Yulu Gao*, Bohao Zhang*, Zongheng Tang, Jitong Liao, Wenjun Wu, Si Liu — Beihang University / Hangzhou International Innovation Institute of Beihang University
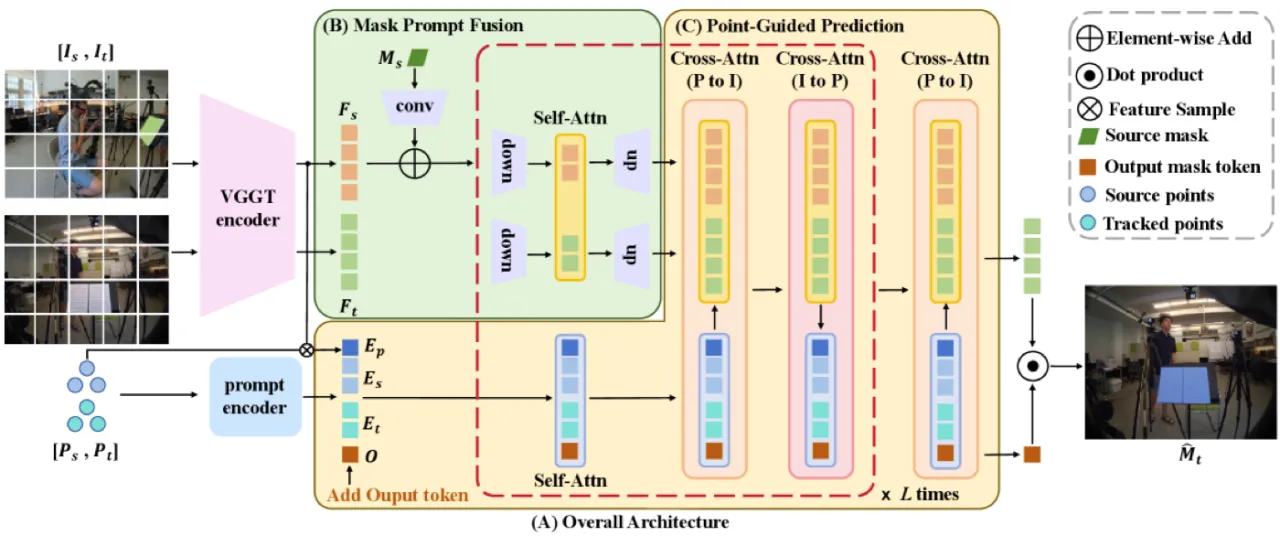
VGGT-Segmentor(VGGT-S)将 VGGT 的几何感知跨视角特征表示与全新的 Union Segmentation Head 相结合,
解决 ego–exo 场景下直接像素投影产生的系统性漂移问题,实现精确的实例级跨视角分割。
在 Ego–Exo4D 基准上,VGGT-S 分别达到 67.7%(Ego→Exo)
和 68.0%(Exo→Ego)的 average IoU,大幅超越此前最优方法。
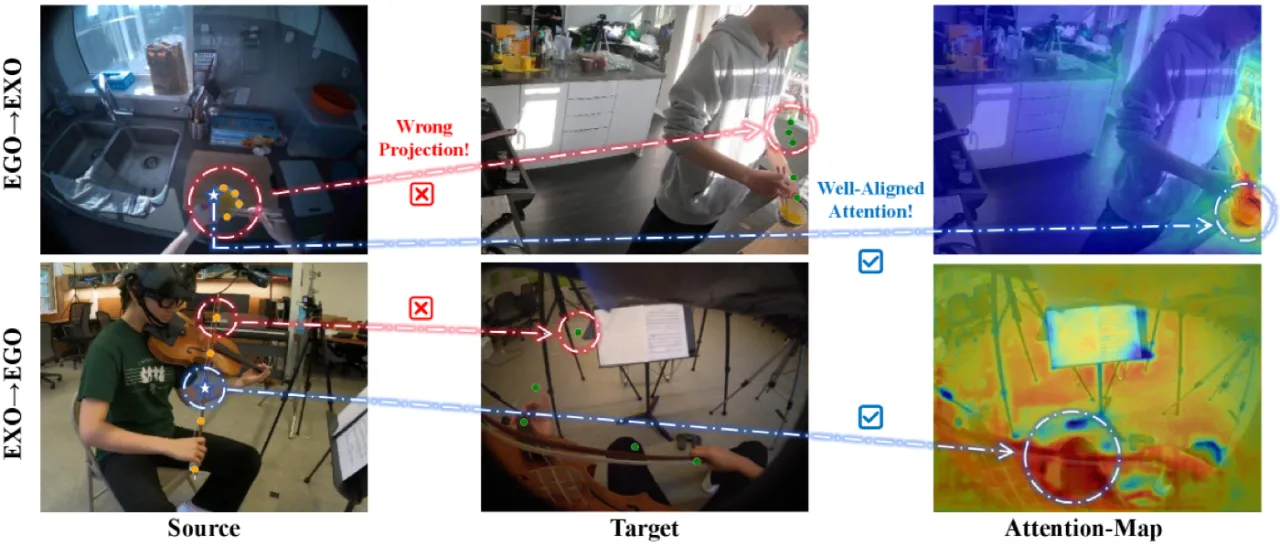
在 ego(第一人称)与 exo(第三人称)视角之间定位并分割同一实例是 embodied AI 和远程协作的核心挑战。
由于视角、尺度与遮挡的剧烈变化,直接在像素级别进行匹配极其困难。
"While recent geometry-aware models like VGGT provide a strong foundation for feature alignment,
we find they often fail at dense prediction tasks due to significant pixel-level projection drift,
even when their internal object-level attention remains consistent."