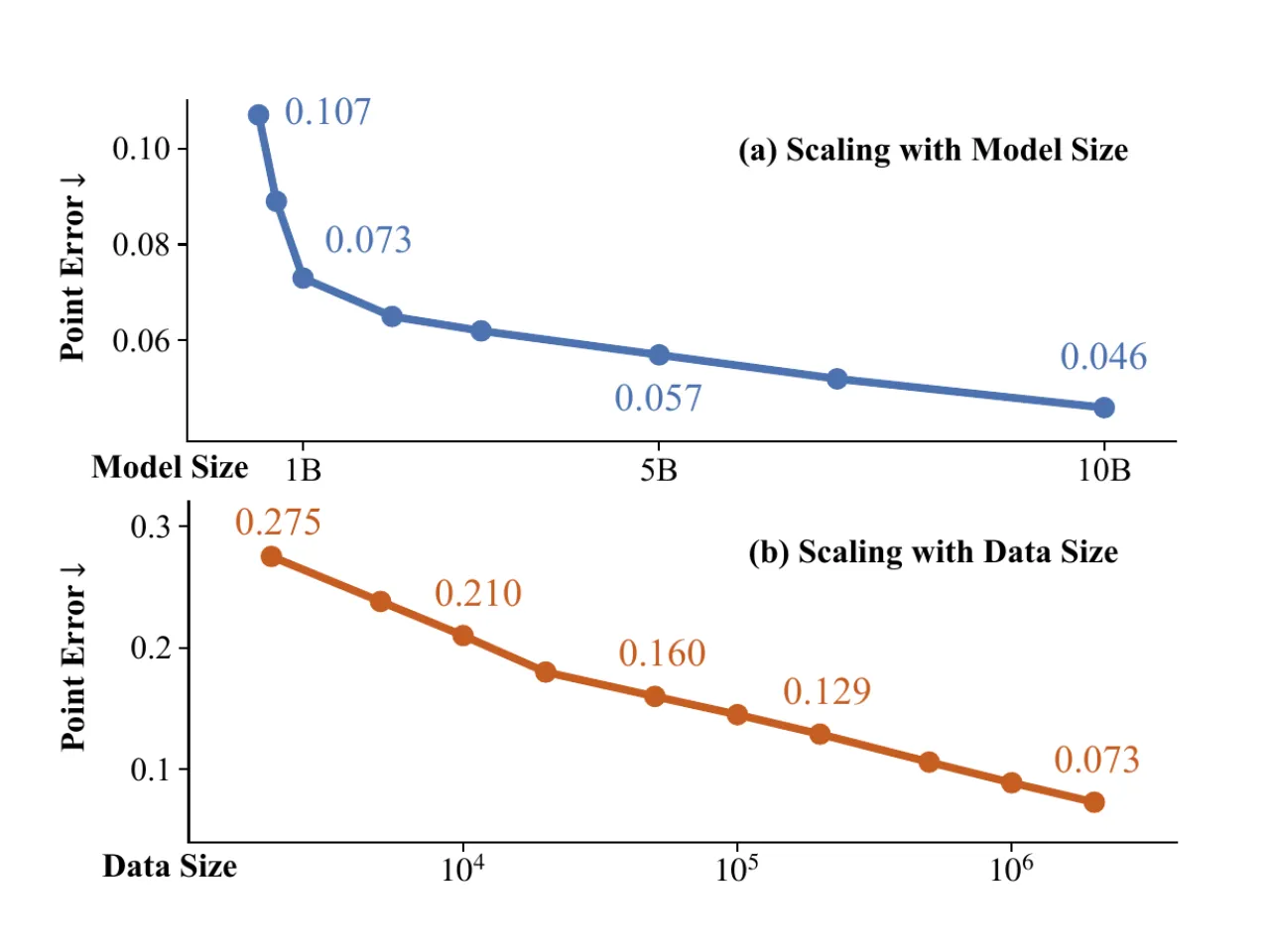
02 方法
VGGT-Ω 是一个前馈 Transformer f,将 N 张图像映射为相机 旋转四元数 q平移 t视场角 f 与深度图 D。与 VGGT 不同,模型不直接预测点图或 tracking 特征(但仍以损失监督它们)。
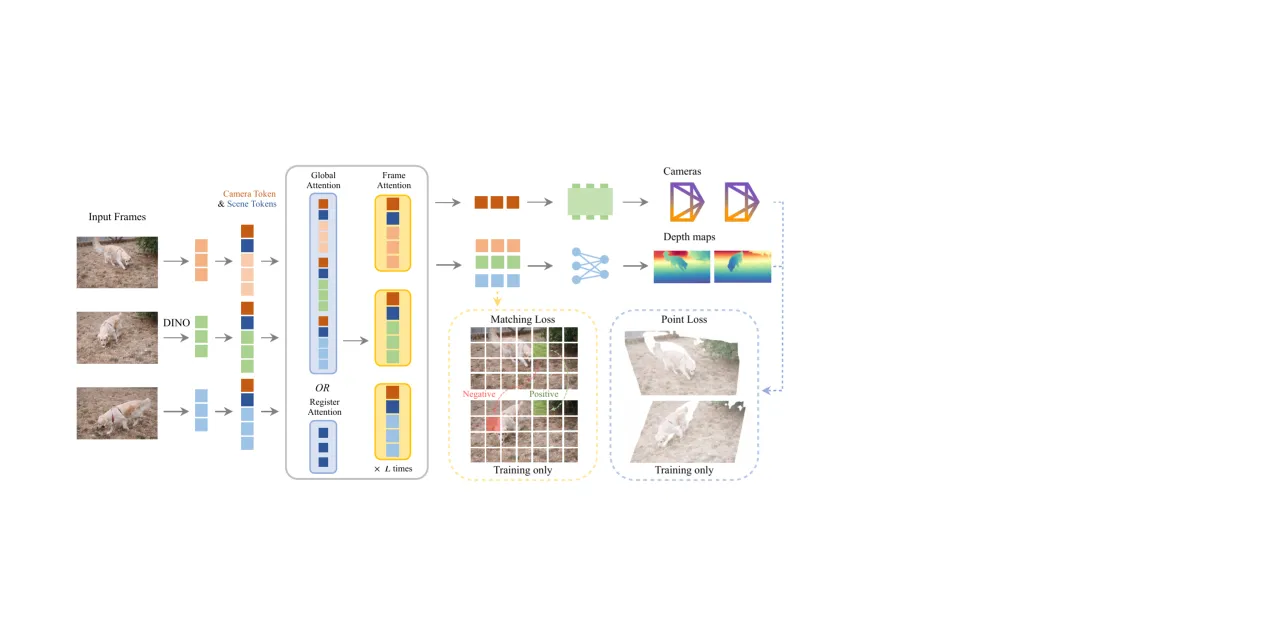 架构。每张图用 DINOv3 初始化的 ViT 编码,并附加每帧 1 个相机 token 与 16 个寄存器(场景 token)。通过「逐帧 ↔ 全局」交替注意力跨视角聚合特征,再用轻量级 head 解码出深度与相机。
架构。每张图用 DINOv3 初始化的 ViT 编码,并附加每帧 1 个相机 token 与 16 个寄存器(场景 token)。通过「逐帧 ↔ 全局」交替注意力跨视角聚合特征,再用轻量级 head 解码出深度与相机。
改进一 · Register Attention(寄存器注意力)
VGGT 交替使用逐帧自注意力与全局自注意力。「全局注意力是 VGGT 的主要计算瓶颈,但其注意力图非常稀疏」——这暗示少量 token 就足以交换相应信息。
因此 VGGT-Ω 把 25% 的全局注意力层替换为 register attention,在这些层里「帧间的信息交换被限制在寄存器之间」。更新后的寄存器随后在逐帧注意力块中与各帧图像 token 交互,「从而形成一个聚合并重新分发多帧信息的瓶颈」。本文也把这些寄存器称为「场景(scene)token」。
 全局注意力图通常高度稀疏,支撑「少量 token 即可交换信息」的设计直觉。
全局注意力图通常高度稀疏,支撑「少量 token 即可交换信息」的设计直觉。
两大收益
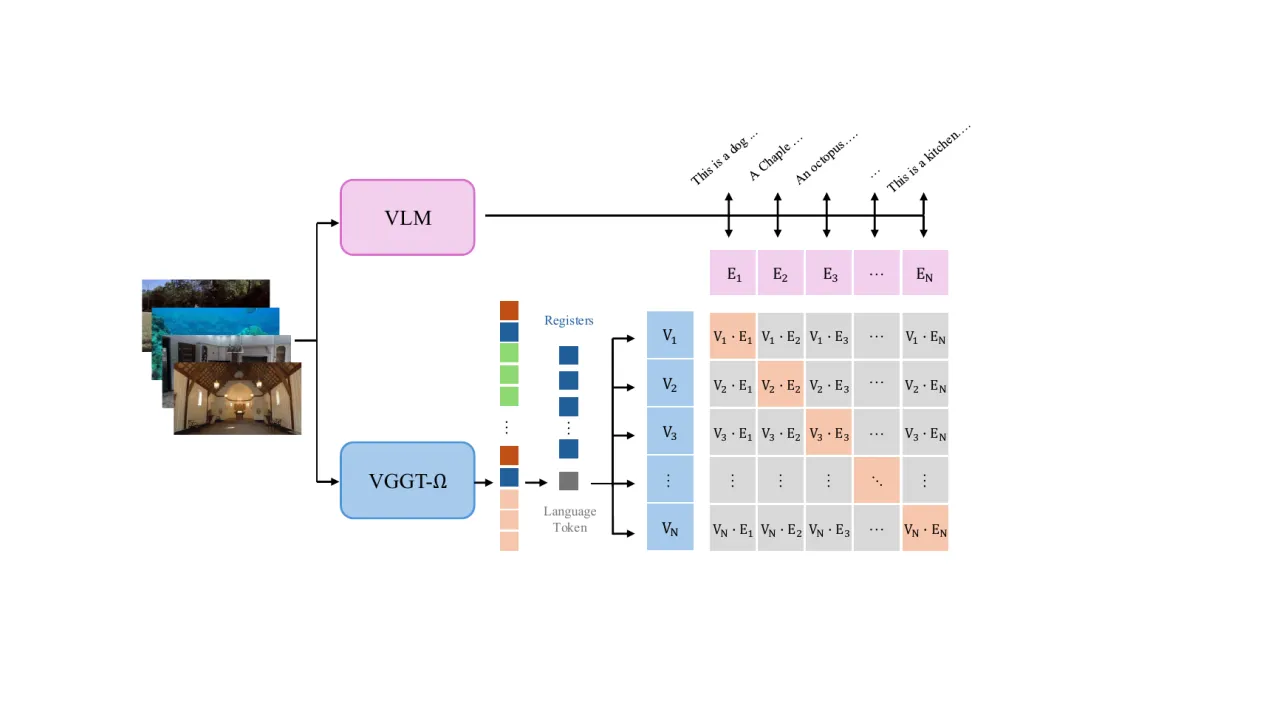
- 寄存器携带有用的全局信息。不同于「把寄存器当作辅助、推理时丢弃」的架构,这里它们「无需显式监督,就能为 VLA 模型和语言对齐提供有用特征」。
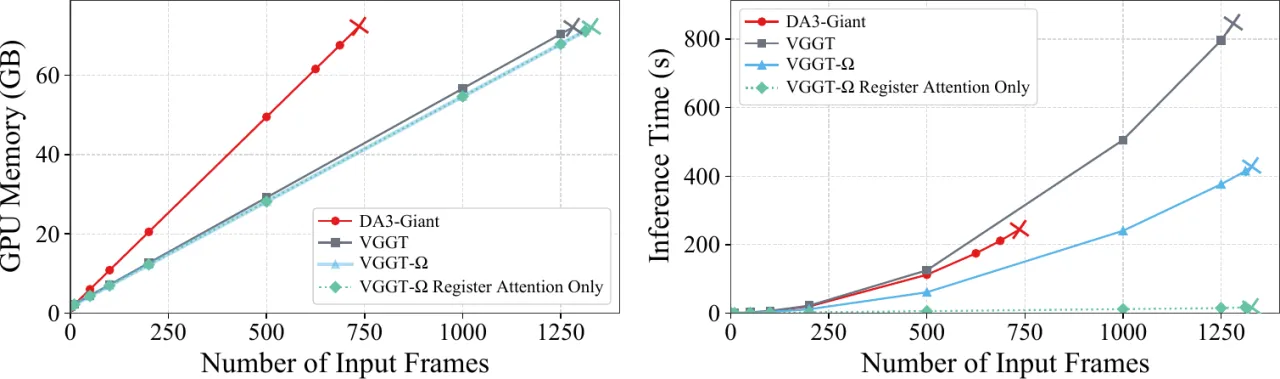
- 效率。「替换 25% 全局注意力层为 register attention,没有可测量的性能下降,同时在训练中节省约 23% FLOPs 和 16% 显存。」
(若替换全部全局层,FLOPs 降至原来的 6%,但性能显著下降。)
改进二 · 轻量级密集头(去掉昂贵的高分辨率卷积)
「密集预测头(如 DPT)中的高分辨率卷积层,尽管只占模型很小一部分参数,却为存储前向激活消耗了不成比例的 GPU 显存。」1/4 分辨率以上的卷积块被替换为「单个 MLP + pixel-shuffle 的轻量上采样头,显存极省且性能不降」。
纯卷积-free 解码器在 benchmark 上表现很好,但在室外场景产生方块伪影,因此保留了计算开销极小的早期低分辨率 DPT 卷积。
改进三 · 单一密集头 + 多任务损失
「我们仍使用多任务损失,但只保留一个深度密集头和一个稀疏相机头。」模型虽不直接输出点图和 tracks,但仍以损失监督它们。训练损失包含:
- 相机损失 —— ℓ1(「比 VGGT 使用的 Huber 损失更稳定」)。
- 深度损失 —— aleatoric 不确定性 + 梯度一致性项 + 相对尺度。
- 点图损失 —— 与深度损失同形,残差来自预测深度+相机的反投影。
- 匹配损失 —— 拉近正样本 token 对(同一 3D 位置)的特征、推开负样本。
「这三项改造合计节省 70% 训练显存,并略微提升推理速度。」
动态场景重建
处理动态内容「解锁了数量级更多的互联网式视频用于训练」。模型「只预测深度图与相机参数,避免运动掩码等显式动态输出」。ray map 被否决,因为它「增加昂贵的稠密输出,并会把相机信息与逐像素外观变化纠缠在一起」——例如固定相机拍摄一名舞者,画面运动很大但相机参数不变。期望数据驱动的模型自己学到比手工低秩/局部刚性约束更好的运动先验。
自监督训练(Teacher–Student)
借鉴 DINO 风格的动量教师-学生方法。两个网络都从监督训练好的 VGGT-Ω checkpoint 初始化,对同一组帧施加独立增强(颜色抖动、模糊、随机 90° 旋转、patch 遮挡、帧序打乱)。对齐到统一帧序后,student 通过跨层 ℓ2 特征匹配损失 + 相机/深度回归损失匹配 teacher;teacher 用 EMA 更新,且「相机与深度头在自监督期间冻结」以防坍塌。以此在 1800 万段无标注视频上训练。