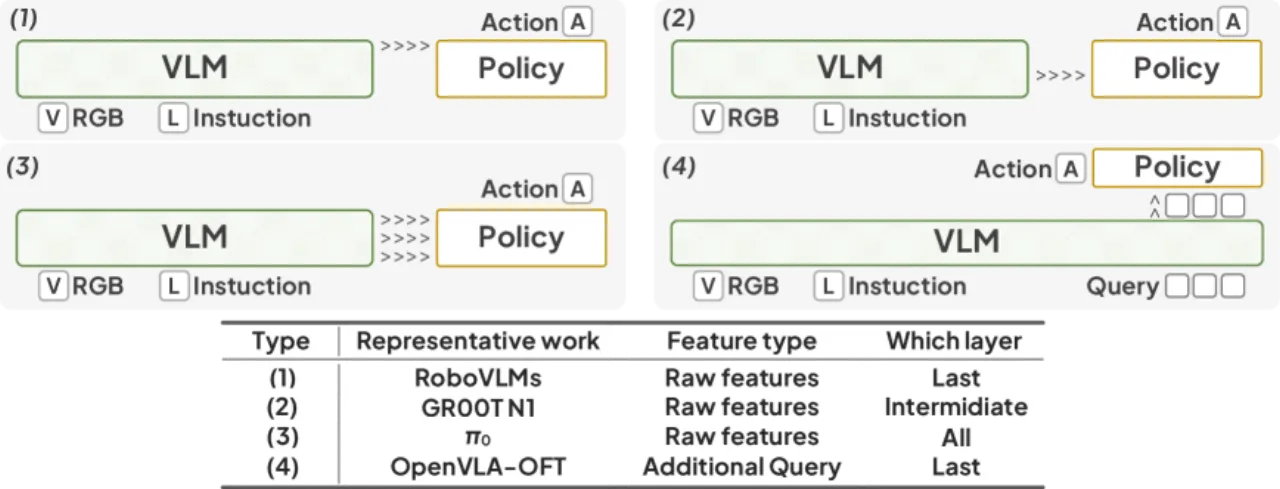
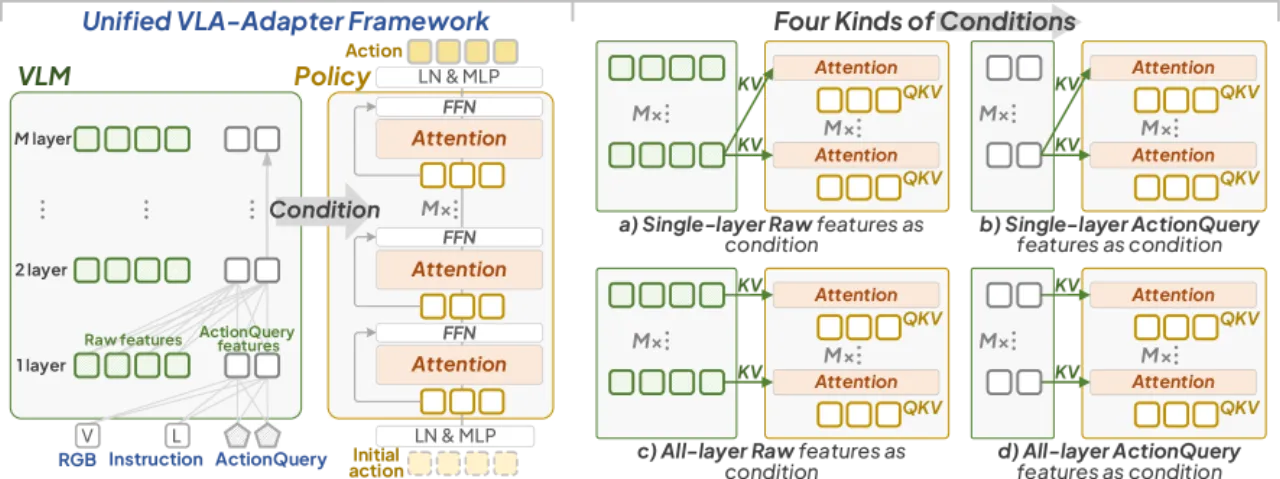
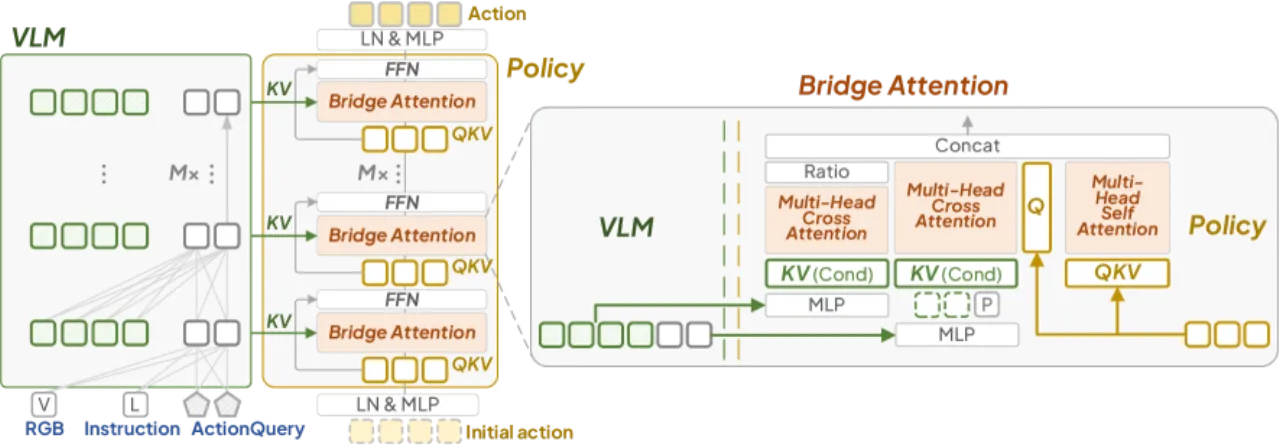
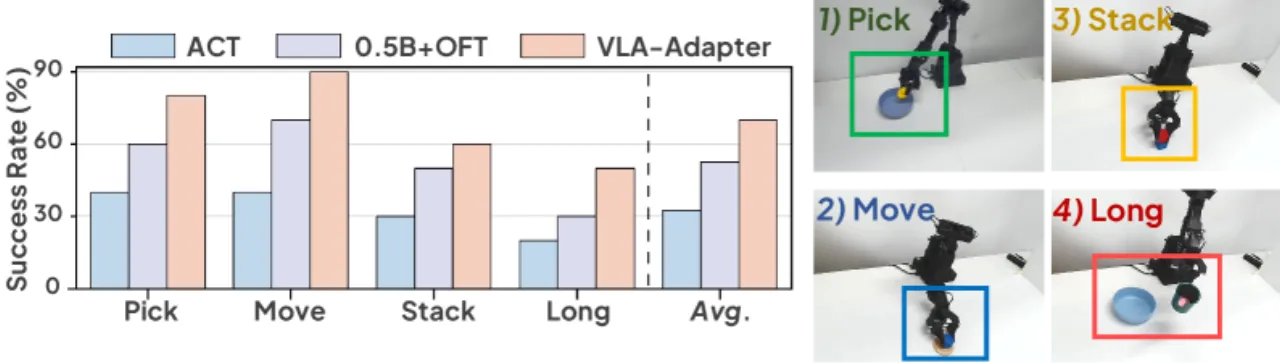
01 动机
现有 VLA 模型普遍依赖数十亿参数的视觉语言骨干(如 7B LLM)与大规模机器人预训练数据,导致训练成本高、推理延迟大,难以在消费级硬件上部署。本文的核心问题是:能否仅用一个微小的 VLM 骨干(0.5B),通过设计更好的 bridging 方式,达到甚至超越大模型的操作性能?
"We propose VLA-Adapter to reduce VLA's reliance on large-scale Vision-Language Models and extensive pre-training … achieving state-of-the-art performance using only a 0.5B-parameter backbone without robotic data pre-training."
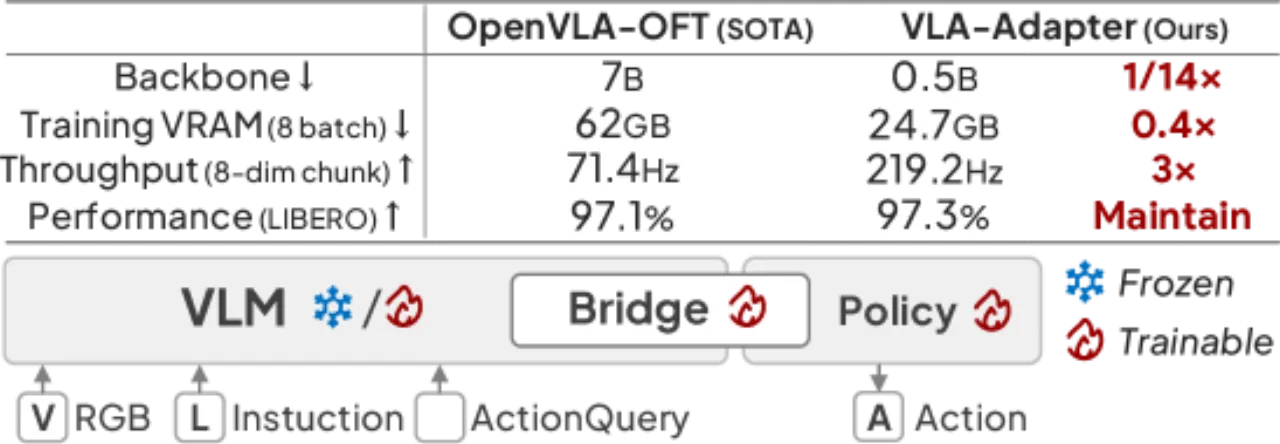
0.5B骨干参数量(vs 同类 7B)
97.3%LIBERO 平均成功率
219.2 Hz推理吞吐量(OpenVLA 仅 4.2 Hz)
8 h单块消费级 GPU 完整训练时长