01 动机
当前 VLA(Vision-Language-Action)模型研究存在严重的设计碎片化问题:各方法在不同模型规模、不同数据集上独立提出各自的模块,缺乏公平的横向对比,导致社区难以判断哪些设计选择真正重要、如何系统地改进模型。
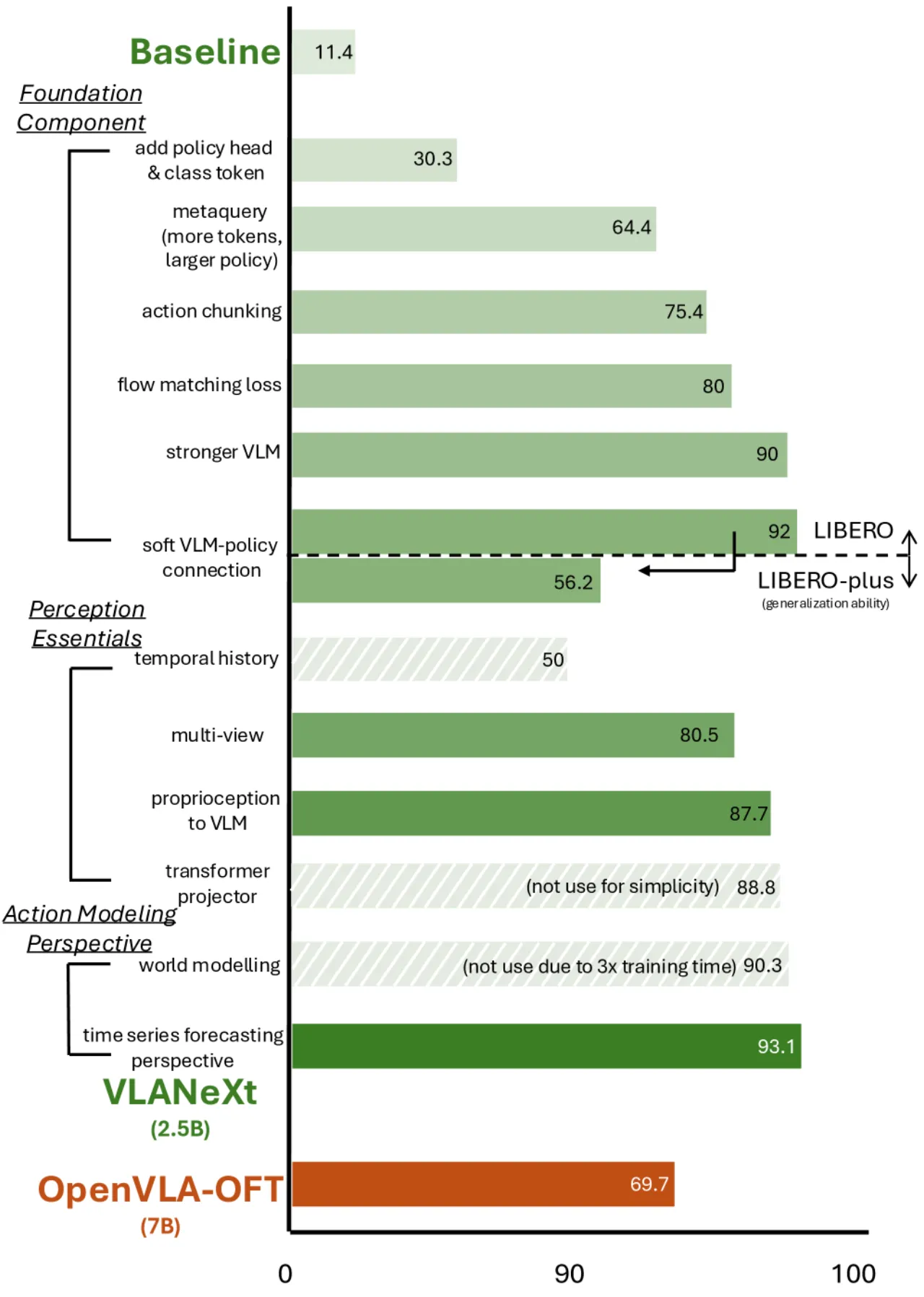
"We distill 12 key findings that together form a practical recipe for building strong VLA models."
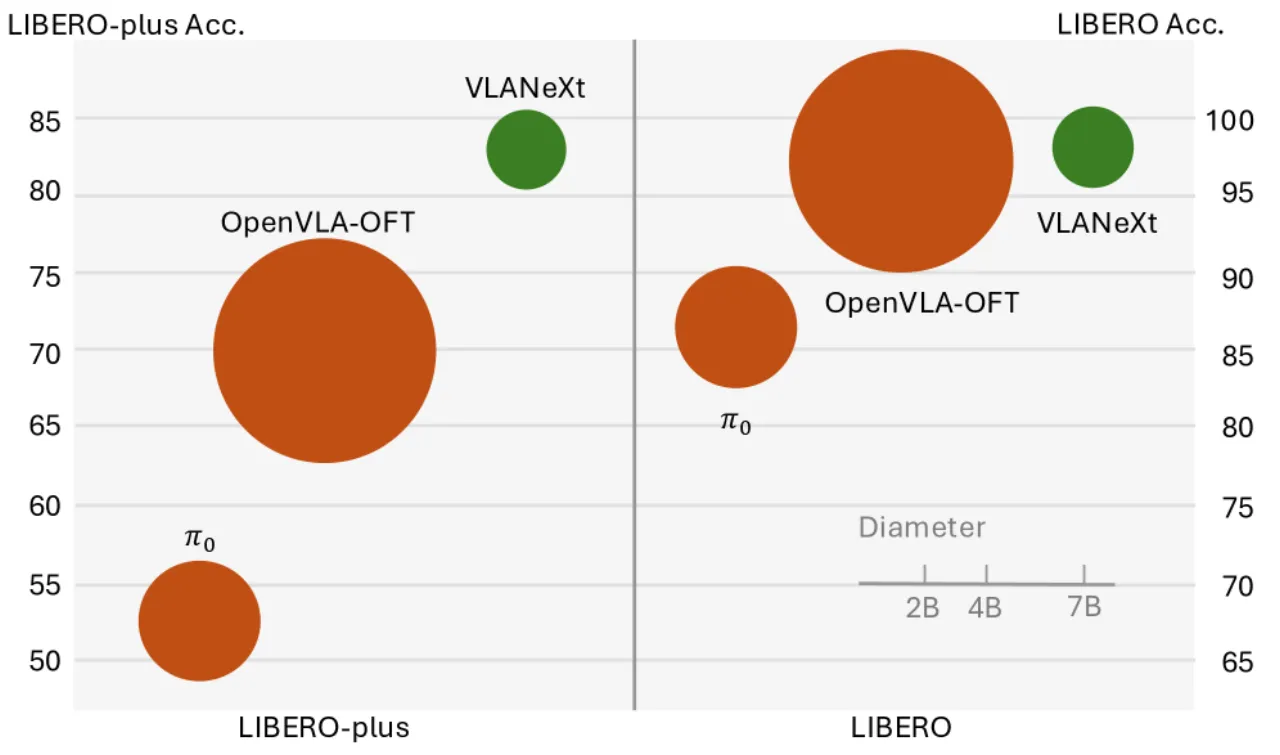
97.4%LIBERO 全套均值(vs. OpenVLA-OFT 97.1%)
83.9%LIBERO-plus 均值(vs. OpenVLA-OFT 69.6%)
+14.3%LIBERO-plus 上超越 OpenVLA-OFT
2.5B参数规模(仅为 OpenVLA-OFT 的 35%)
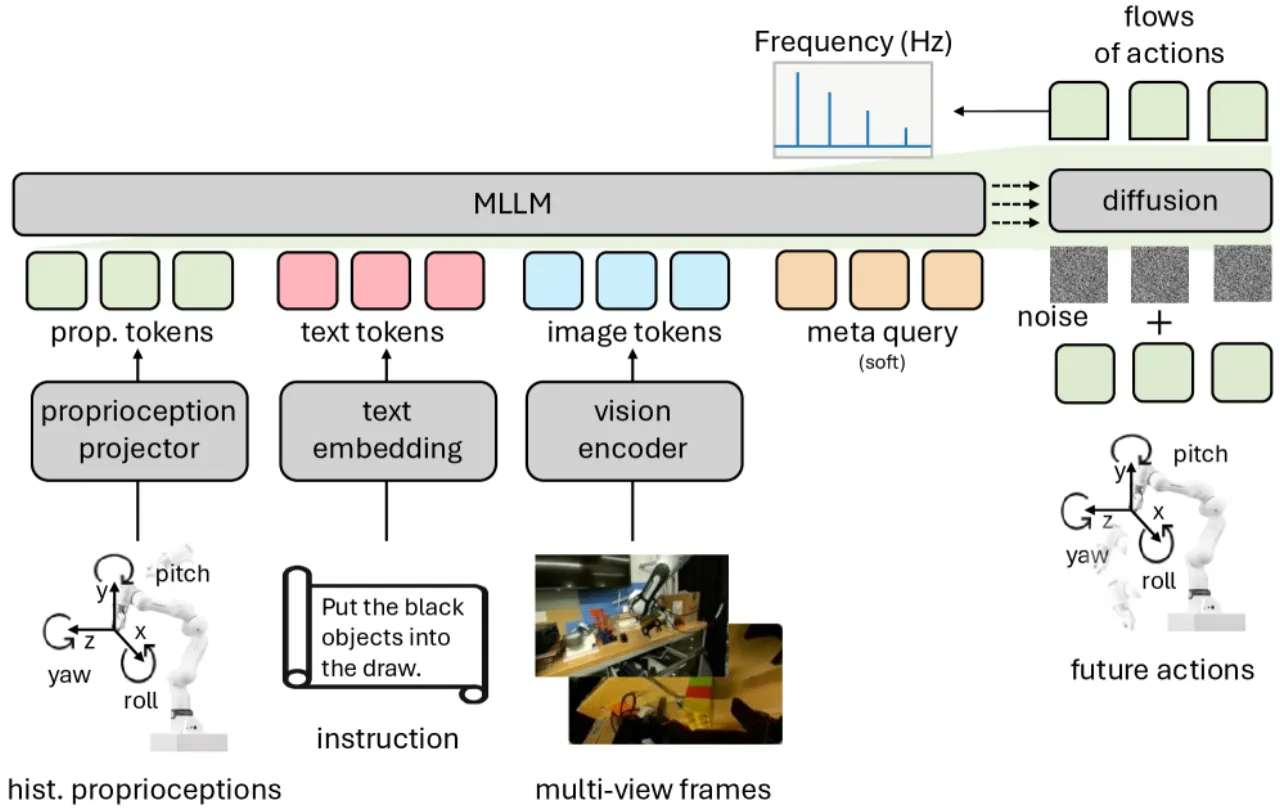
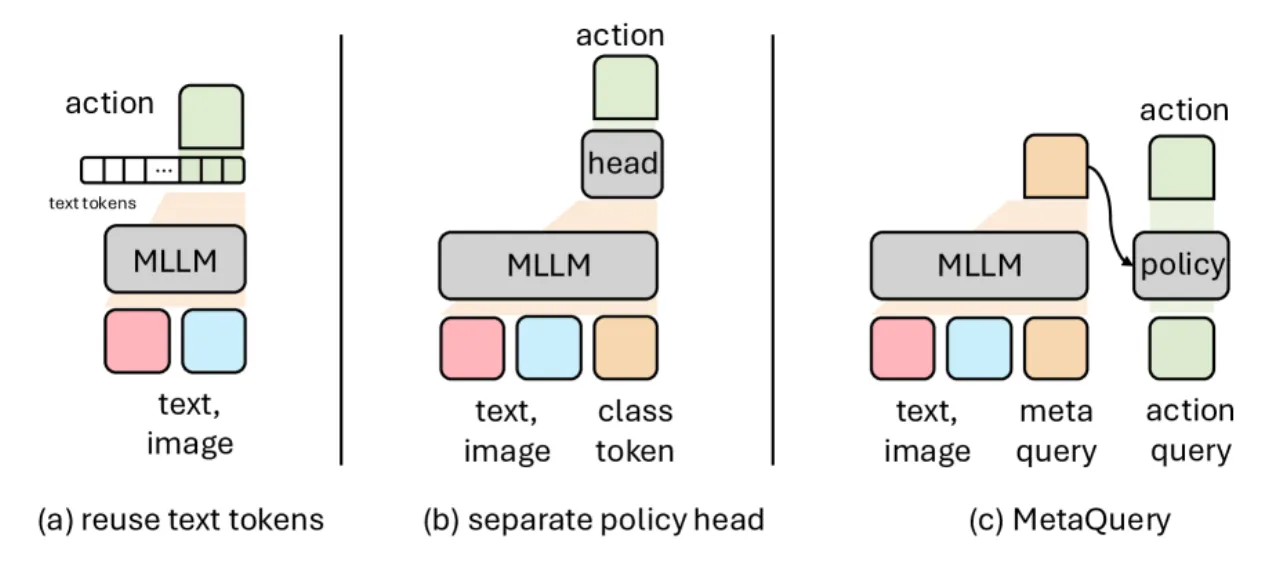
本文选取 RT-2/OpenVLA 范式(预训练 VLM + 策略头)作为统一基线,在相同实验设置下逐步改变一个设计维度,严格量化每项改动的收益。这种受控实验思路揭示了此前被忽视却影响显著的设计规律。