01 动机
VLA 策略已在多种机器人任务上取得突出成果,但受训练数据范围限制,面对视觉和语言扰动时表现出明显的脆弱性。世界模型(World Models)被寄望于通过对未来视觉状态的显式预测来弥补这一缺陷,这类以世界模型为基础的策略被称为 World Action Model(WAM)。然而,WAM 相比 VLA 究竟是否真正拥有更强的泛化能力,此前缺乏系统性的实证研究。
"We conduct a comparative study of prominent state-of-the-art VLA policies and recently released WAMs. We evaluate their performance on the LIBERO-Plus and RoboTwin 2.0-Plus benchmarks under various visual and language perturbations."

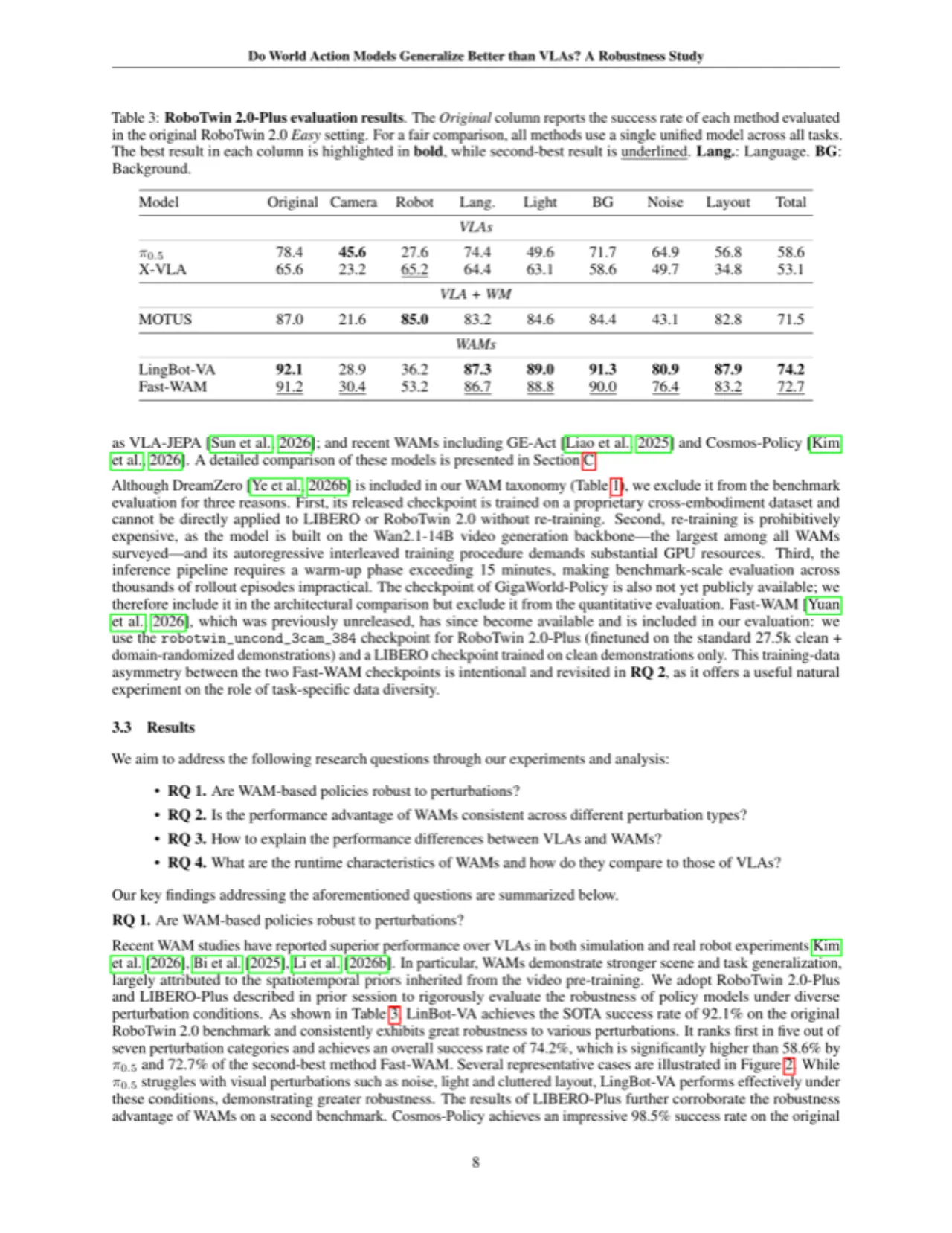
74.2%LingBot-VA 在 RoboTwin 2.0-Plus 的综合成功率(所有扰动平均)
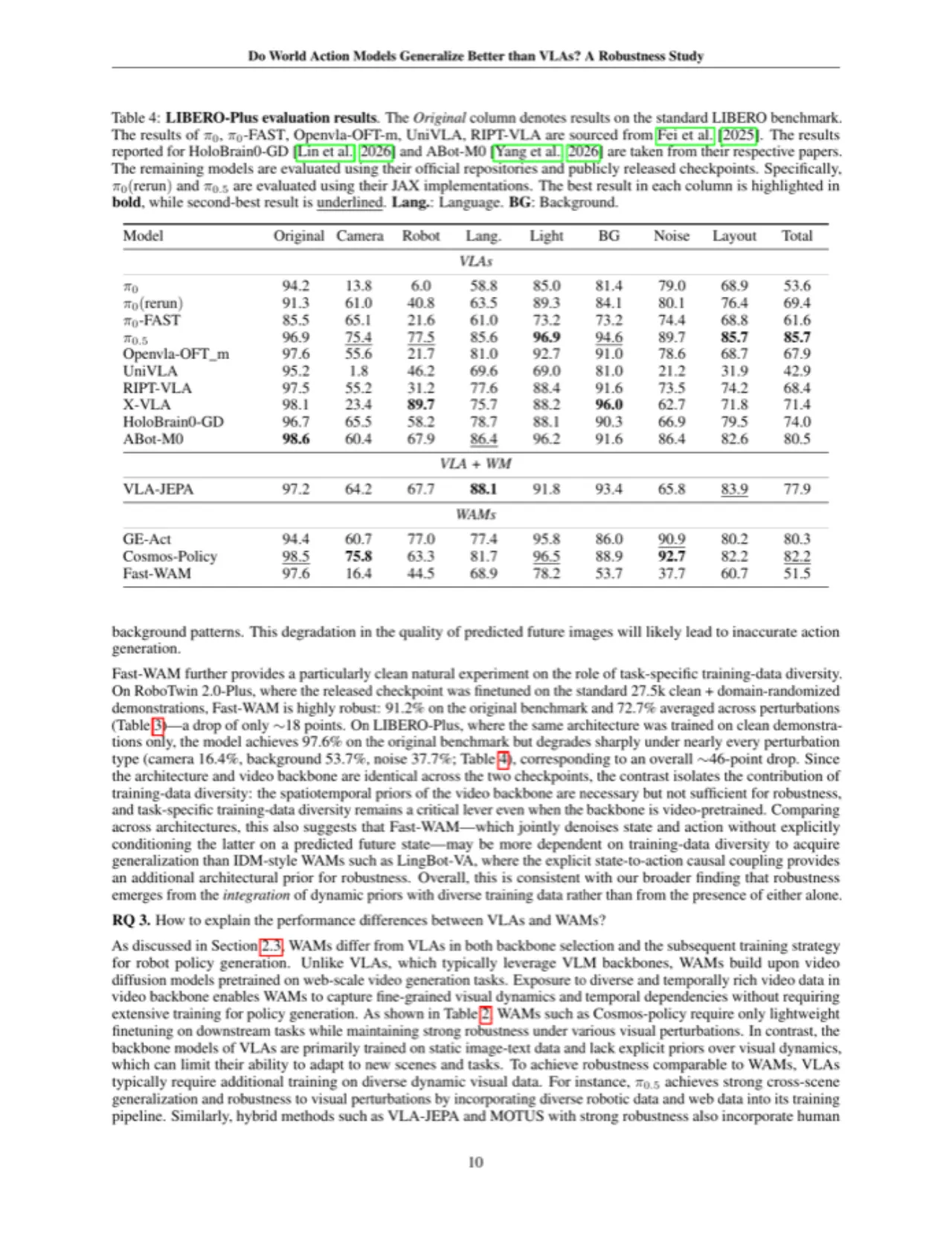
82.2%Cosmos-Policy 在 LIBERO-Plus 的综合成功率(所有扰动平均)
4.8×WAM 推理延迟相较于 π0.5 的最低倍数(GE-Act vs π0.5)
7类扰动维度:摄像机、机器人、语言、光照、背景、噪声、布局
核心问题
本研究聚焦于以下四个研究问题:
- RQ 1. 基于 WAM 的策略对扰动是否具有鲁棒性?
- RQ 2. WAM 的性能优势是否在不同扰动类型上保持一致?
- RQ 3. 如何解释 VLA 与 WAM 之间的性能差异?
- RQ 4. WAM 的推理速度特性如何,与 VLA 相比差距有多大?