Yilun Du · Mengjiao Yang · Pete Florence · Fei Xia · Ayzaan Wahid · Brian Ichter · Pierre Sermanet · Tianhe Yu · Pieter Abbeel · Joshua B. Tenenbaum · Leslie Kaelbling · Andy Zeng · Jonathan Tompson | Google DeepMind · MIT · UC Berkeley
VLP(Video Language Planning)提出将 vision-language model(VLM)与 text-to-video model 组合,通过树搜索在视频与语言构成的联合空间中规划长时序机器人任务。VLM 同时充当策略(生成文字动作)和价值函数(评估视频进度),text-to-video model 充当动力学模型,在推理时以更多算力换取更高质量的视频计划。
"We are interested in enabling visual planning for complex long-horizon tasks in the space of generated videos and language, leveraging recent advances in large generative models pretrained on Internet-scale data."
VLP 以三个模块为核心:(1)VLM as Policy——根据当前图像和语言目标生成候选文字动作;(2)Video Model as Dynamics——将文字动作转化为合成的短时视频帧;(3)VLM as Heuristic Function——预测距离目标完成还需多少步,用于剪枝。三者通过树搜索(beam search + parallel hill climbing)组合,在推理时可用更多计算换取更好的视频计划质量。
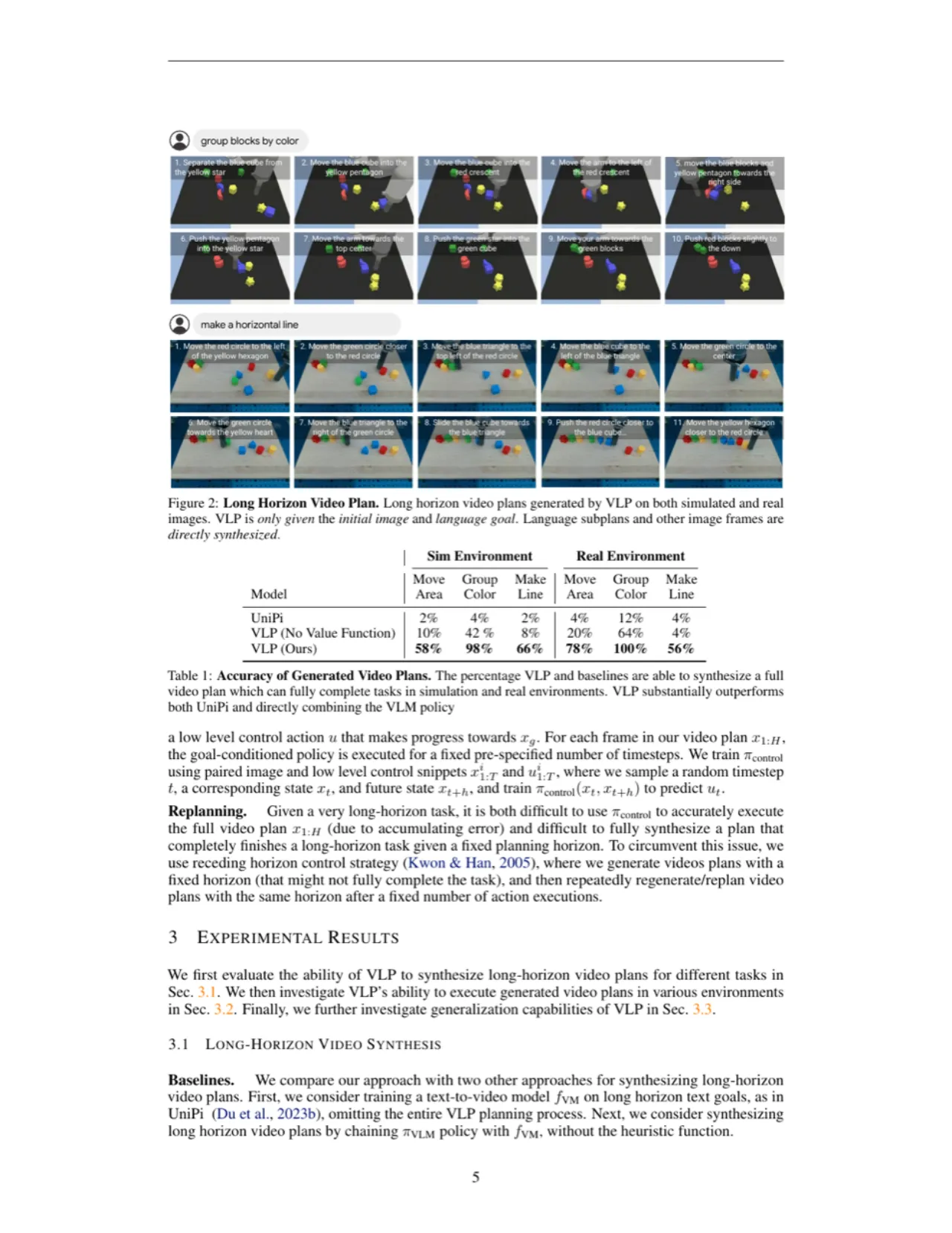
图 2:长时视频计划示例。 VLP 仅给定初始图像和语言目标,自主生成语言子目标序列(左侧列表)和对应视频帧序列(右侧图像),涵盖仿真 Language Table 环境(上)和真实桌面(下)两种场景。
VLM as Policy & Heuristic Function
VLP 使用 PaLM-E 作为 VLM。给定图像 x 和语言目标 g,policy πVLM(x, g) 采样出 A 个候选文字动作 a。heuristic function HVLM(x, g) 在长轨迹片段上微调,输出"距目标还需几步"的标量估计——取负值作为启发值(越接近目标值越大)。为防止动力学模型被"利用"(exploiting model dynamics),若某视频帧的启发值超过固定阈值则直接丢弃。
Text-to-Video Model as Dynamics
给定当前帧 x 和文字动作 a,视频模型 fVM(x, a) 合成一段短时视频 x1:S,预测执行该动作后的视觉结果序列。长时计划通过自回归拼接(递归将最后一帧作为新起点)延伸至数百帧。对多相机双臂平台(ALOHA),各视角视频在 channel 维度拼接后联合生成,保证多视角一致性。
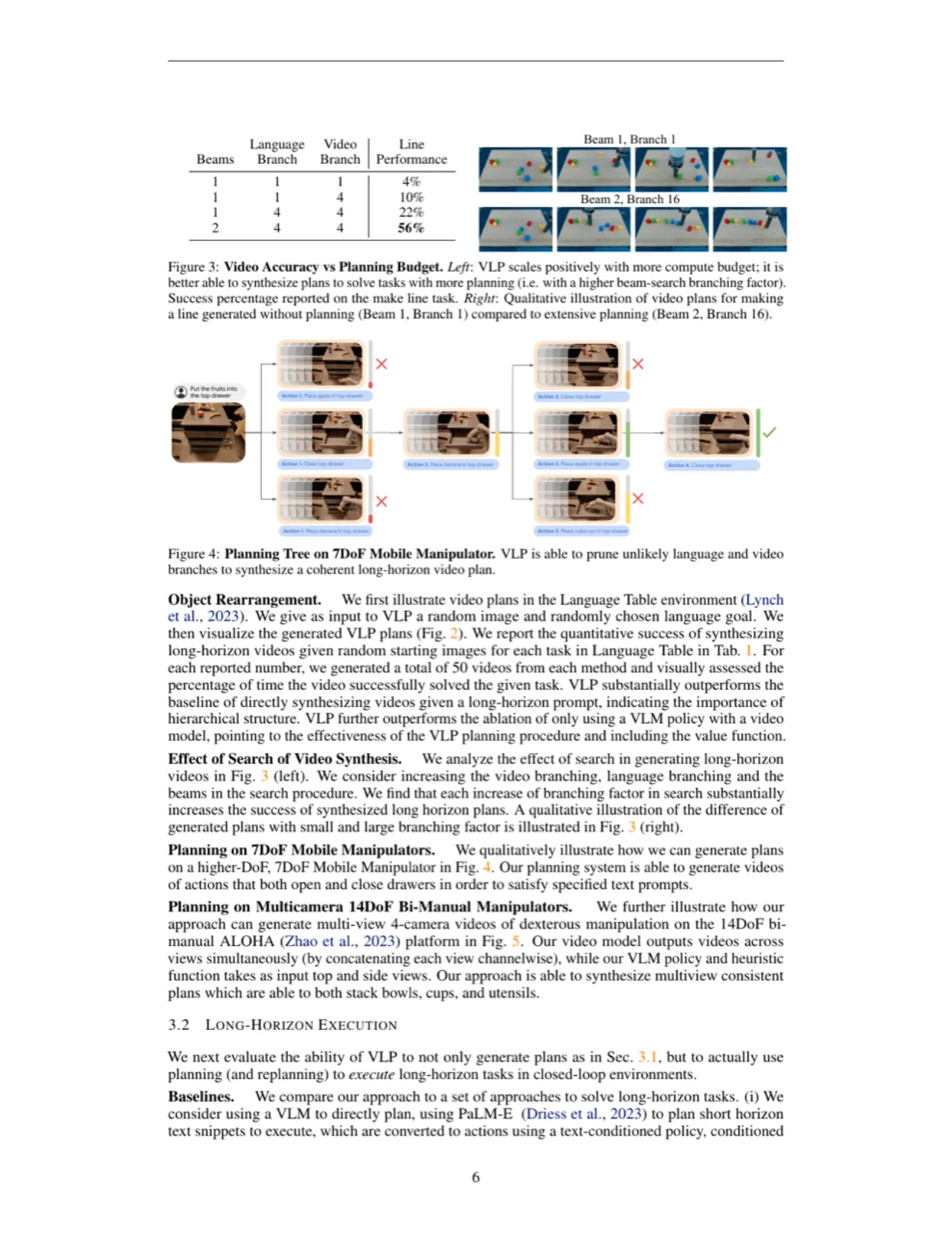
树搜索规划算法(Algorithm 1)
初始化 B 条平行规划 beam。每一步:① πVLM 为当前帧生成 A 个动作;② fVM 对每个动作合成 D 个视频分支(共 A×D 个);③ HVLM 打分,选最高分视频加入当前 beam;④ 每 5 步,用最高分 beam 替换最低分 beam。最终输出 HVLM 得分最高的 beam 对应的视频计划。
图 5:仿真(左)与真实机器人(右)执行展示。 VLP 在仿真 Language Table 环境中完成"将所有方块移至左下角"、"按颜色分组"、"排成一横行"三类长时序任务;在真实机器人上同样成功执行相同任务。
泛化能力
当 VLM 和 video model 在大规模 Internet 数据(含 YouTube 视频)上联合预训练后,VLP 能够泛化到:(i)训练集中未见过的新物体(如橡皮圈、纸杯蛋糕、木质六边形);(ii)不同光照条件下的新环境;(iii)新任务指令(如"Pick snicker energy bar"、"Move moose toy near green pear")。这种泛化能力来自将视频合成与低层控制解耦——video model 负责视觉动力学泛化,goal-conditioned policy 只需泛化到邻近视觉目标。
04 局限性
说明:以下局限性均为论文作者在 Section 5 "Limitations and Conclusion" 中明确陈述(stated),无推断内容。
图像表征无法捕捉完整三维状态
"Our planning approach leverages images as a world state representation. In many tasks, this is insufficient as it does not capture the full 3D state and cannot encode latent factors such as physics or mass." 论文提出的缓解方向:生成多视角视频,或让 heuristic function 以完整视频为输入。
视频动力学模型存在物理幻觉
"we observed that our video dynamics model does not always simulate dynamics accurately. In several situations, we observed that synthesized videos would make objects spontaneously appear or teleport to new locations."(物体凭空出现或瞬移)论文建议使用更大的 video model、更多训练数据、或引入显式强化学习反馈(如 RLHF for physics)来缓解。