01 动机
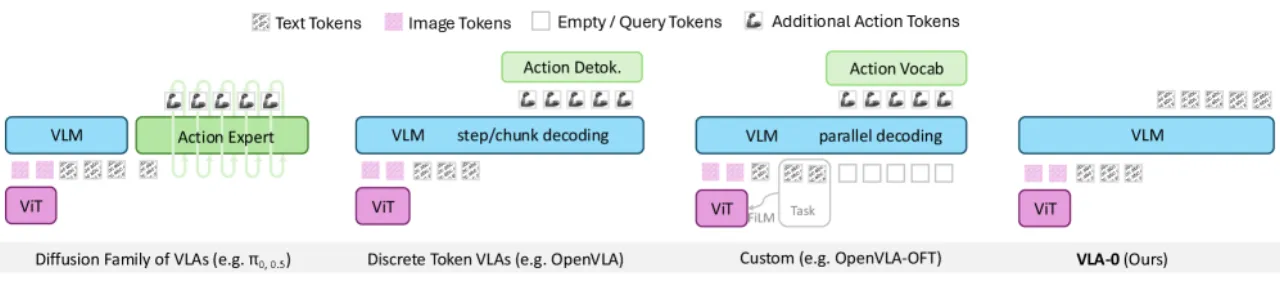
当前主流的 VLA(Vision-Language-Action)构建思路普遍需要对预训练 VLM 进行非平凡的架构改动:要么新增离散 action token(discrete token VLA),要么在 VLM 之上叠加专用 generative head,要么完全重设计网络结构。这些修改不仅复杂,还会破坏 VLM 原有的语言理解与 grounding 能力。
"It restricts the resolution of the action space, since fine-grained control can require thousands of bins, which conflicts with sharing the text vocabulary; and it compromises the pretrained language understanding of the VLM by repurposing its vocabulary for actions."
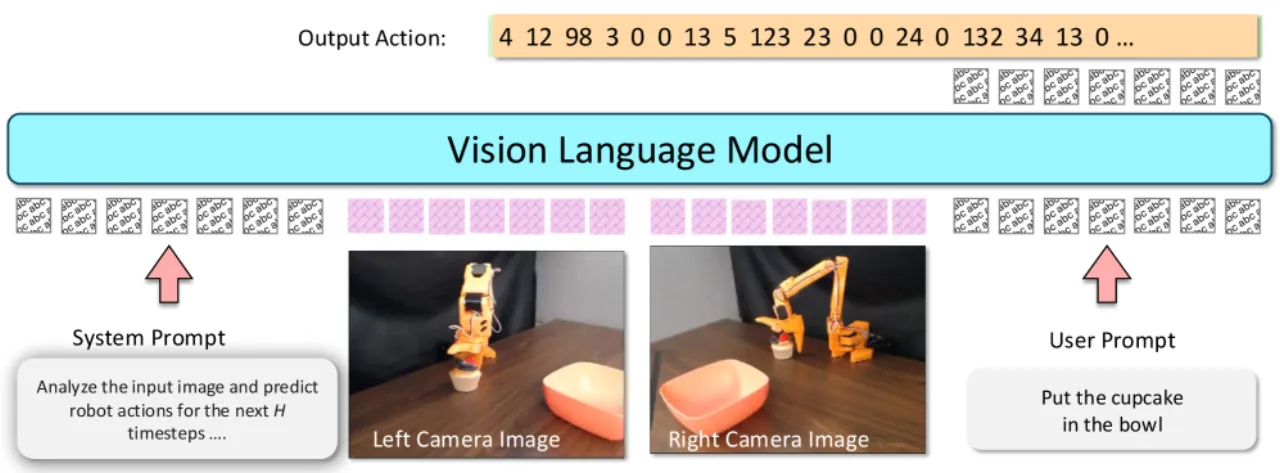
作者的核心问题是:能否在完全不修改模型架构的前提下,仅通过标准的 text generation fine-tuning,构建出性能领先的 VLA?VLA-0 给出了肯定答案。

94.7%LIBERO 平均成功率(无大规模预训练,Rank 1)
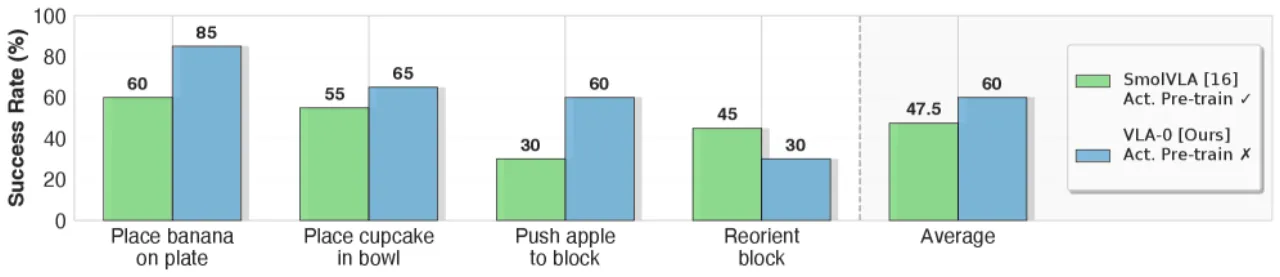
+12.5pts真实机器人 SO-100 上超越 SmolVLA
0架构修改数量(Zero Modification)
3B基础模型参数量(Qwen-VL-2.5-3B)