01 动机 Motivation
当前 visuomotor policy 面临两大核心挑战:(1)在感知或行为分布偏移下泛化能力差;(2)性能高度依赖大规模人类演示数据集。这两点制约了机器人策略在真实场景中的可扩展性与鲁棒性。
"Despite tremendous progress in dexterous manipulation, current visuomotor policies remain fundamentally limited by two challenges: they struggle to generalize under perceptual or behavioral distribution shifts, and their performance is constrained by the size of human demonstration data."
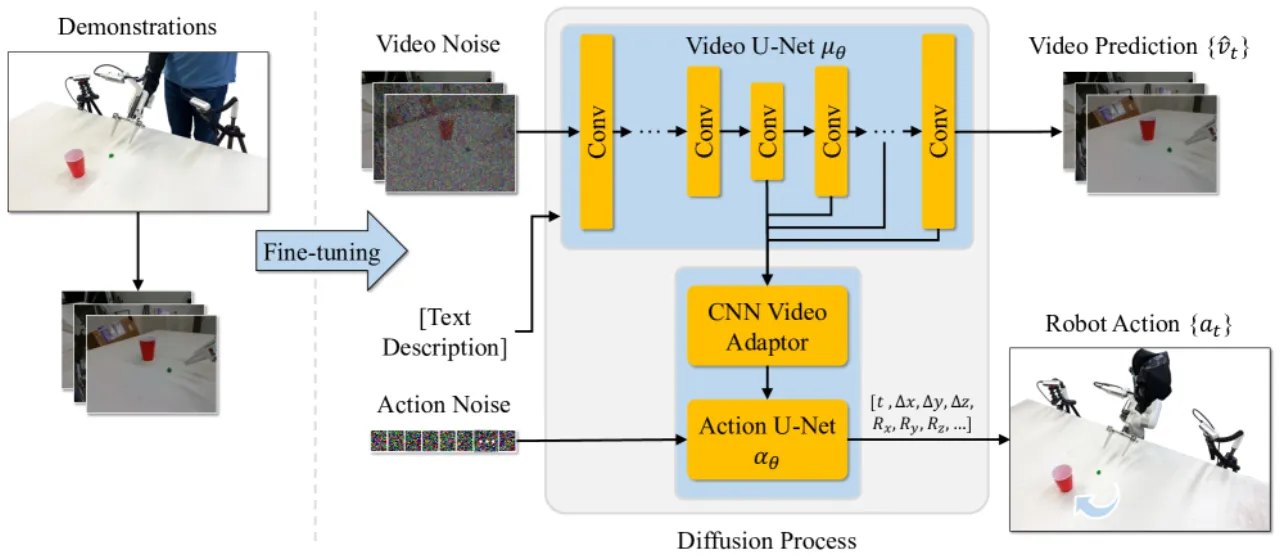
作者的核心观察是:视频生成是比动作生成更通用的目标。学会预测机器人执行任务的视频,可以从无动作标注的视频数据中学习环境动力学,进而以极少有动作标注的演示数据完成策略提取。这一思路将互联网规模的视频生成预训练引入机器人学习,提供近乎无限的动作无关数据来源。

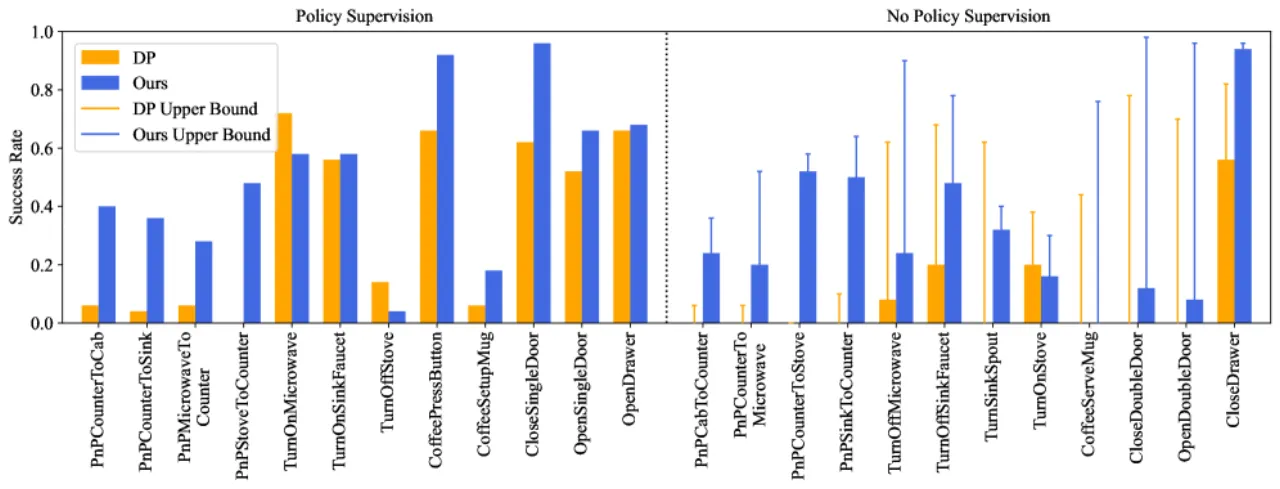
0.66RoboCasa avg. success (300 demos)
0.94Libero10 avg. success rate
50demos 即可超越多数 baseline
3×优于 GR00T (0.50 → 0.66)