01 动机 Motivation
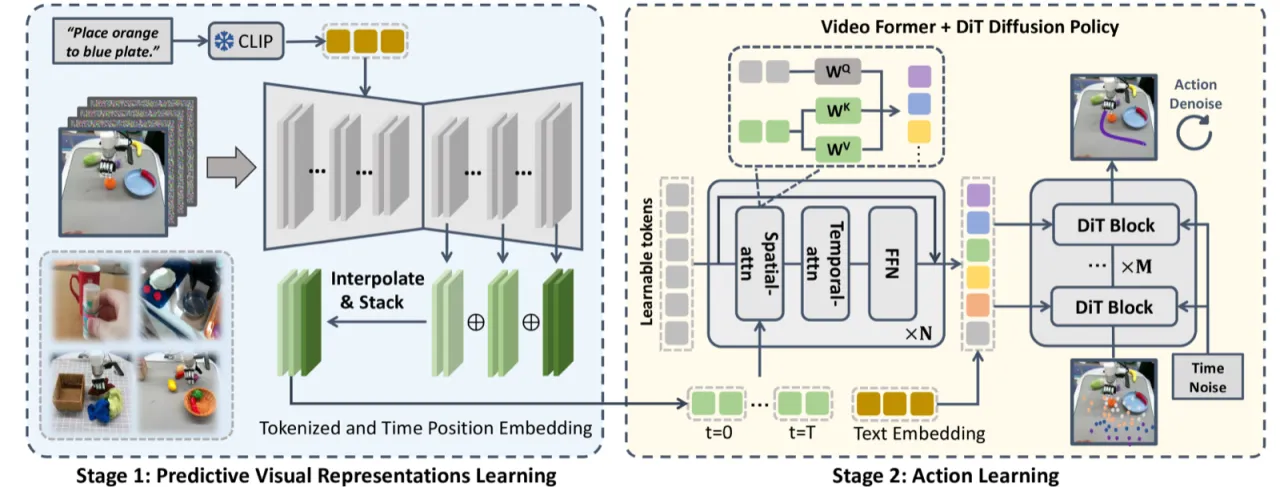
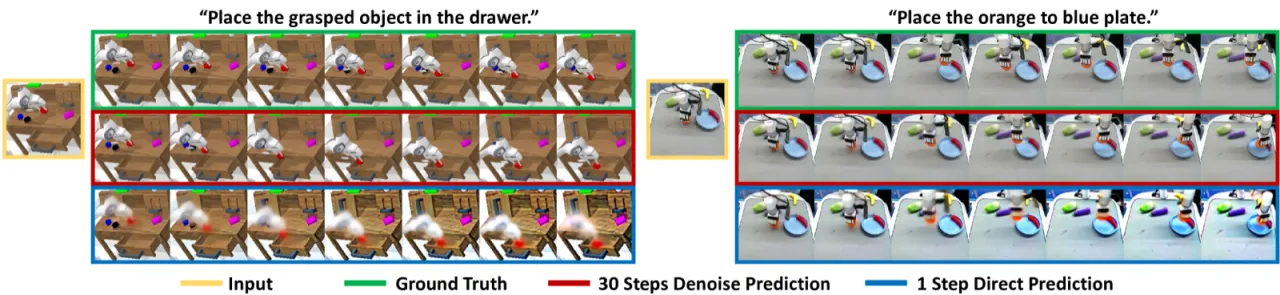
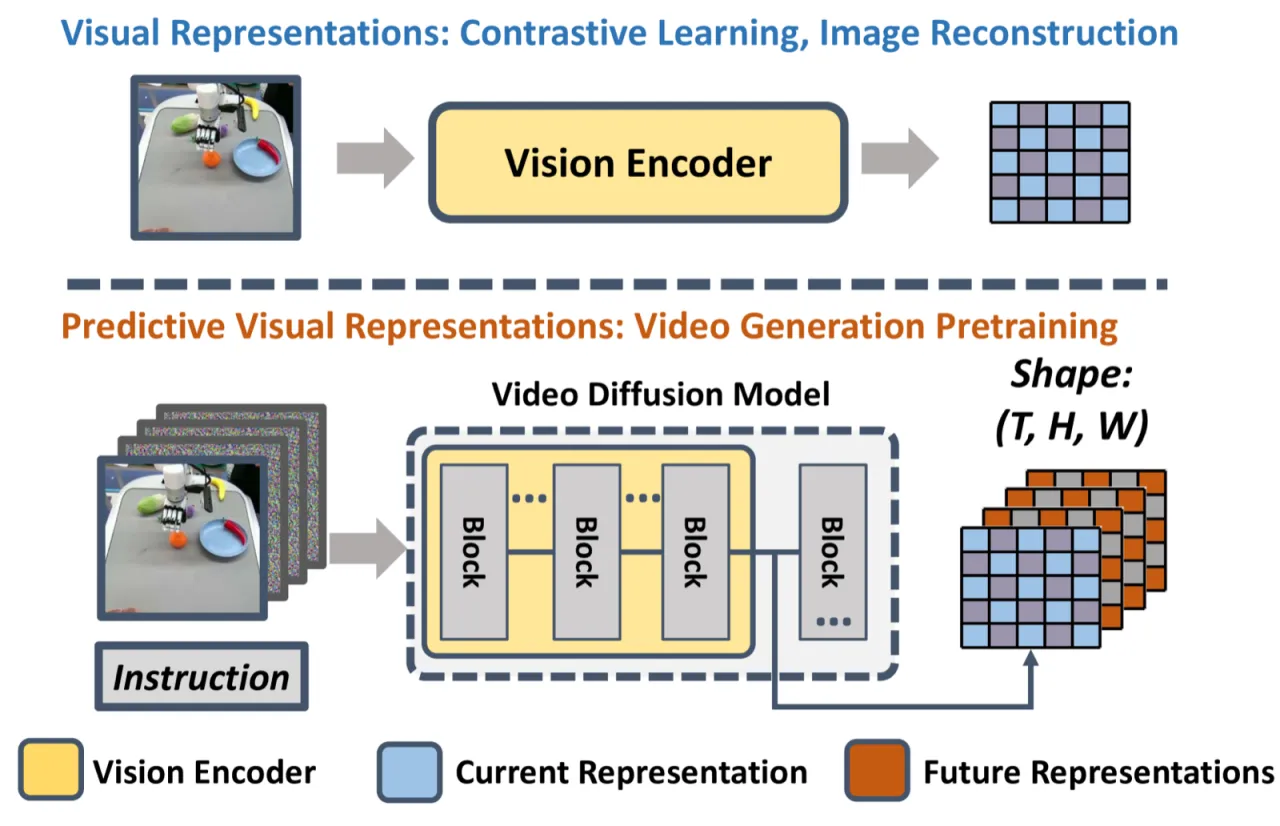
当前机器人视觉表征方法主要依赖单帧图像或两帧图像学习,忽视了具身任务中至关重要的动态信息。视频扩散模型(VDM)在大规模互联网视频上预训练,隐含地理解了物理世界的演化规律,但如何将这种"未来预见"能力转化为 robot policy 的视觉表征,尚无有效方案。
"We hypothesize that VDMs contain both current static information and predicted future dynamics, which can provide more comprehensive guidance for robot policy learning."
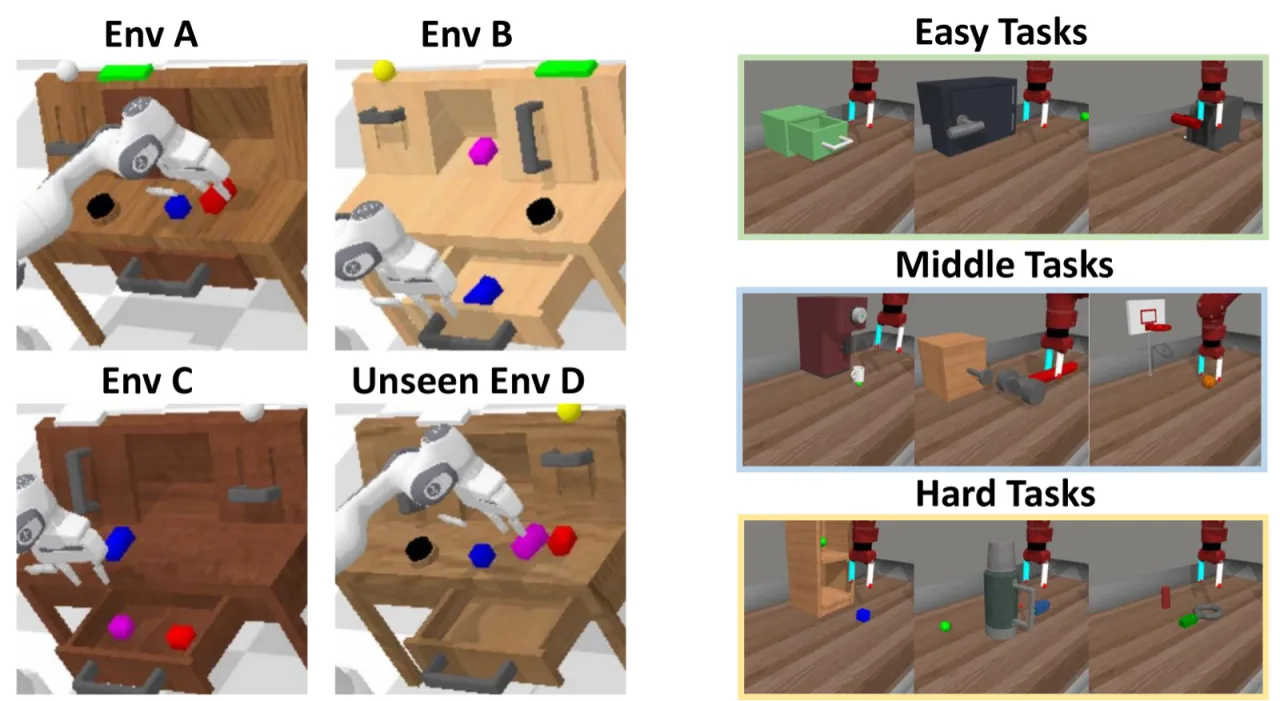
+18.6%CALVIN ABC→D 相对先前 SOTA 提升
+31.6%真实灵巧操作任务成功率提升
4.33CALVIN 平均完成任务数(先前 SOTA: 3.35)
1.5BVDM 基础模型参数量(Stable Video Diffusion)