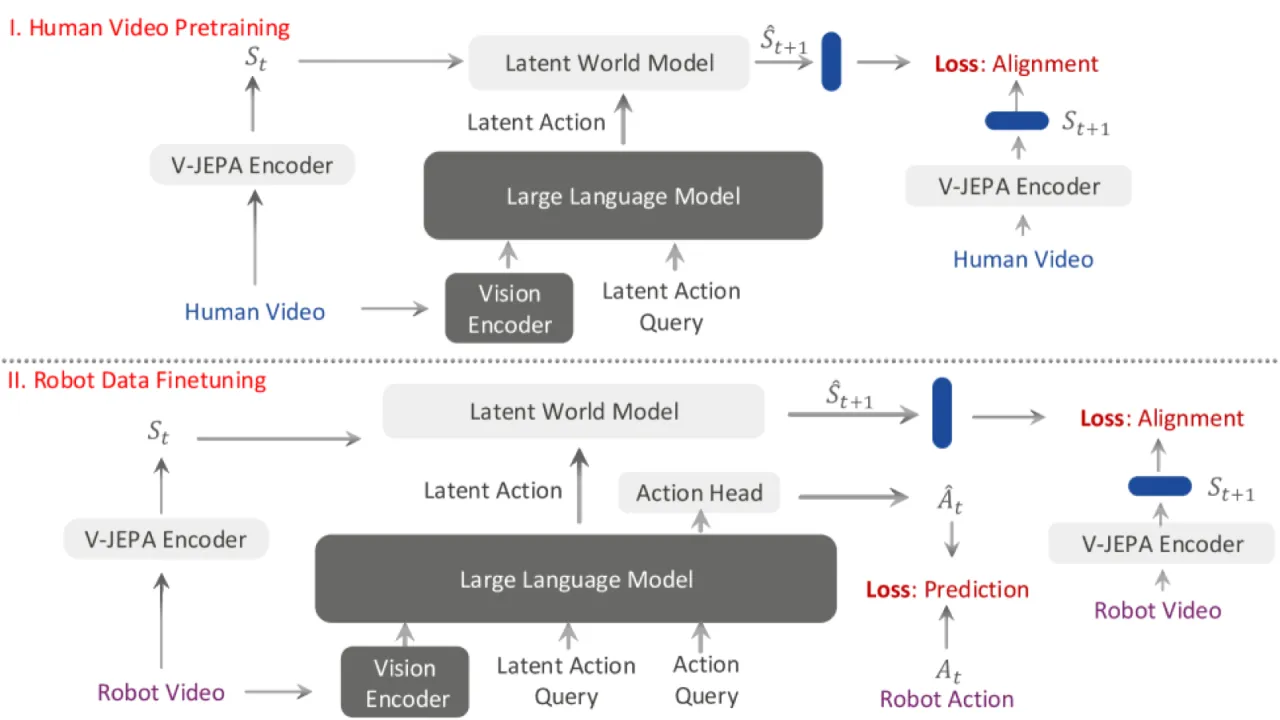
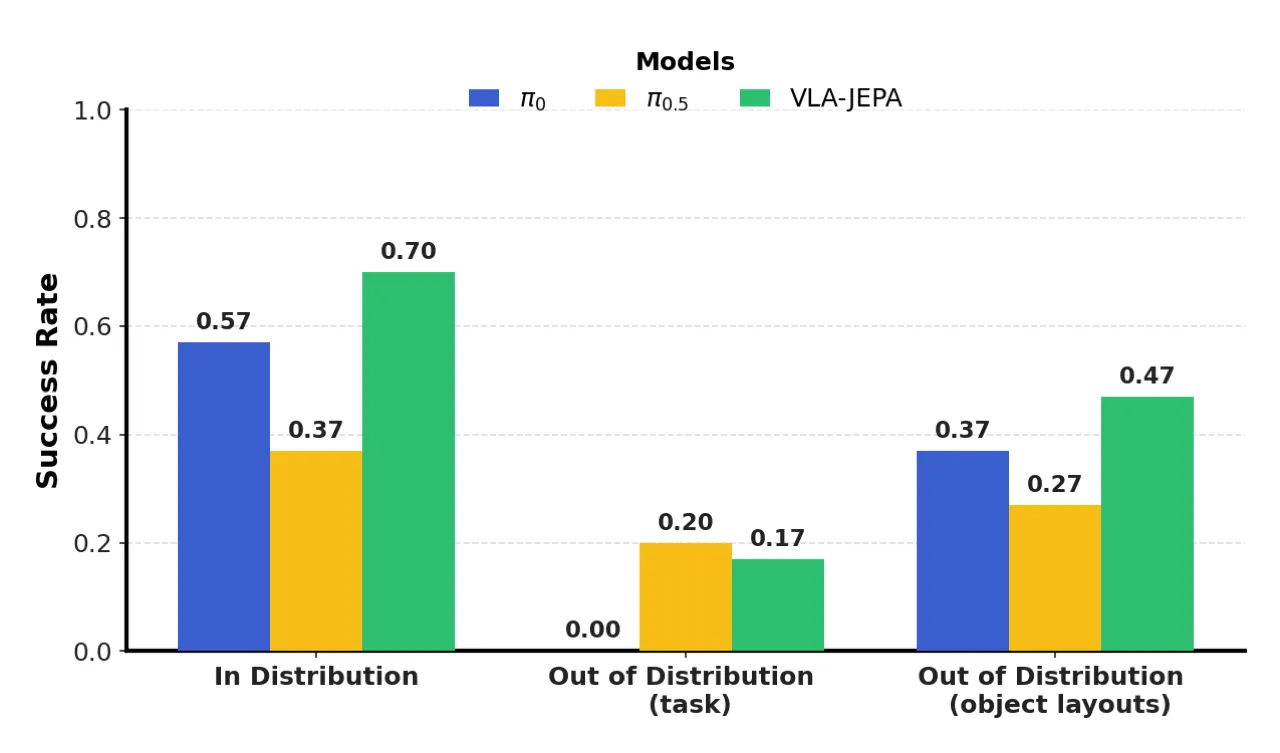
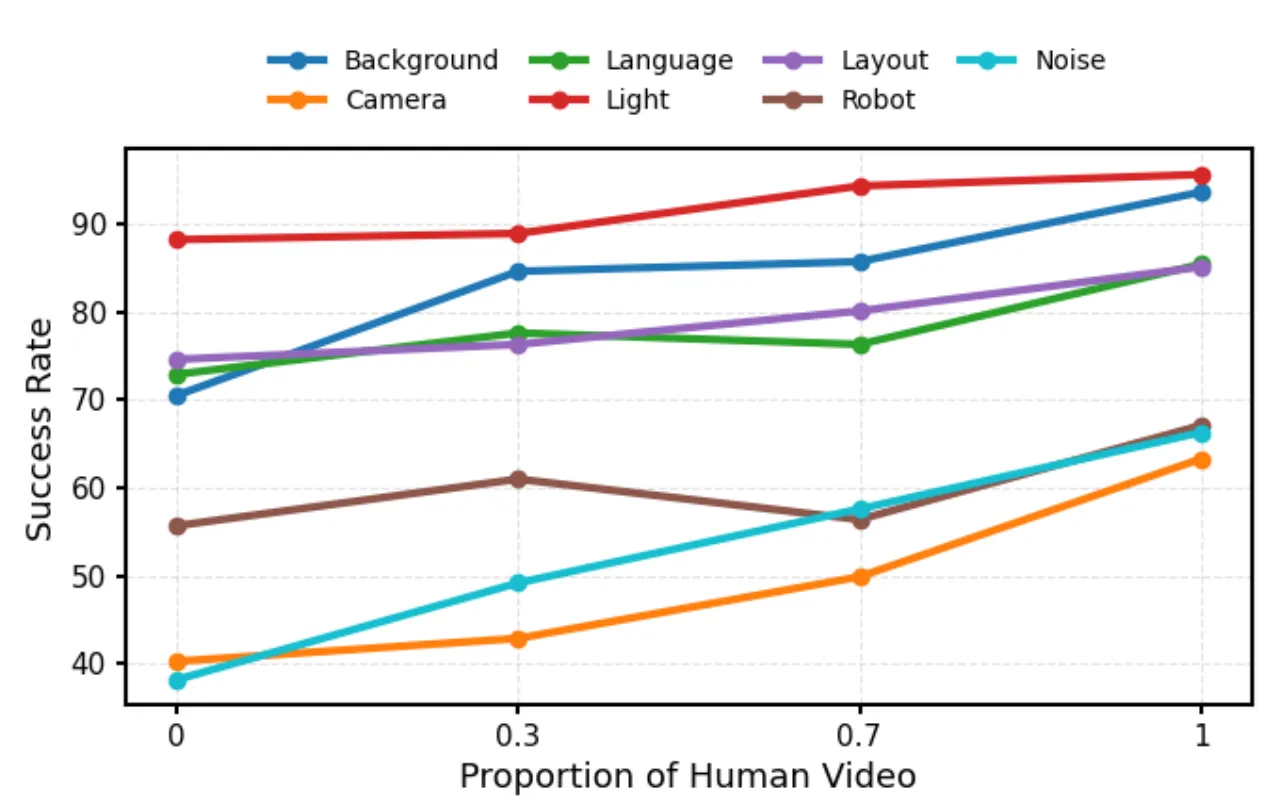
01 动机 Motivation
现有基于潜在动作预测的 VLA 预训练方法(如 LAPA、UniVLA)将优化目标锁定在像素级变化上,而非真正与控制相关的状态转移。这使得模型对相机抖动、背景变化等无关干扰极为敏感,难以在真实环境中稳健泛化。
"For embodied control, we want a value-bearing latent state that discards nuisance appearance while preserving factors governing state evolution."
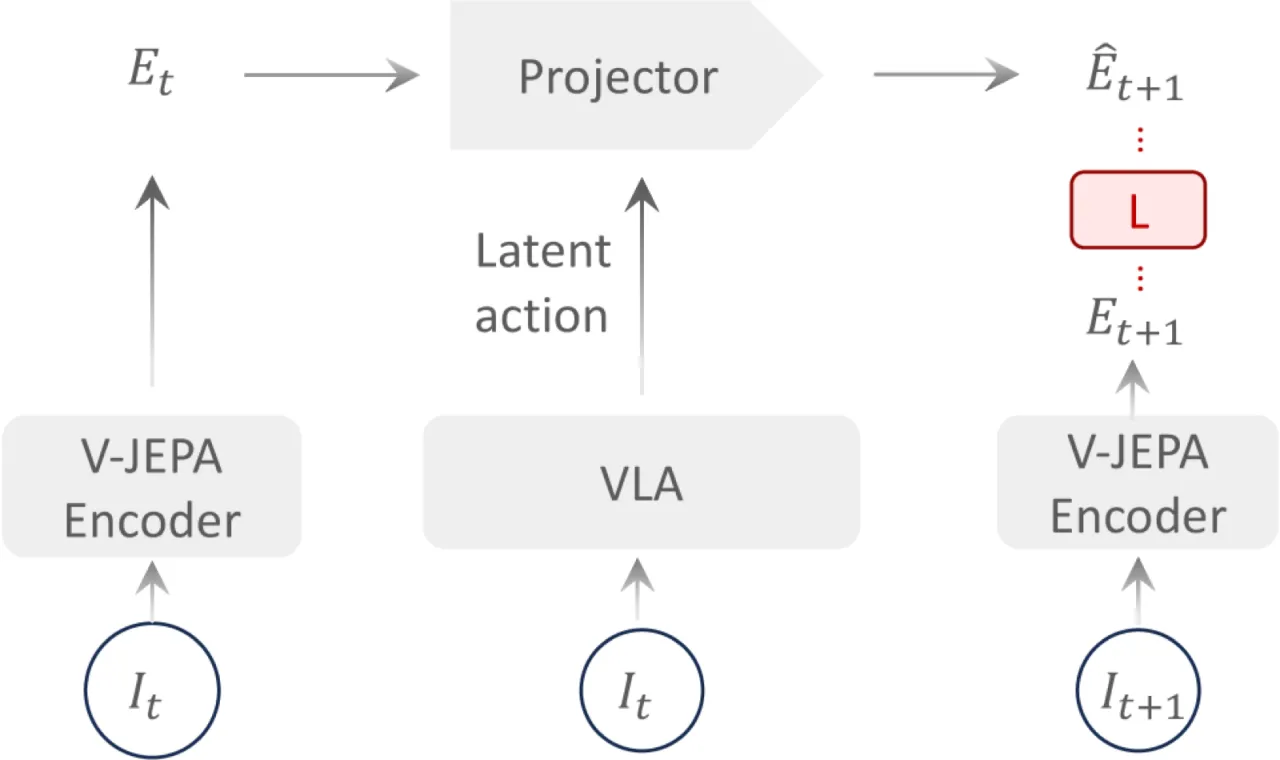
作者归纳了现有隐动作预训练的四类核心失效模式:
- 像素级偏置(Pixel-level bias):优化目标锁定像素差异,而非动作相关的状态转移;
- 干扰运动(Nuisance motion):真实视频中相机运动等无关信号被放大,遮盖了真正的交互信号;
- 信息泄漏(Information leakage):未来帧的特征在预测网络中提前泄露,形成捷径;
- 多阶段复杂性(Multi-stage complexity):三阶段以上的流程引入额外脆弱性。
97.2%LIBERO 平均成功率
65.2%SimplerEnv Google Robot avg
79.5%LIBERO-Plus 鲁棒性 avg
2-stage简化预训练流程