01 动机
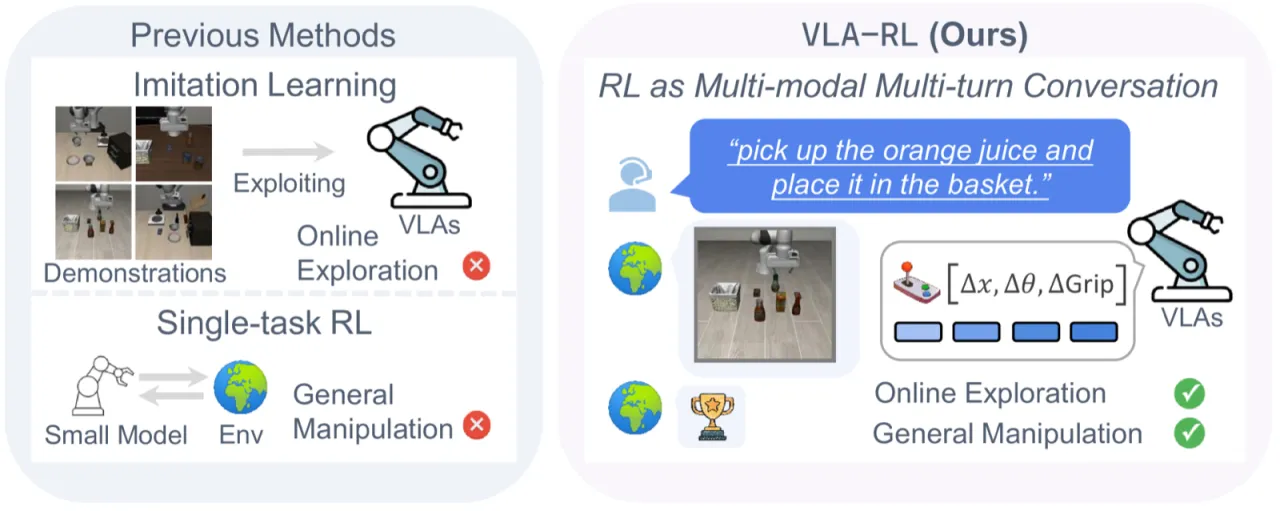
模仿学习驱动的 VLA 模型在遇到训练数据未覆盖的状态时会出现执行失败,根本原因在于其固有的"利用(exploitation)"策略:模型只知道如何重现已见过的轨迹,缺乏在线探索与自我修正能力。
"exploiting offline data with limited visited states will cause execution failure in out-of-distribution scenarios."
作者提出将 VLA 的训练范式从"剥削式"(exploitation-based)转向"探索式"(exploration-based),通过强化学习在测试时收集的在线数据上持续改进。传统 RL 面临数据低效与繁重的奖励工程挑战,但从大型基础模型出发进行微调可以显著缓解这两个问题。
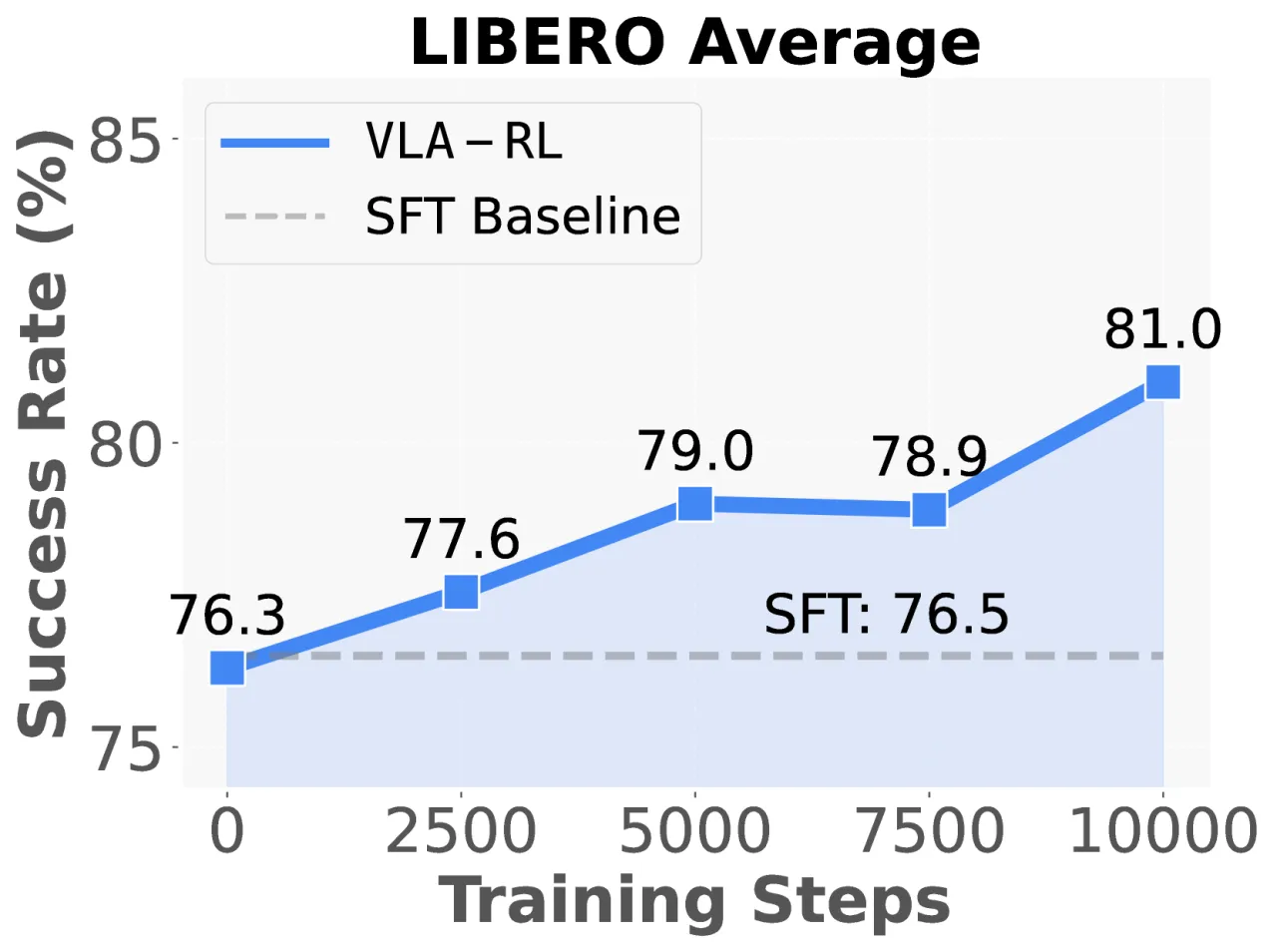
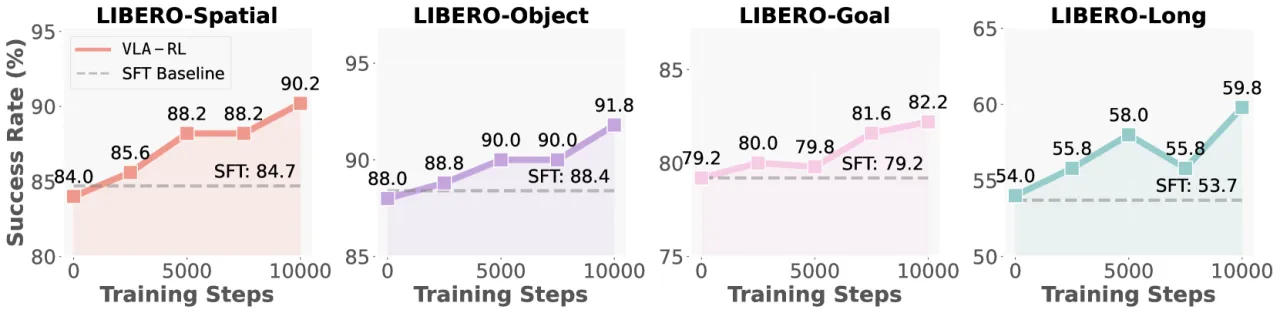
+4.5%OpenVLA-7B 在 LIBERO 上的平均成功率提升
+1.8%相比 DPO 基线(GRAPE)的提升
48 hRL 训练所需 GPU 小时数
40LIBERO 评测任务数量