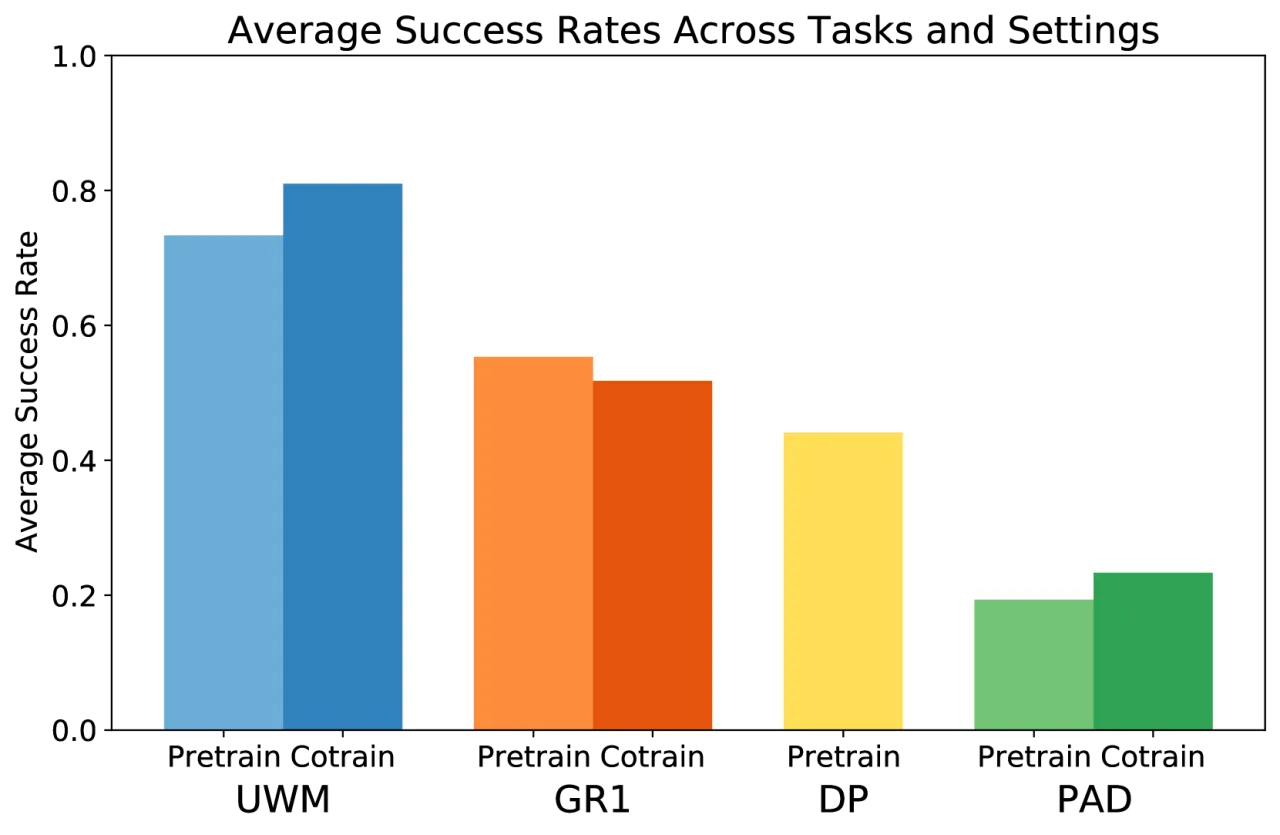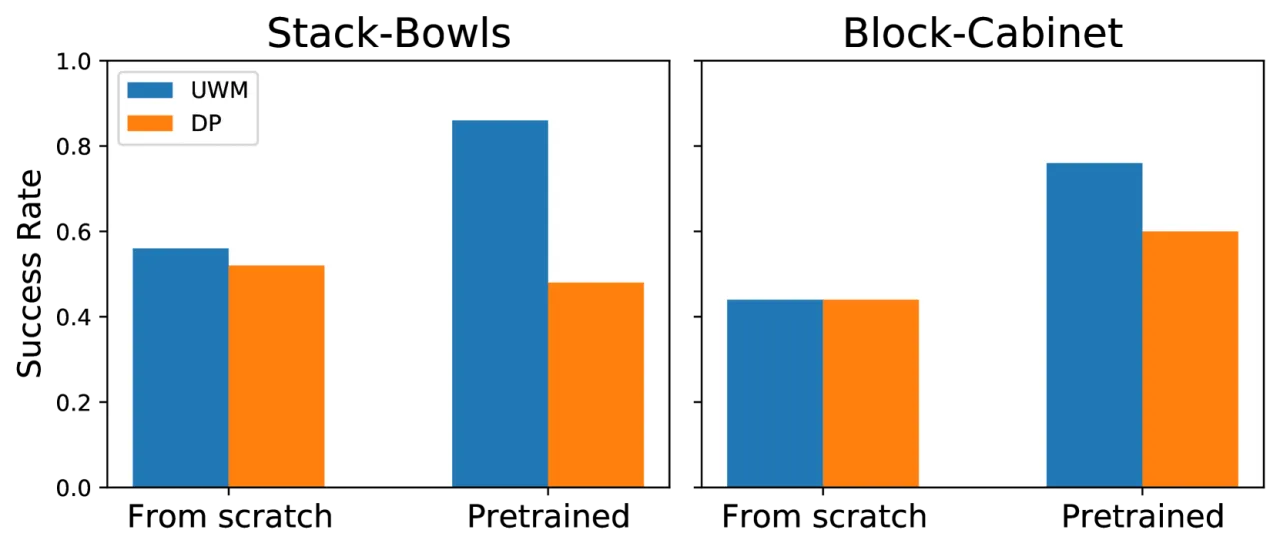01 动机
机器人学习的核心挑战在于:带动作标注的数据十分稀缺,而无标注的视频却海量存在。现有方法要么专注于行为克隆(忽略了大量无动作视频),要么单独训练视频预测模型再桥接到策略,难以在同一框架中统一这两类监督信号。此外,将动力学模型与策略分开训练会导致信息割裂,错失互相强化的机会。
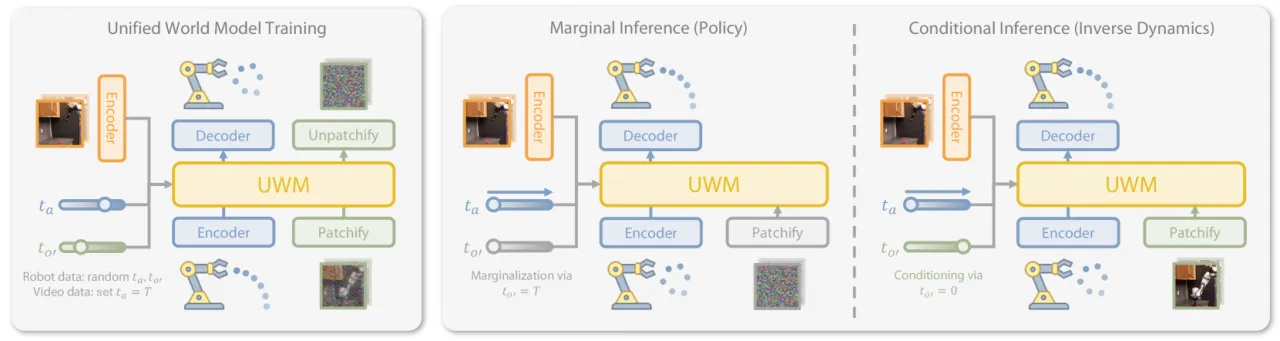
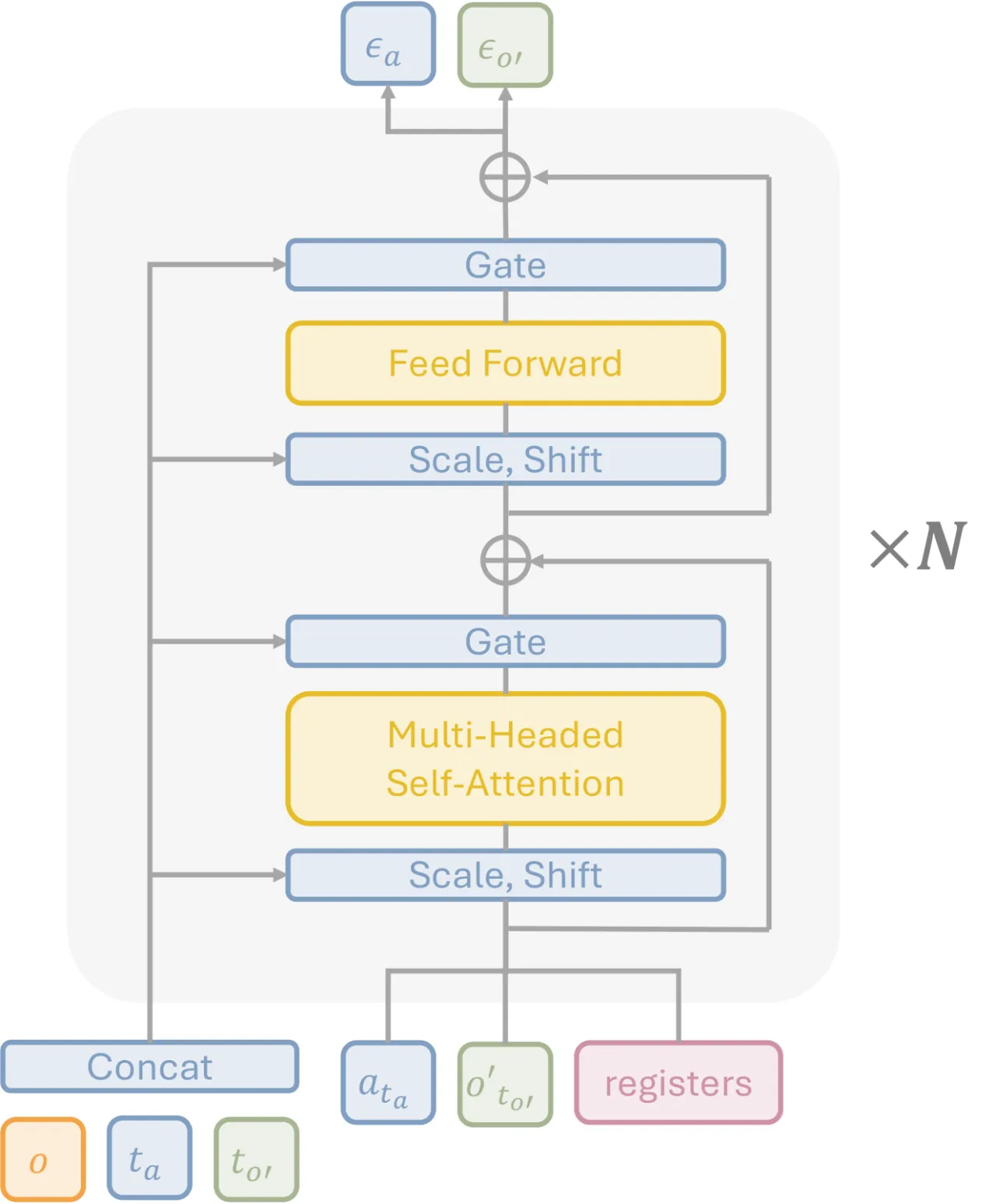
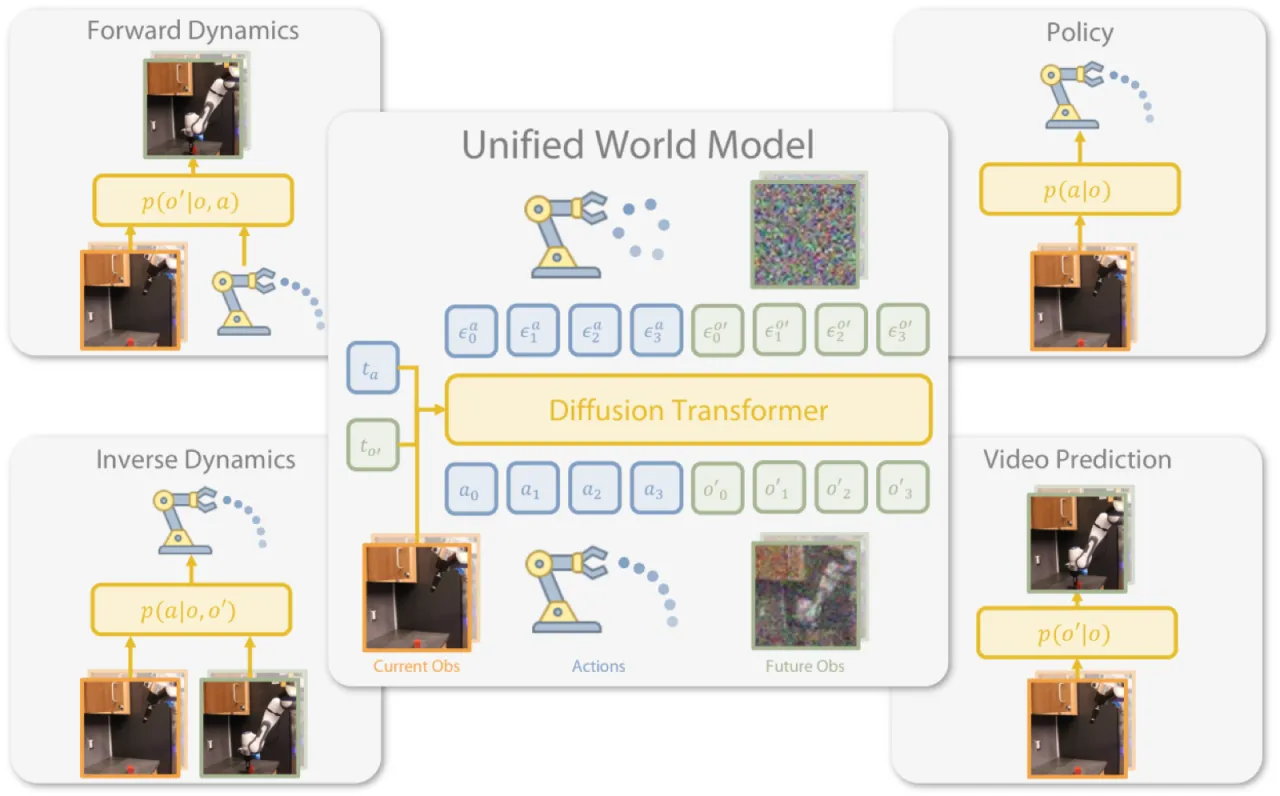
"We propose Unified World Models (UWM), a framework that integrates an action diffusion process and a video diffusion process within a unified transformer architecture, where each modality is independently controlled by its own diffusion timestep."
+20%真实机器人 OOD 成功率(相对 Diffusion Policy 最大提升)
0.79LIBERO 仿真均值成功率(UWM),DP 为 0.71
4 种推断模式(policy / video / forward / inverse dynamics)
2000无动作视频数据(DROID)用于 co-training 进一步提升性能