01 动机
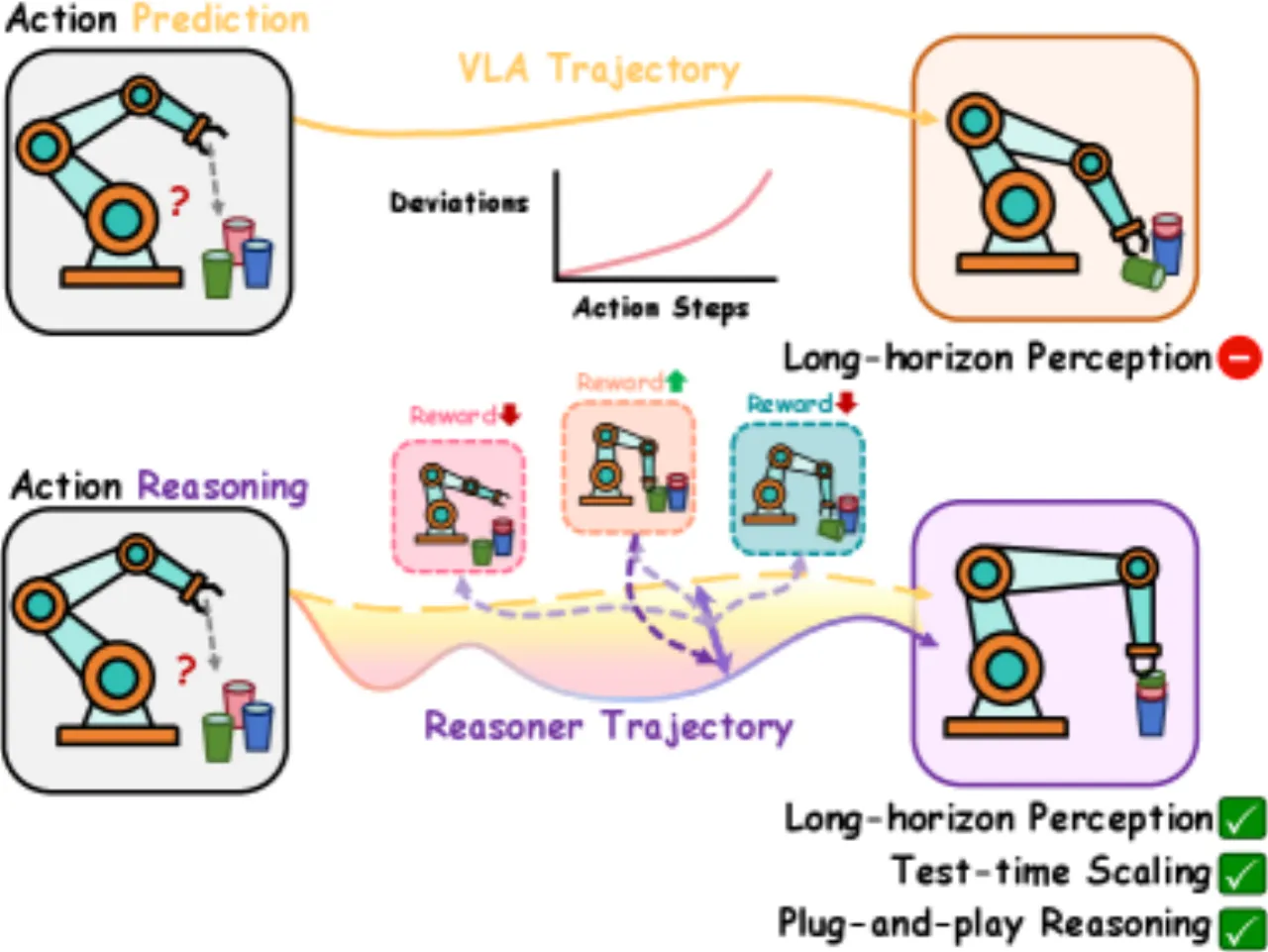
当前 Vision-Language-Action(VLA)模型在机器人部署时存在"短视"问题:每一步只预测当前最优动作,不考虑后续轨迹后果,导致误差随时间累积,长视野任务失败率高。
"Can VLAs explore the long-horizon future influence of actions at test time, and decide the optimal action?"
+19%OpenVLA 真实任务绝对成功率提升(22% → 41%)
+10%π0-FAST 真实任务绝对成功率提升(64% → 74%)
+9.8%Octo-Small 在仿真中的绝对提升
3 VLAs覆盖 OpenVLA / Octo-Small / SpatialVLA 三类骨干
VLA 模型继承了大规模视觉-语言预训练的泛化能力,在机器人模仿学习上取得了显著成果。然而,这类模型在部署阶段仍然脆弱——它们将机器人控制当作一步步的局部决策,忽略了动作对未来状态的长链式影响。对于需要精确堆叠、抓取或多步协调的任务,即使微小的偏差也会随时间放大,最终导致任务失败。
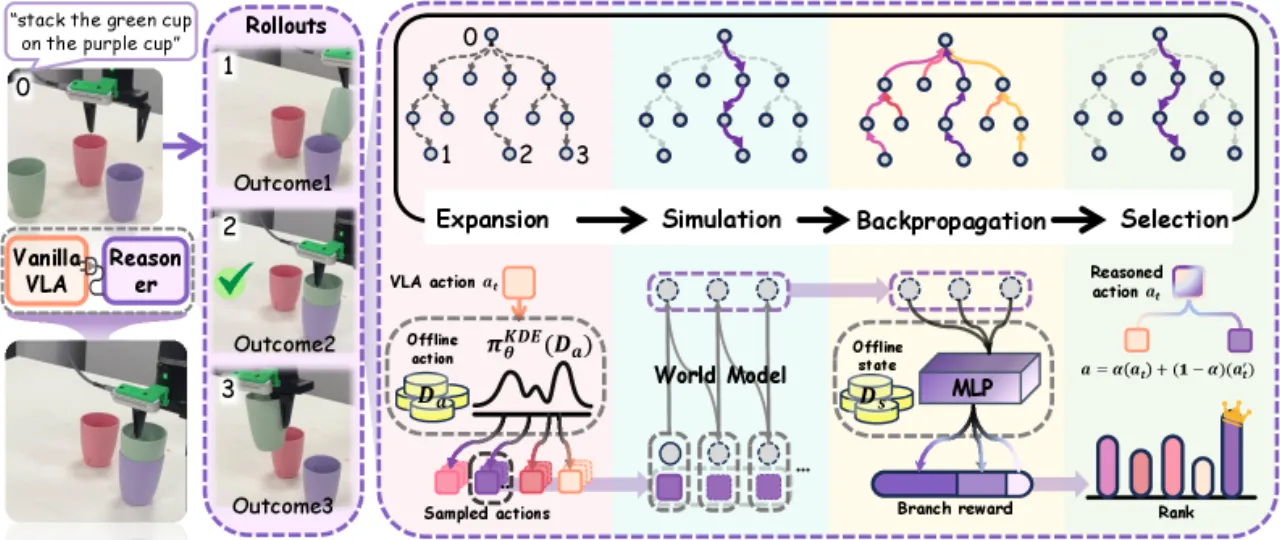
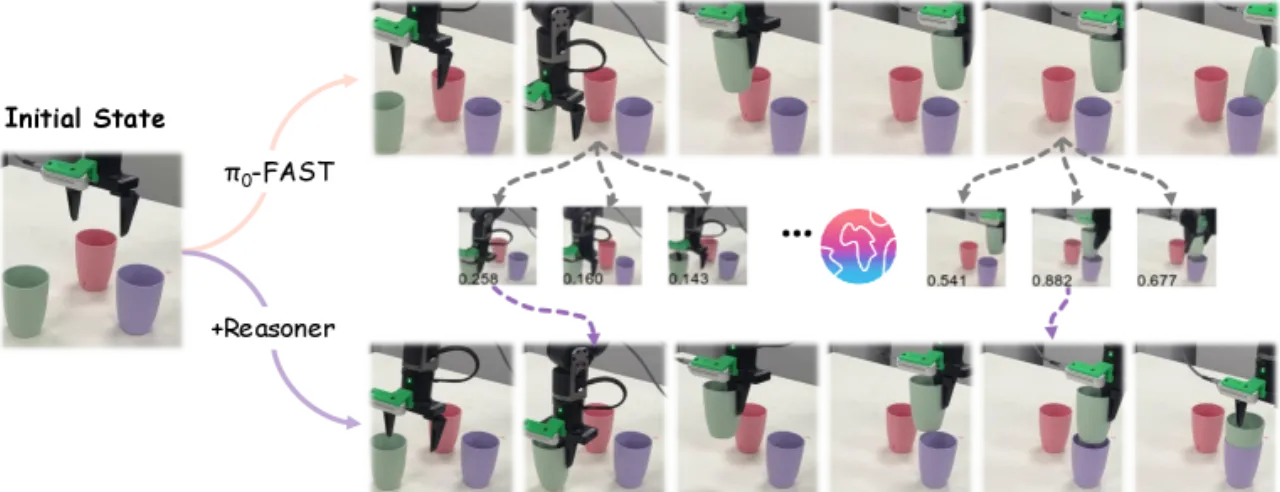
VLA-Reasoner 的核心思路是:不修改 VLA 权重,仅在测试时外挂一套基于 MCTS 的规划模块,通过学习型世界模型模拟未来状态,以 value function 引导搜索,从而找到长视野更优的动作。