01 动机(Motivation)
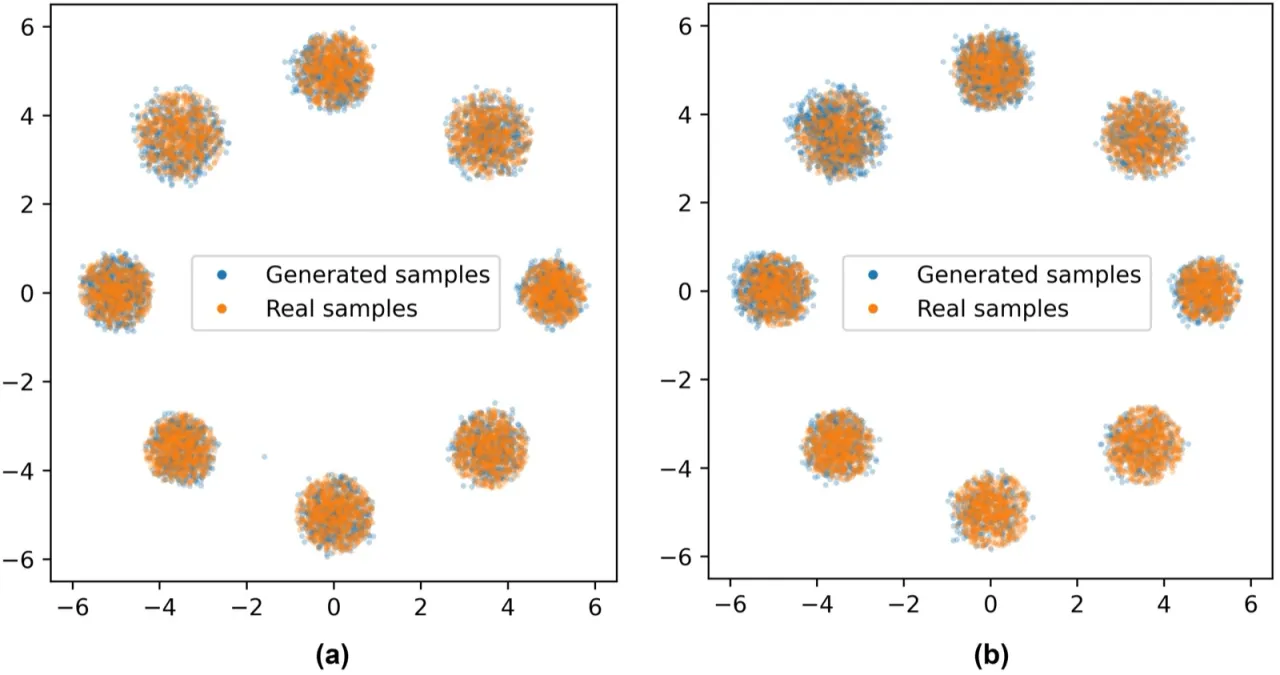
生成模型(Generative Models)已广泛应用于粒子物理、天气预报、医疗等高风险领域。 然而,现有所有评估指标——FID、IS、Precision-Recall 等——仅测量学习分布与目标分布的"距离", 却完全忽视了这种测量本身蕴含的不确定性。一旦分布对齐偏差微小,就可能导致错误的科学结论或不可靠的预测。
"No work quantifies the confidence in the measured closeness between the learned and target distributions." —— 论文原文
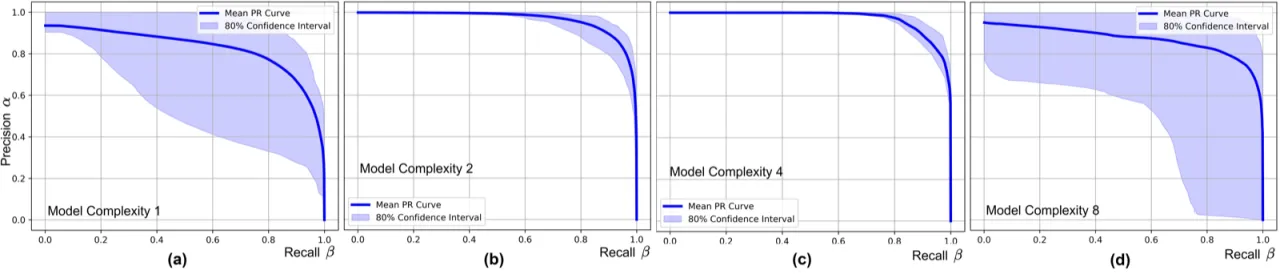
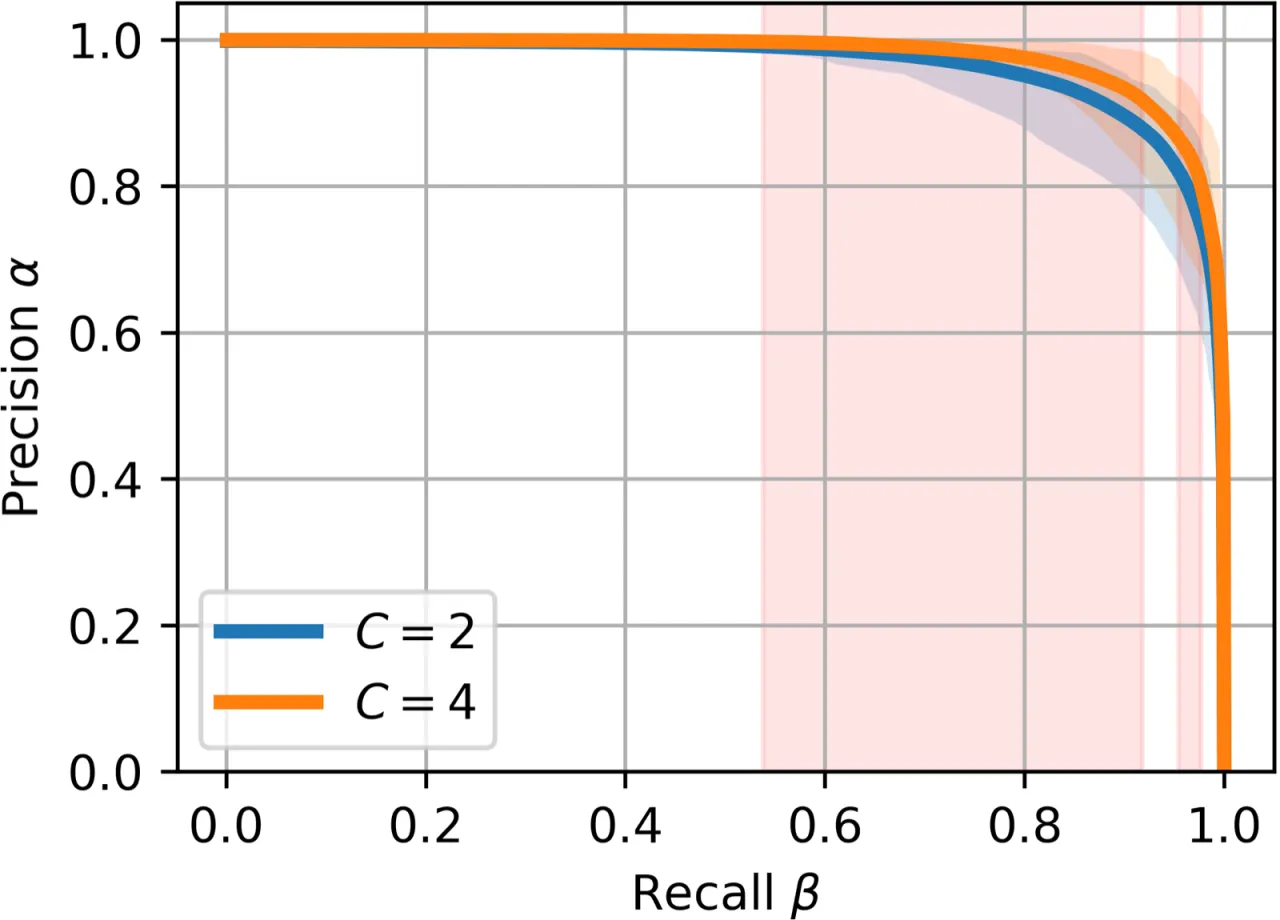
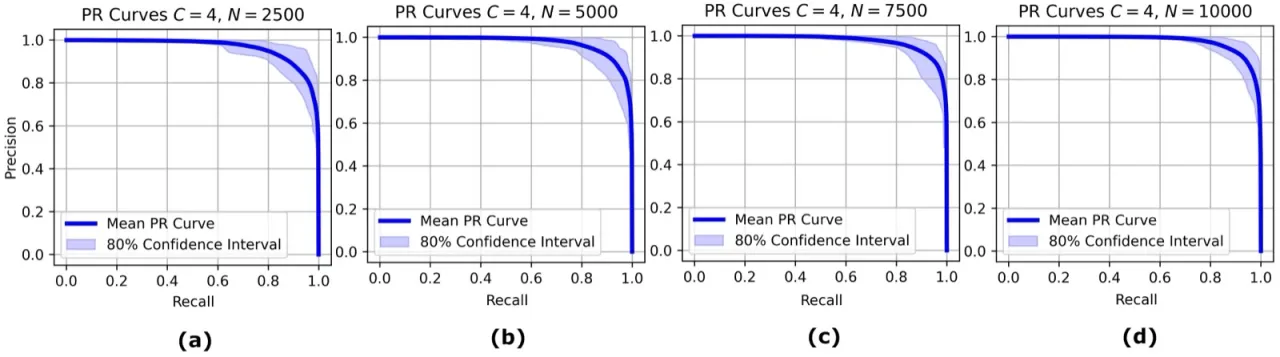
4模型复杂度配置 (C=1,2,4,8)
M=30每组独立训练的模型数量
20k合成训练样本数
44.2%C=4 显著优于 C=2 的 PR 曲线占比