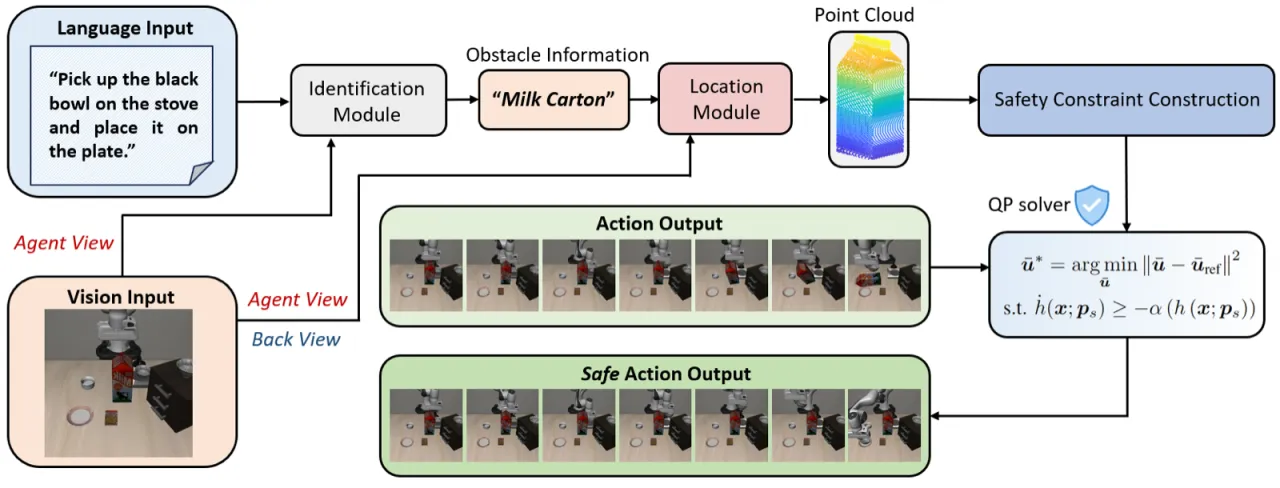
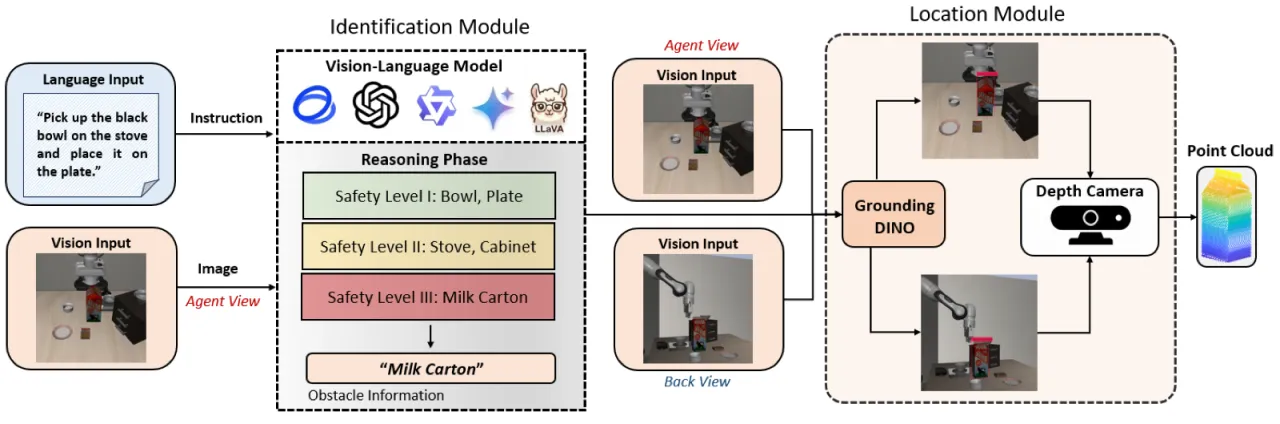
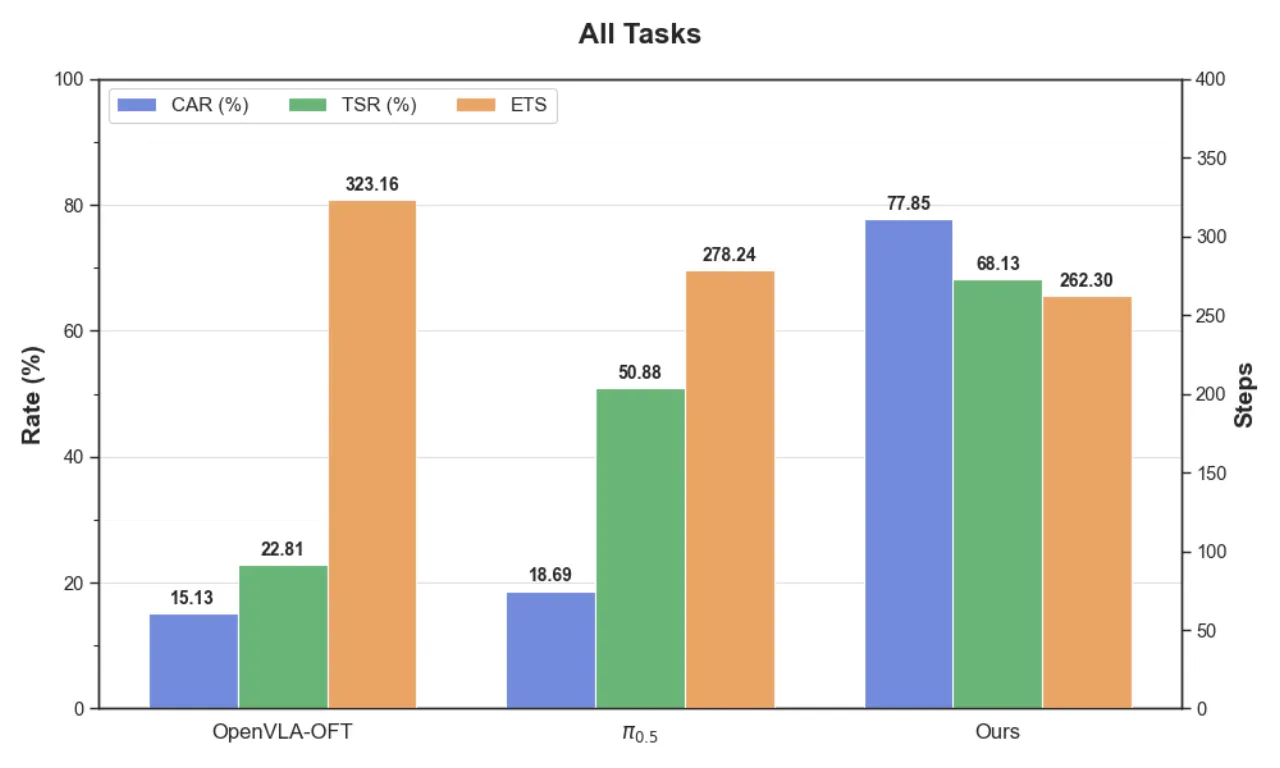
01 动机
VLA 模型在语义指令跟随方面表现出色,但在真实世界部署中缺乏明确的安全保障。碰撞可能导致硬件损坏、人员受伤或财产损失。现有安全方法大多依赖强化学习中的软约束,缺乏在推理时强制执行安全边界的显式机制。
"Safety stands as a prerequisite for the real-world deployment of VLA models, as collisions in unstructured environments can lead to hardware damage, human injury, or property loss."
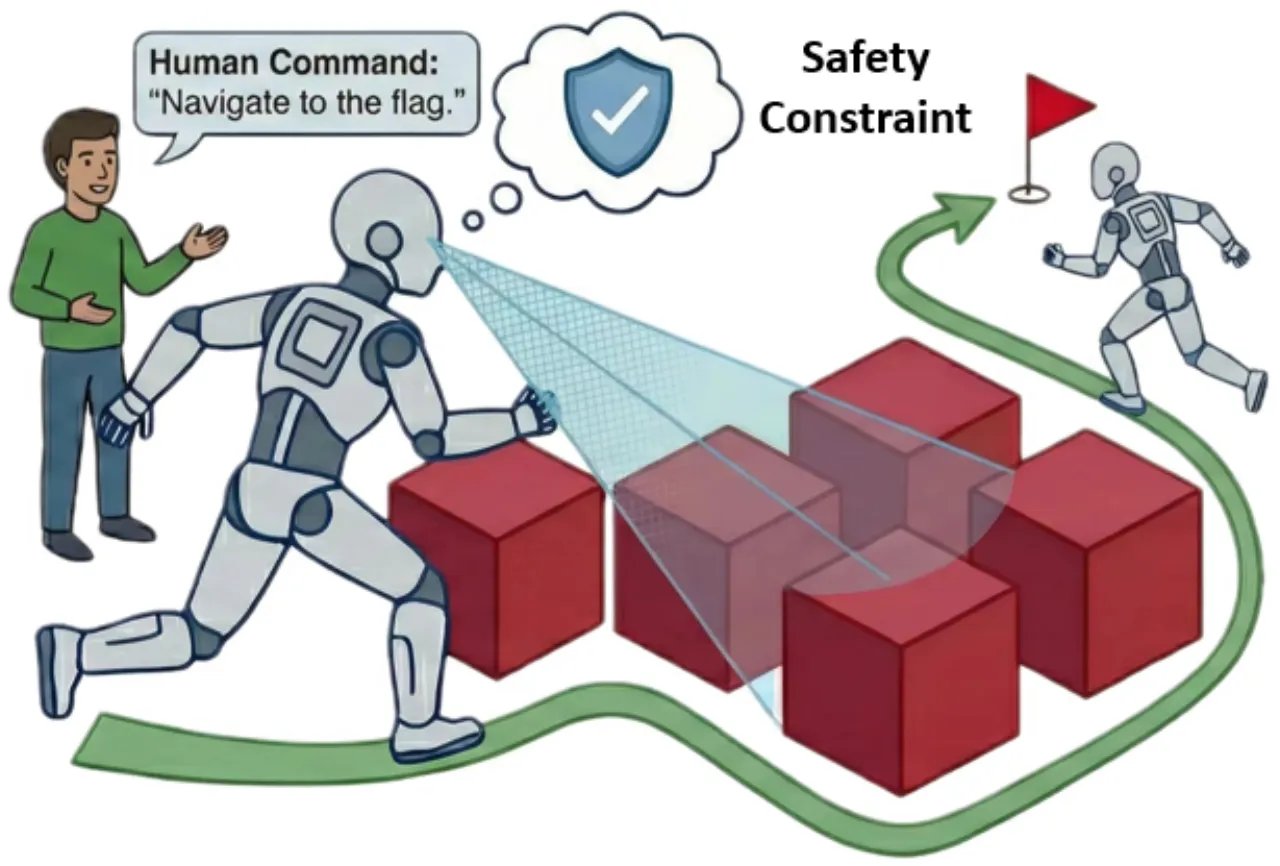
+59.16%障碍物回避率(CAR)提升
+17.25%任务成功率(TSR)提升
0.356 ms安全层额外计算延迟
~1.86%占总推理延迟比例