01 动机
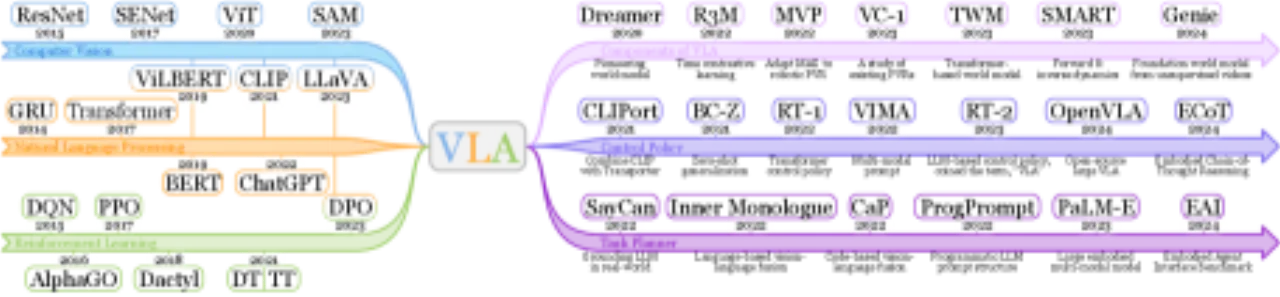
传统基于强化学习的机器人策略"largely focused on addressing a limited set of tasks within controlled environments",难以泛化到真实复杂场景。随着大型语言模型(LLM)和视觉-语言模型(VLM)的崛起,将语言理解、视觉感知与机器人动作生成统一到同一模型的需求日益迫切——这正是 VLA 模型的核心出发点。
"Embodied AI is widely recognized as a cornerstone of artificial general intelligence (AGI)."
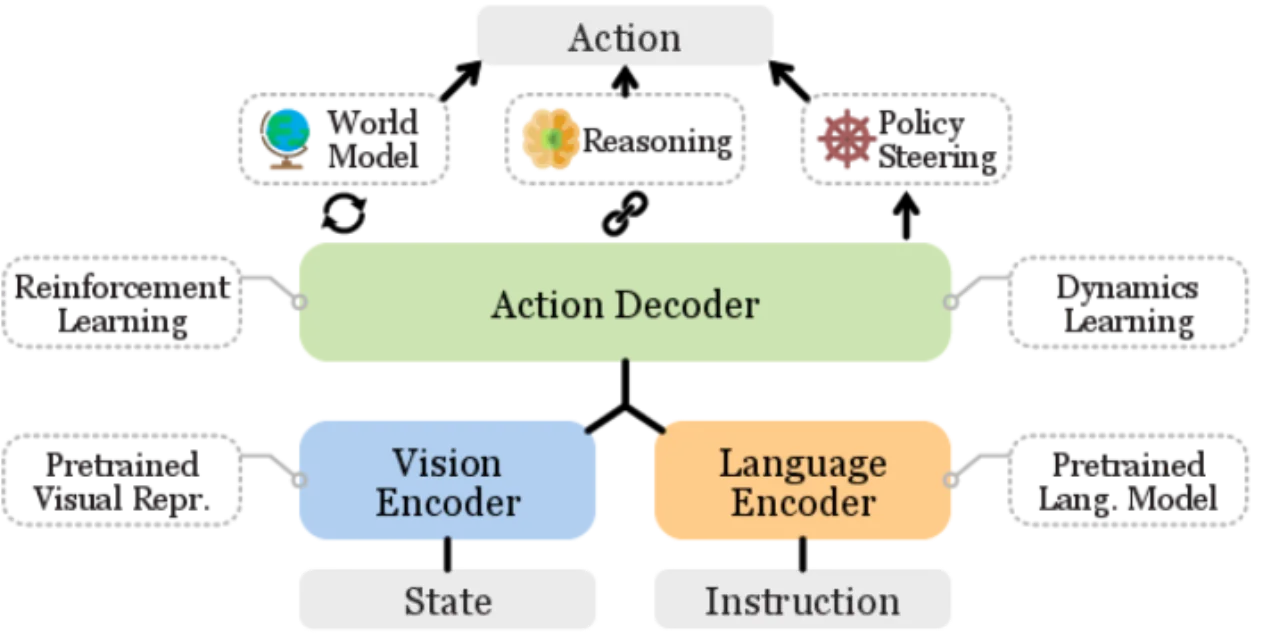
3研究方向
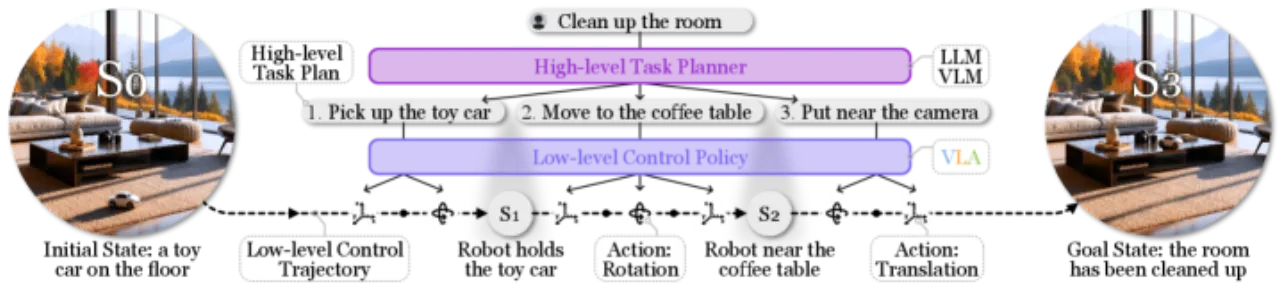
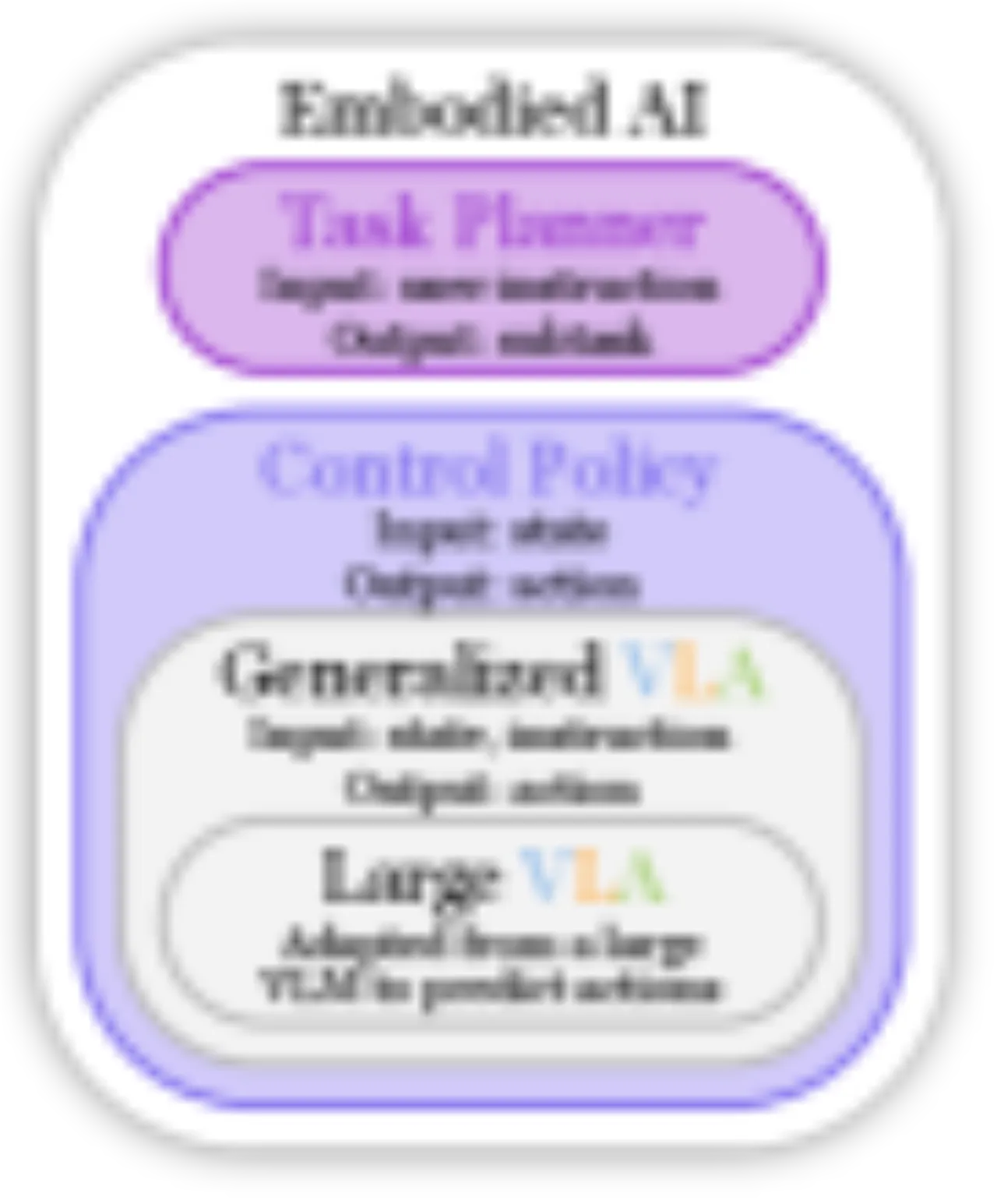
(组件 / 低层策略 / 任务规划)
(组件 / 低层策略 / 任务规划)
50+低层控制策略
系统梳理(Table III)
系统梳理(Table III)
400MCLIP 训练图文对
(WIT 数据集)
(WIT 数据集)
8未来挑战方向
(Section VI)
(Section VI)