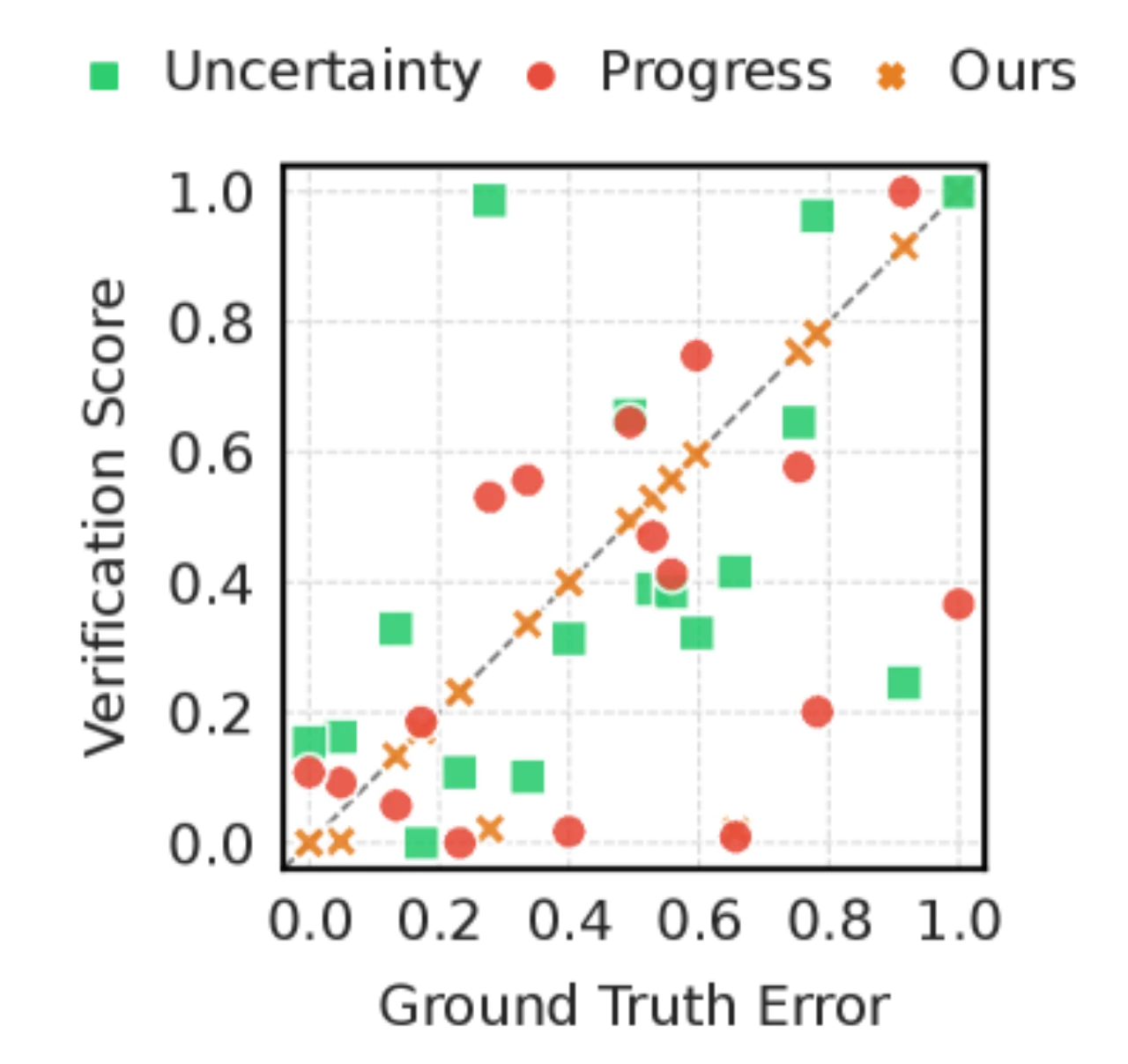
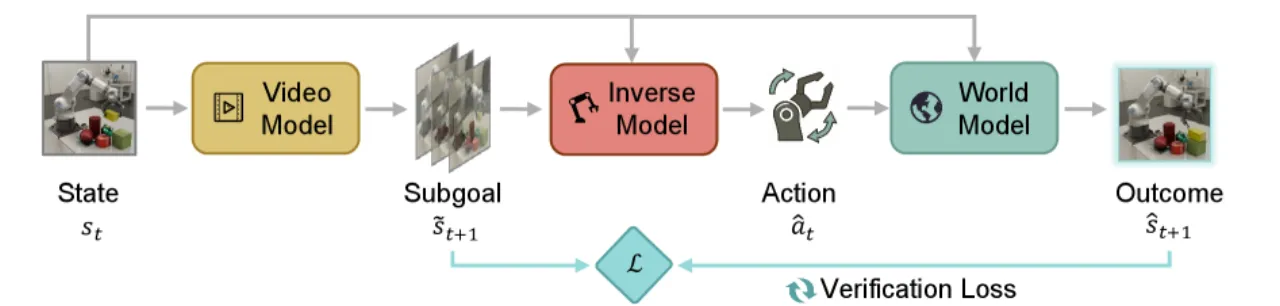
核心洞察:已知起止状态时,推断引发合理 transition 的动作(逆问题)往往比直接预测状态转移结果(前向问题)更容易。这种不对称性来源于:① 无动作视频数据远比带动作的交互数据丰富;② 动作相关特征的维度 d_z 远小于完整状态维度 d_s。WAV 正是利用这一不对称性构建高效的预测验证机制。