VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
用大语言模型组合 3D 价值图,零样本合成机器人操控轨迹
Wenlong Huang · Chen Wang · Ruohan Zhang · Yunzhu Li · Jiajun Wu · Li Fei-Fei | Stanford University & UIUC
VoxPoser 利用大语言模型(LLM)的代码生成能力,通过调用视觉语言模型(VLM)在三维观测空间中组合语言条件的 affordance/avoidance value maps,再由运动规划器将 value map 作为目标函数,零样本合成六自由度闭环机器人轨迹。系统无需额外训练,可泛化至开集语言指令与开集物体。
"Despite the progress, most still rely on pre-defined motion primitives to carry out the physical interactions with the environment, which remains a major bottleneck."
VoxPoser 提出的核心洞察是:LLM 擅长推理 affordances(目标区域)与 constraints(避障约束),且它的代码生成能力可以直接调用感知 API,在三维体素空间中构建稠密的 value map,将抽象的语言知识锚定在机器人可感知的观测空间中,从而完全绕过手工设计的 primitives。
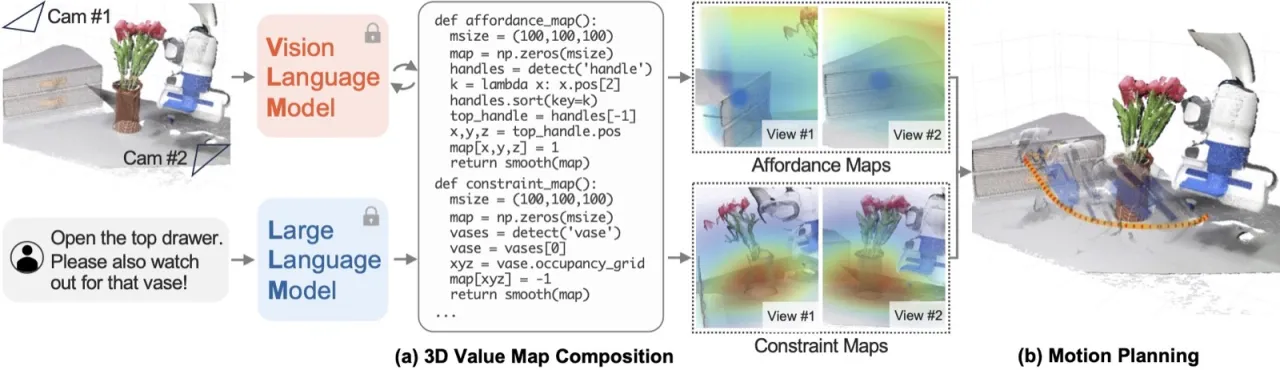
图 1(论文 Figure 1):VoxPoser 概览。LLM 从自然语言指令中提取 affordances 与 constraints,通过 VLM 将其落地为 3D value map,运动规划器以 value map 为目标函数直接合成机器人轨迹,覆盖"挂毛巾""关抽屉""分类垃圾"等多种日常操作任务,且无需针对特定任务或 LLM 进行额外训练。
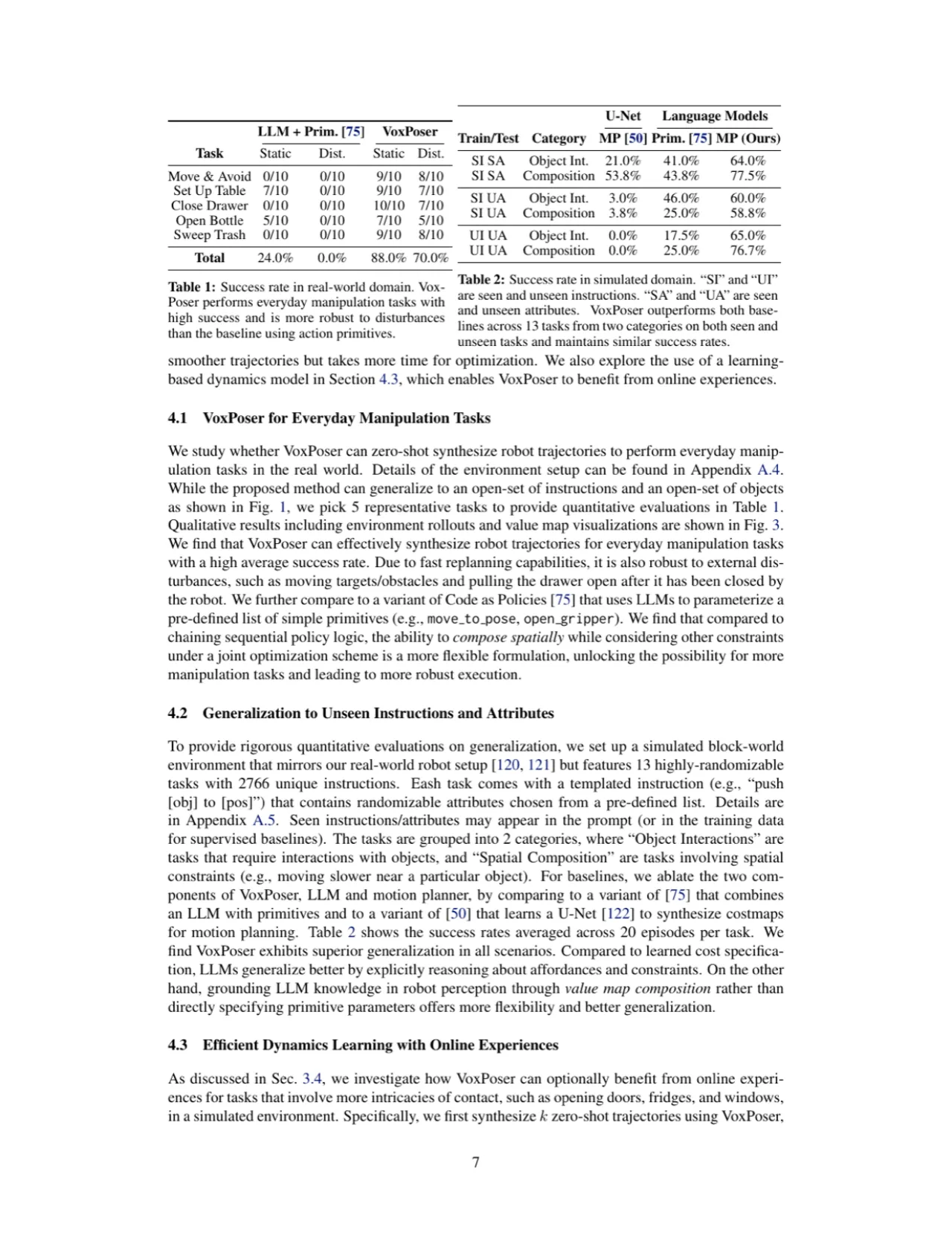
88%真实机器人静态场景成功率(5 类任务)
70%动态扰动下真实机器人成功率
13仿真评估任务数(SAPIEN 环境)
2,766仿真评估中唯一指令数量
02 方法
VoxPoser 将语言指令映射为 3D value map,再由运动规划器合成轨迹。整个流程由 LLM 生成 Python 代码驱动,无需任何额外训练。
方法流程图(来自项目主页):(a) LLM 生成代码,调用 VLM 获取物体感知信息,组合多种类型的 3D value map;(b) 运动规划器以 value map 为目标函数,通过 greedy search 合成 6-DoF 轨迹,并以 5 Hz 频率闭环重规划。
对于推门、开冰箱等 contact-rich 任务,零样本轨迹作为探索先验,驱动对环境动力学模型(平面推动模型:接触点、推动方向与距离)的高效在线学习,并用 MPC + random shooting 优化动作参数。
论文 Figure 2:详细流程示例——给定指令"Open the top drawer, and watch out for that vase",LLM 生成 Python 代码依次调用感知 API,构建 affordance(抽屉把手区域)与 avoidance(花瓶周围)两类 map,最终由规划器合成规避花瓶同时操作抽屉的轨迹。论文 Emergent Capabilities 图:系统的三种涌现能力——(左) 行为常识推理(如理解"左撇子"语境);(中) 基于用户反馈的细粒度语言纠错;(右) 多步视觉程序,适应物体几何信息不足的情况。
"It relies on external perception modules, which is limiting in tasks that require holistic visual reasoning or understanding of fine-grained object geometries."——当任务需要整体场景理解或精细物体几何时,基于 bounding box + 点云的感知链路存在明显短板。
Contact-rich 任务仍需通用 Dynamics 模型
"While applicable to efficient dynamics learning, a general-purpose dynamics model is still required to achieve contact-rich tasks with the same level of generalization."——论文中的 dynamics 学习仅针对平面推动模型,要实现与零样本任务同等泛化能力,仍需更通用的物理模型。
仅规划末端执行器轨迹,未考虑全臂规划
"Our motion planner considers only end-effector trajectories while whole-arm planning is also feasible and likely a better design choice."——当前规划器忽略机械臂本体碰撞,全臂规划将是更优但更复杂的选择。
需要手动 Prompt Engineering
"Manual prompt engineering is required for LLMs."——每个 LMP 需要 5–20 条精心设计的示例 query-response 对,在部署到新机器人平台或新任务领域时增加了适配成本。