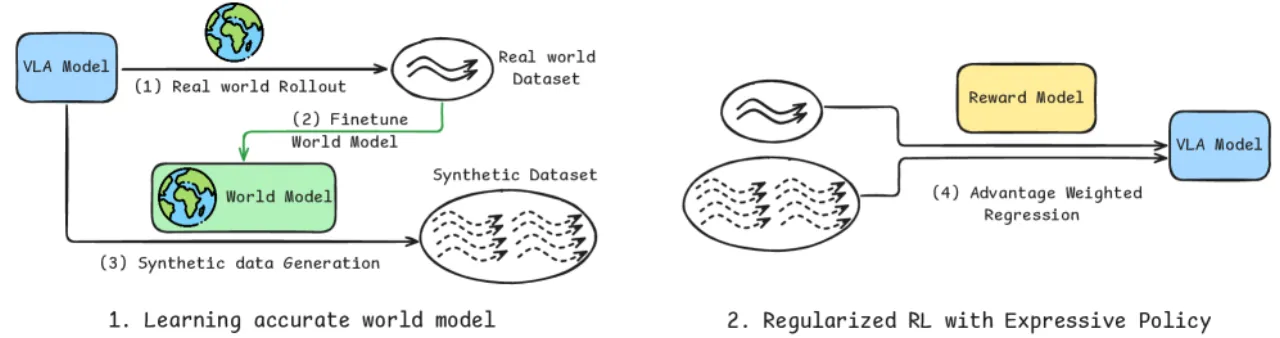
01 动机
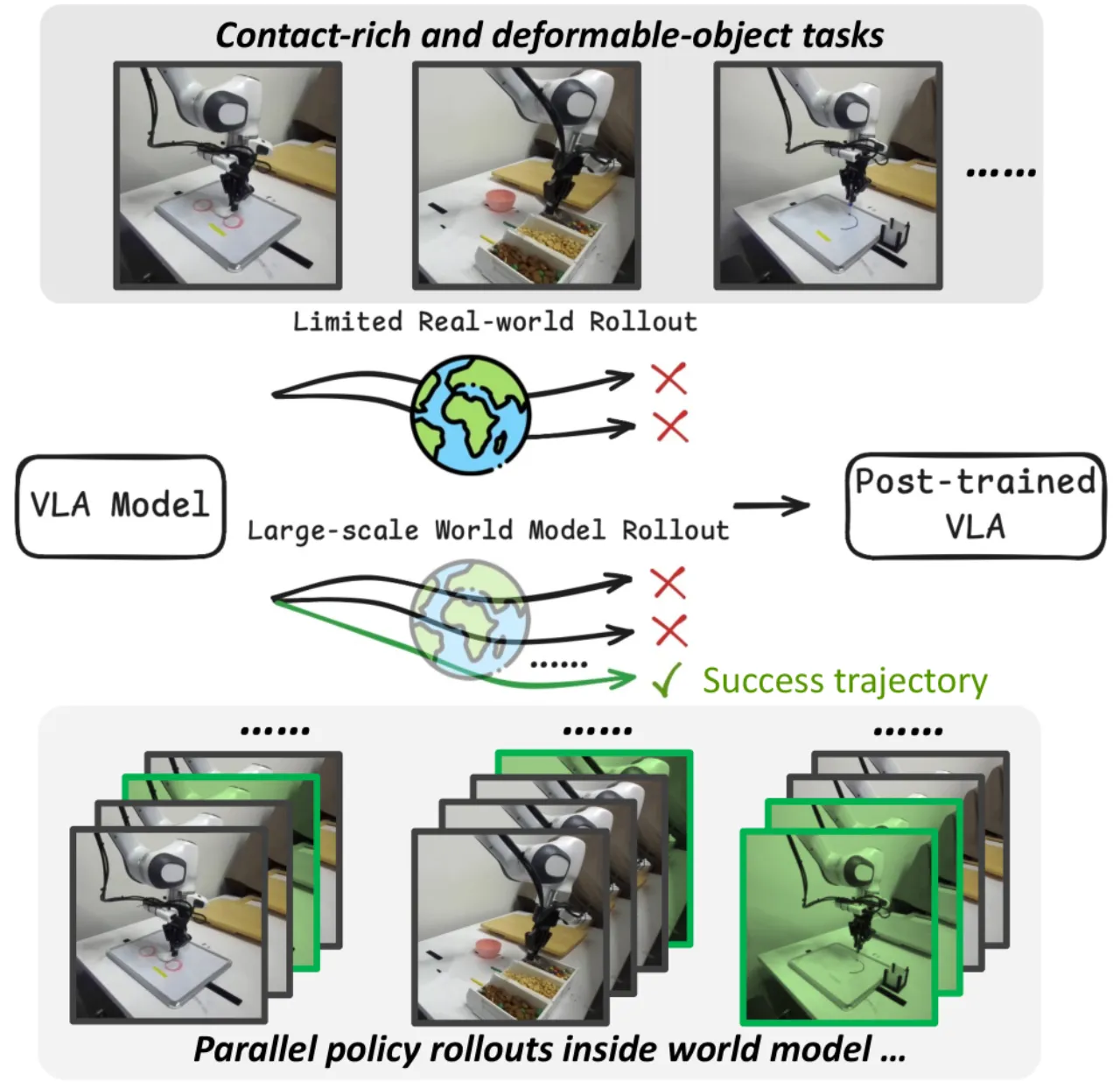
大规模预训练 VLA 策略(如 π₀.₅)在泛化上表现出色,但在新任务上直接部署时需要大量真实示范或代价高昂的物理回滚才能完成微调。现有方法要么依赖人工重置与监督(成本高),要么在合成数据与真实物理之间存在较大 sim-to-real gap。
"Although the learned world model achieves high fidelity on the downstream tasks from which online data are collected, our current evaluation is limited to five task categories."
世界模型(video generation model)是生成合成机器人数据的理想工具,但预训练世界模型往往缺乏对目标任务物理动态的精确建模——尤其是接触密集型操作(如叠放物体、擦黑板、翻书)。VLAW 的核心洞察是:少量真实回滚数据足以将预训练世界模型接地,使其能忠实模拟目标任务的物理过程;接地后的世界模型又能批量生成高质量合成轨迹来训练 VLA 策略,从而减少对昂贵真实交互的依赖。
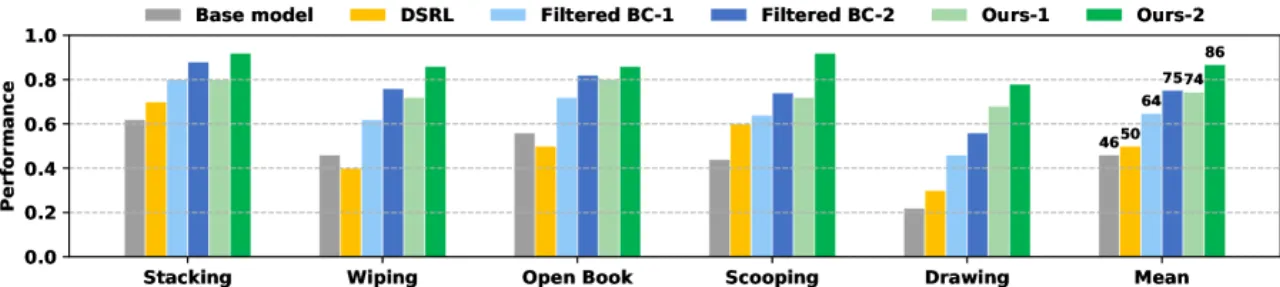
39.2%平均绝对成功率提升(vs 基础策略)
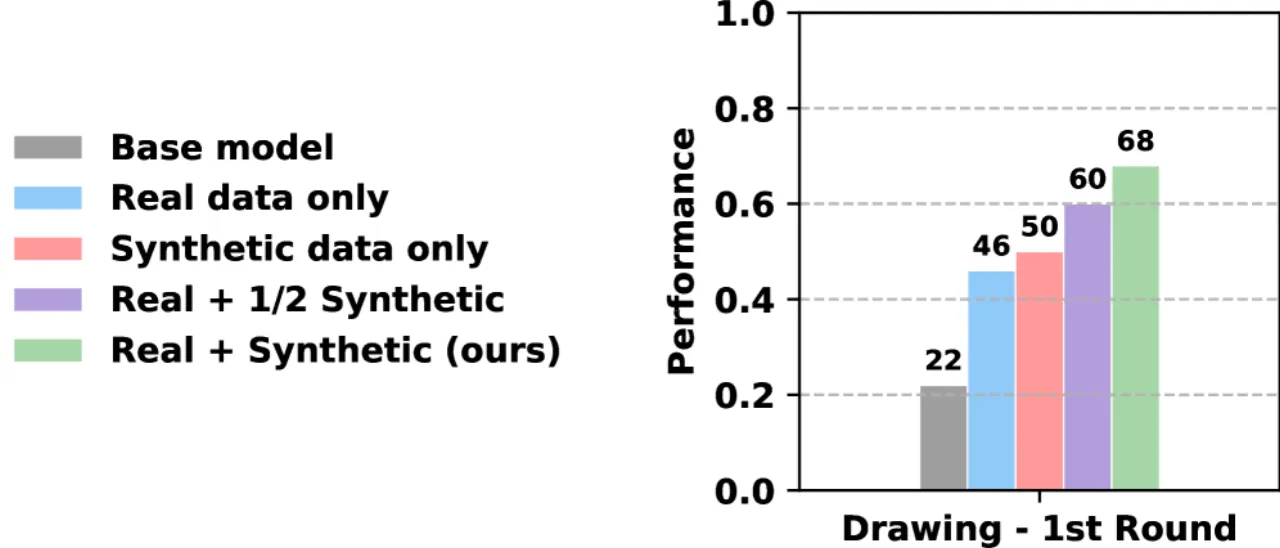
11.6%合成数据带来的额外提升(vs 仅用真实数据)
50每次迭代所需真实回滚条数
2迭代轮数即达最优