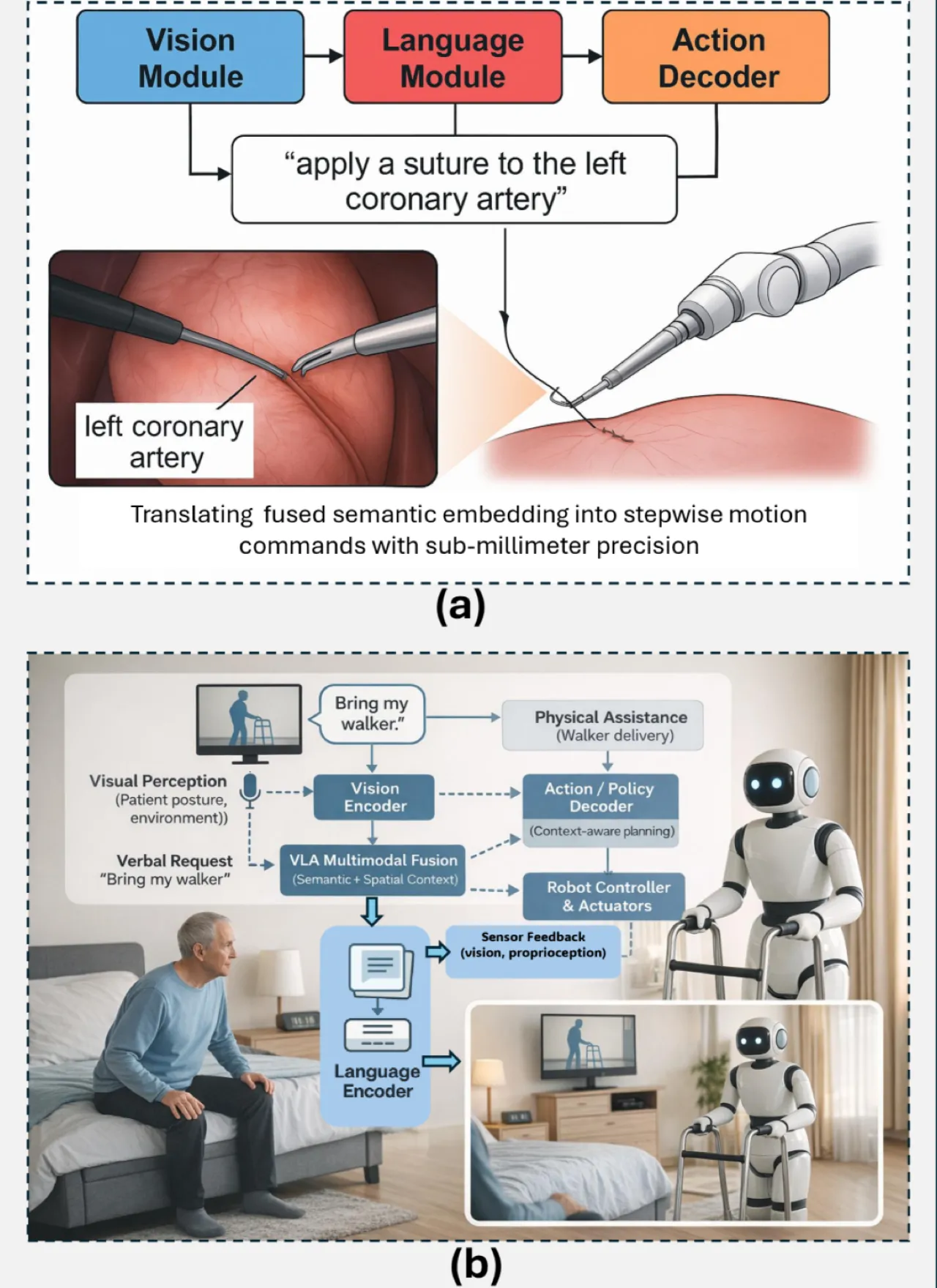
01 动机
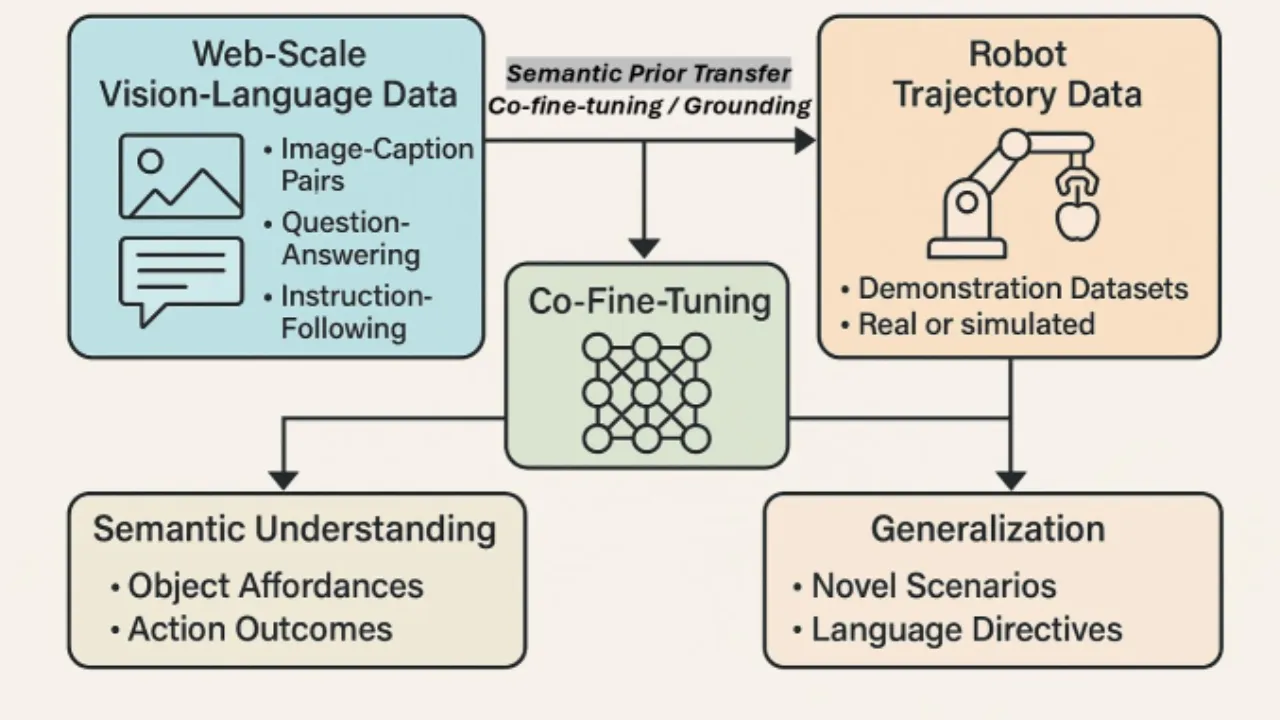
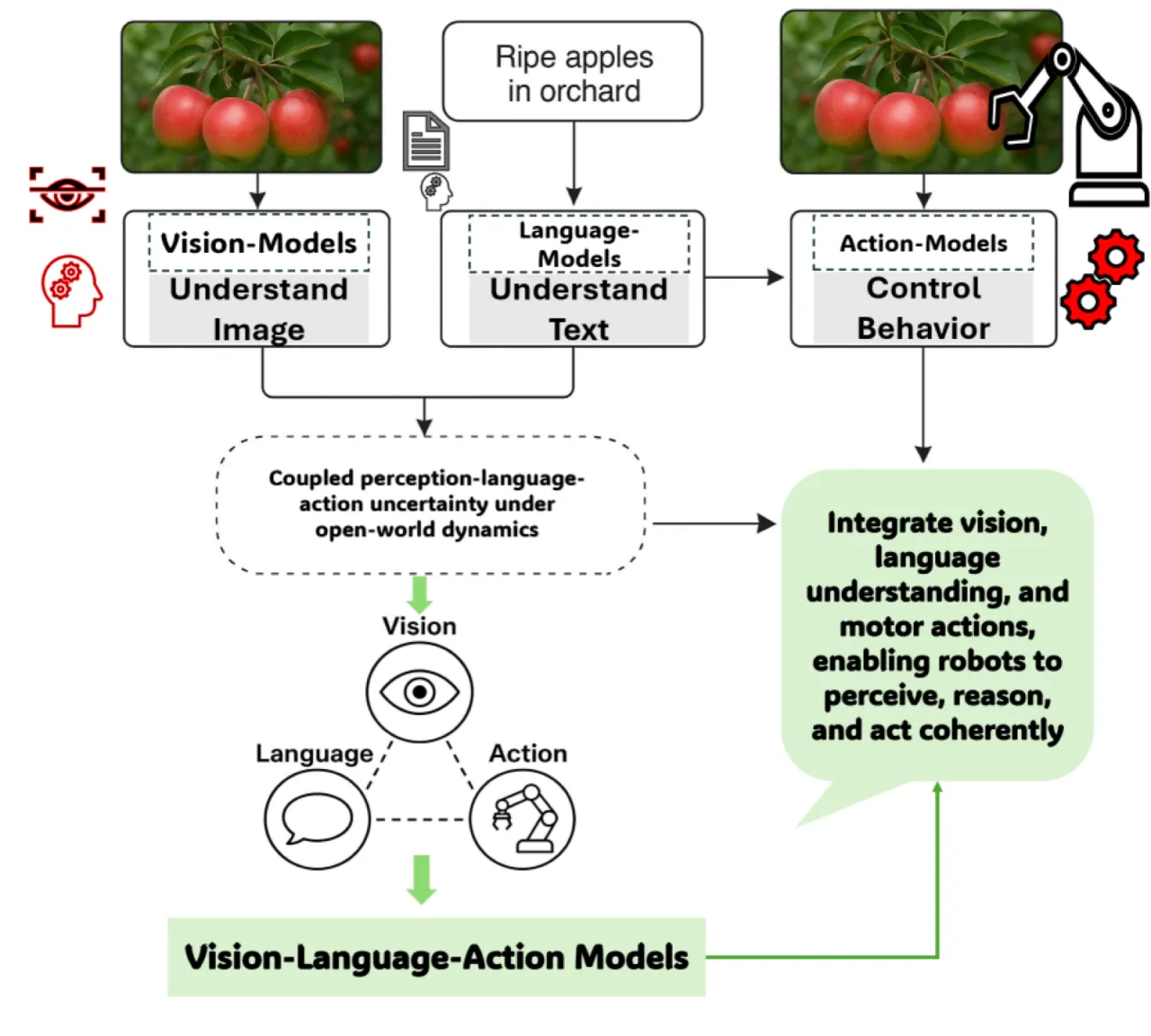
传统机器人系统将视觉、语言和动作视为独立子系统分别处理。"机器人能够在视觉上识别物体、 理解文本指令或执行预定义动作,但将三者全部整合仍然极具挑战性。"VLA 模型正是为打破这一割裂局面而生—— 在单一计算框架内实现感知、语言理解与具身动作的统一。
"Integrated perception, language, and action enable adaptive, generalizable embodied intelligence." —— 论文核心主张
80+综述覆盖 VLA 模型数量(近三年)
45时间轴标注模型(2022–2025)
4演化阶段(基础 → 专化 → 泛化 → 跨形态)
9未来研究方向(路线图)
为何需要 VLA?
大型视觉-语言模型(VLM)的崛起使"将感知、理解与行动统一于单一框架"成为可能。 然而,从 VLM 到 VLA 并非简单扩展:机器人需要实时闭环控制、跨形态泛化 和安全对齐,而这些在纯语言/图像生成场景中几乎不存在。本综述正是系统梳理 这一演化路径,识别已解决与尚待攻克的问题。