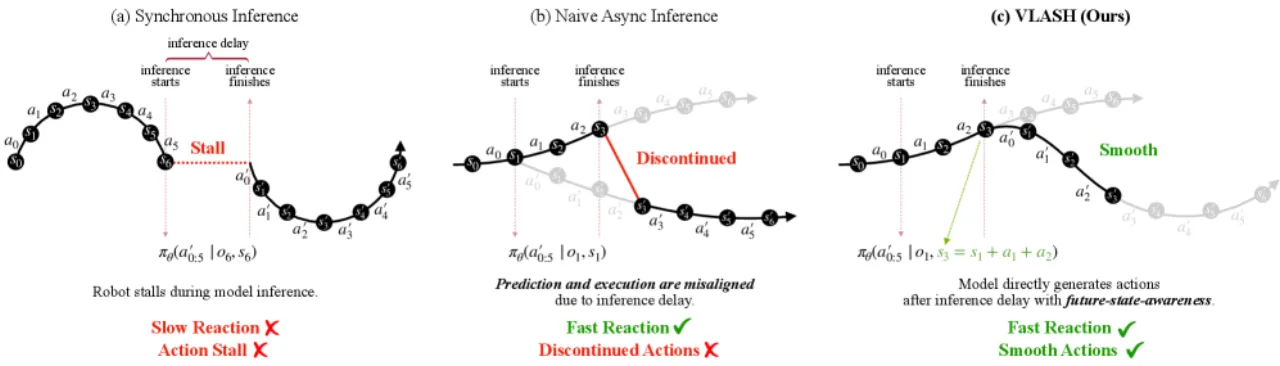
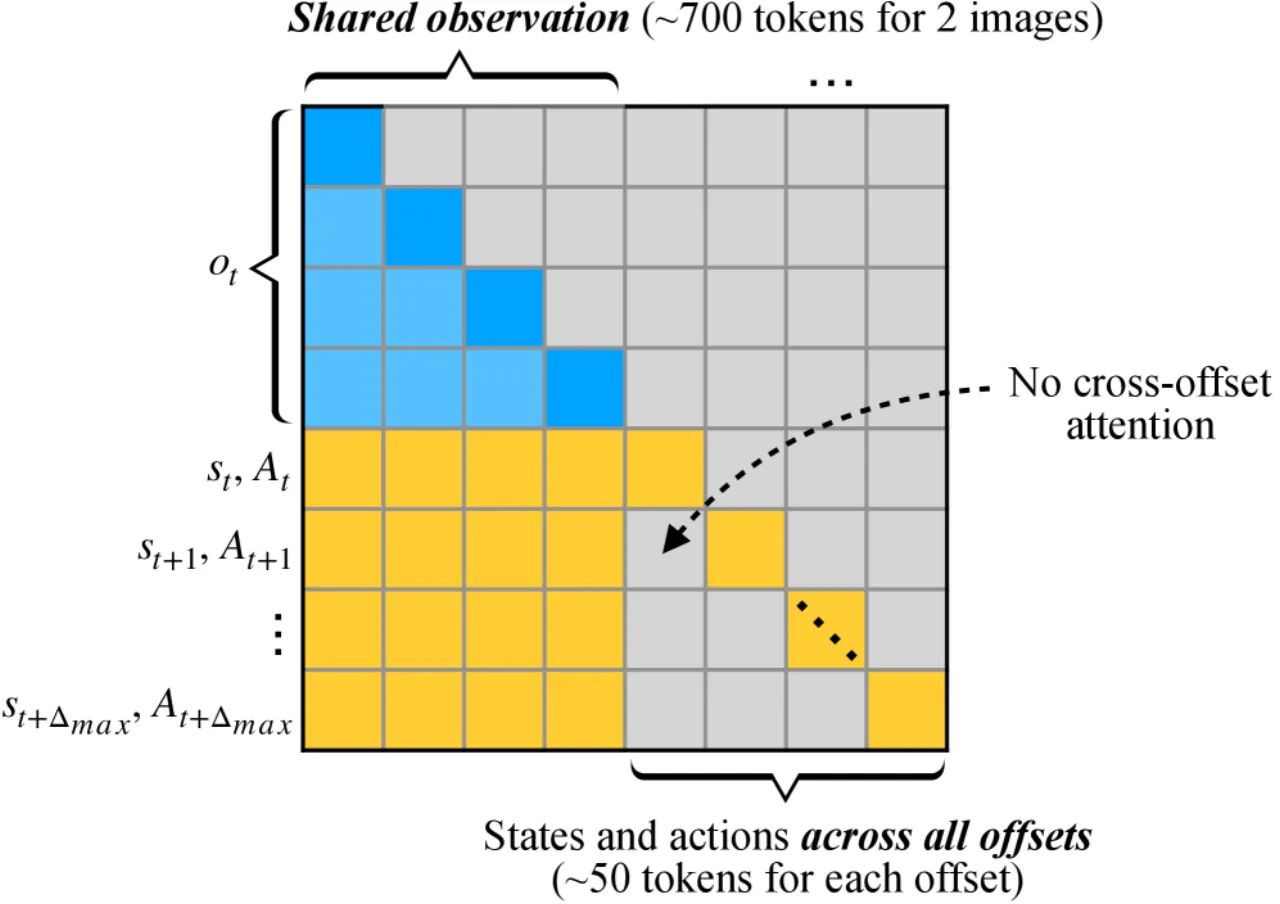
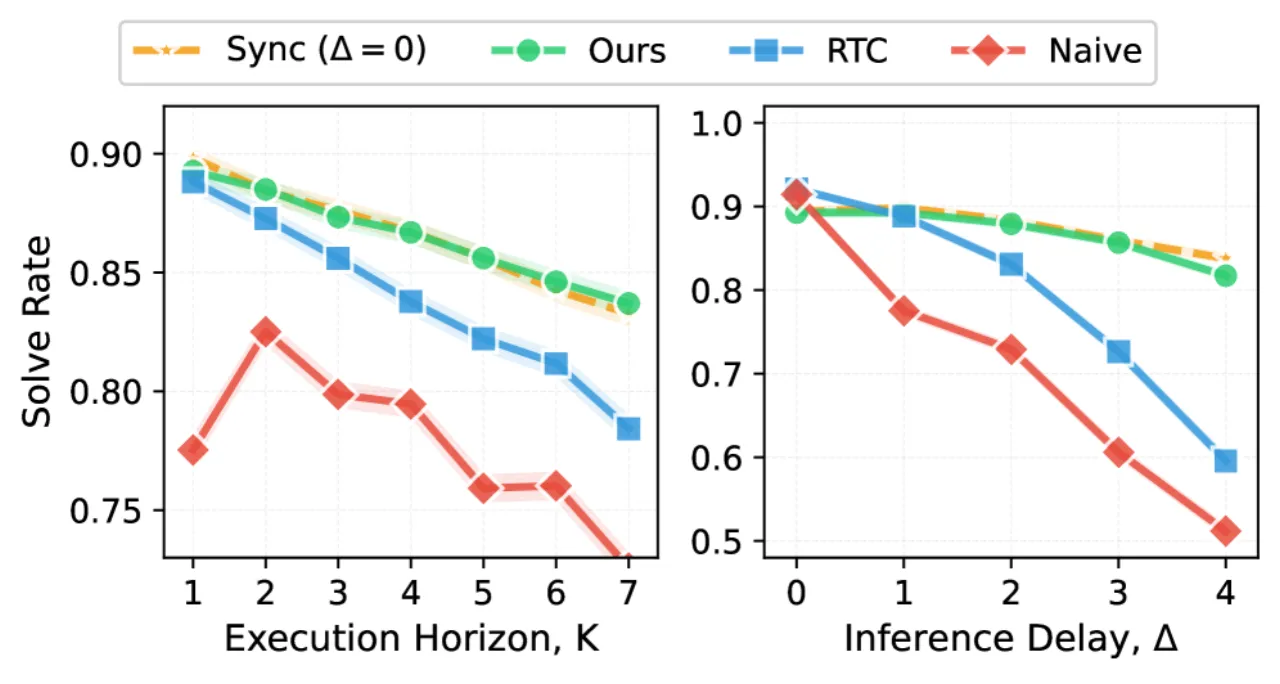
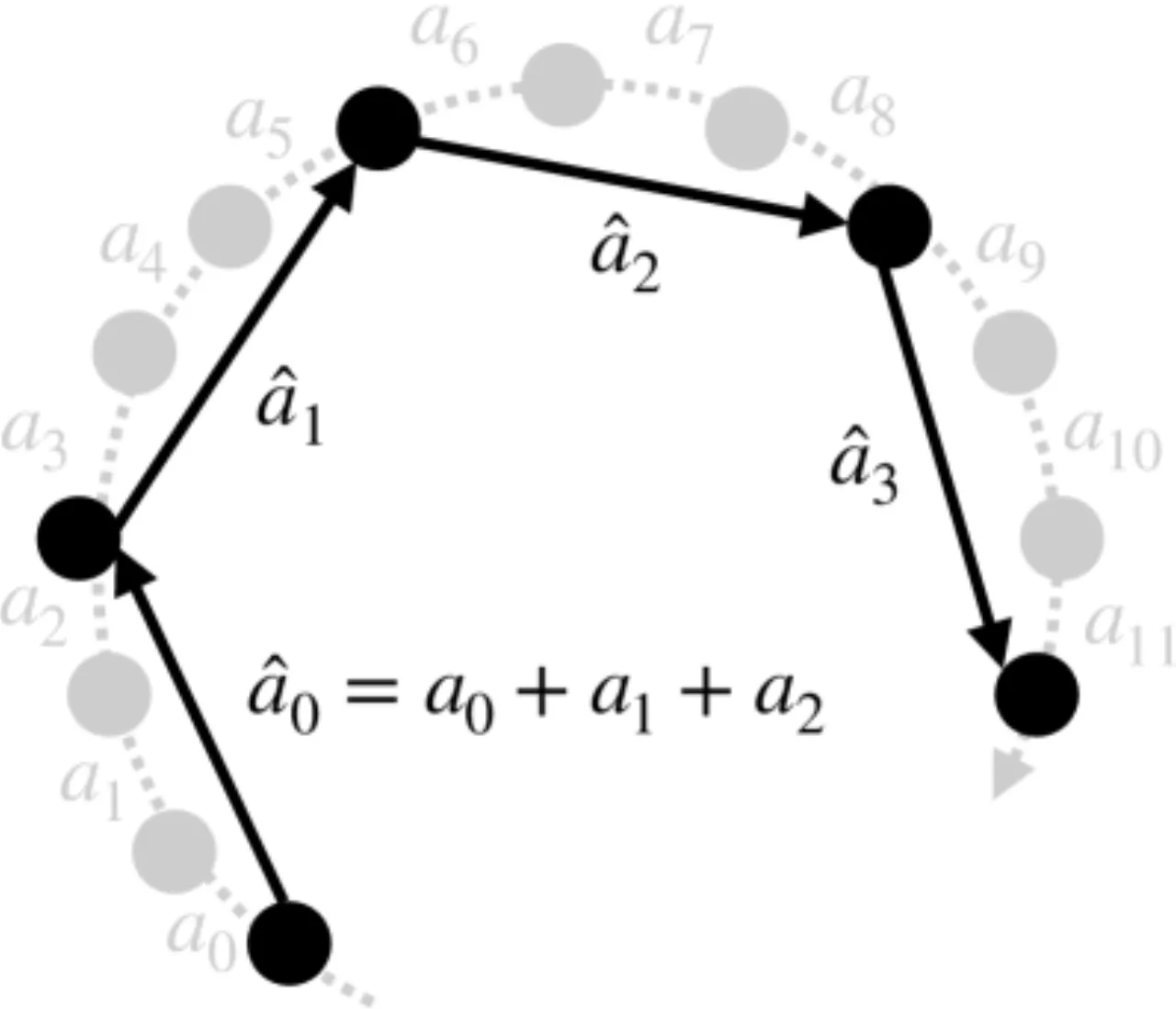
01 动机
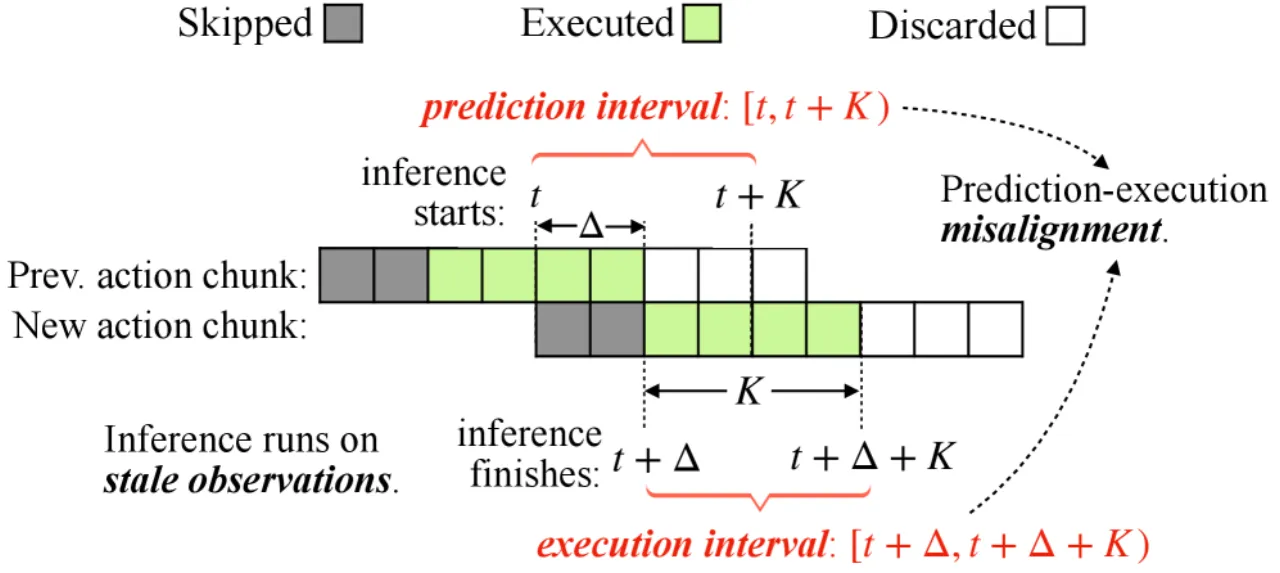
当前 VLA 模型推理延迟高(数百毫秒),若采用同步推理,机器人在等待结果期间必须停止运动,造成"动作停顿",严重降低任务效率;而直接切换为异步推理(执行与推理并行),则会引入时序错位问题——模型推理时的机器人状态与实际执行时的状态不一致,导致控制不稳定甚至失败。
"Asynchronous inference… introduces a fundamental challenge: the robot's execution-time state diverges from the prediction-time state due to inference latency Δ, causing severe instability and degraded control accuracy."
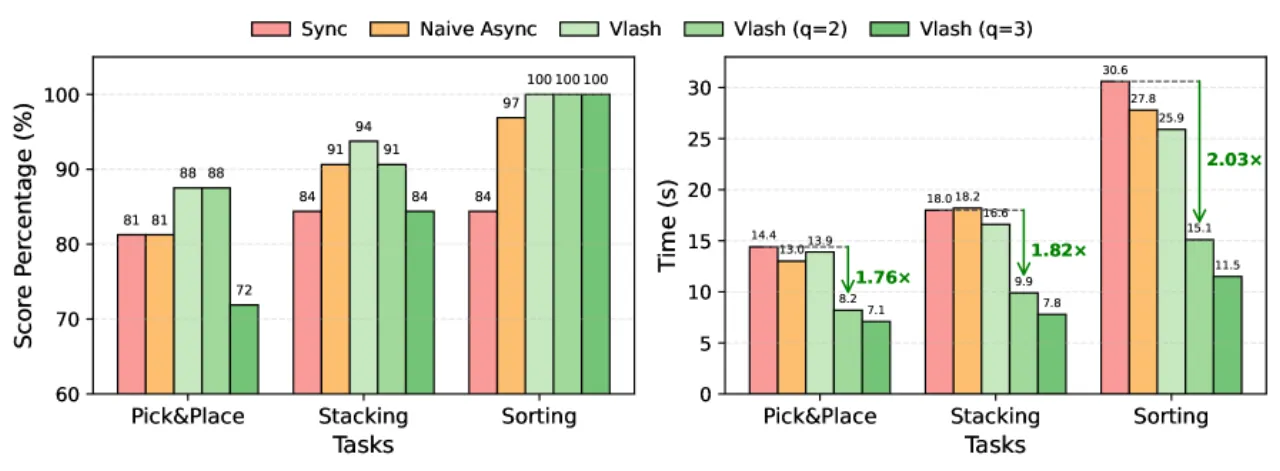
17.4×最大反应延迟降低幅度(RTX 5090)
2.03×实际机器人最大速度提升(q=2 量化)
94%真实环境任务平均得分(vs 同步 83%)
5×高效微调时有效训练轨迹扩增倍数