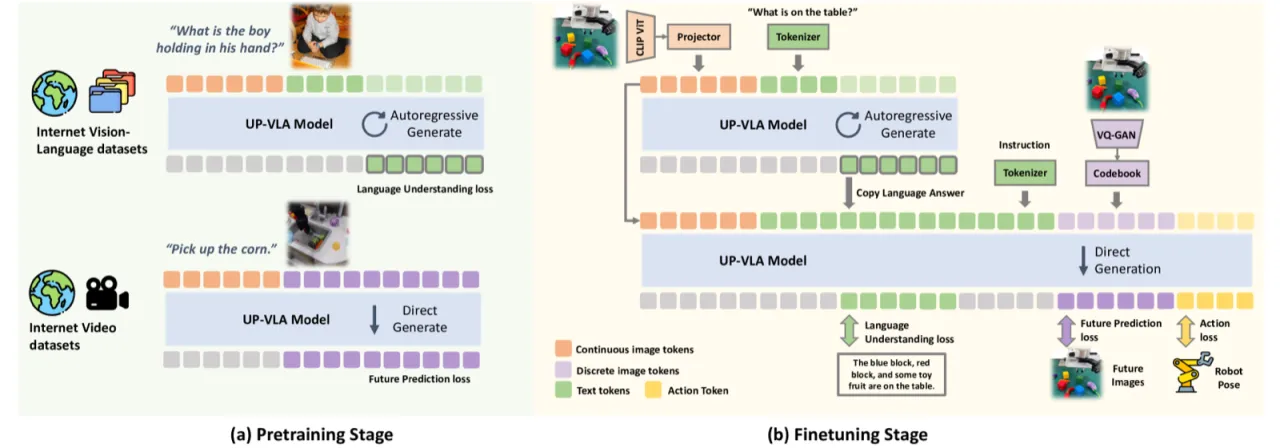
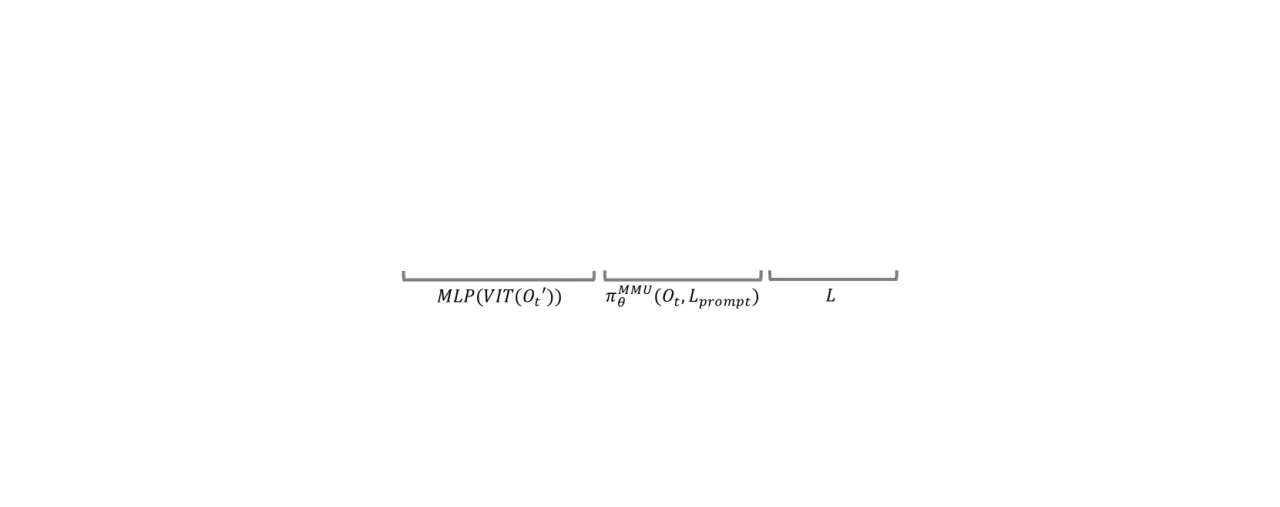
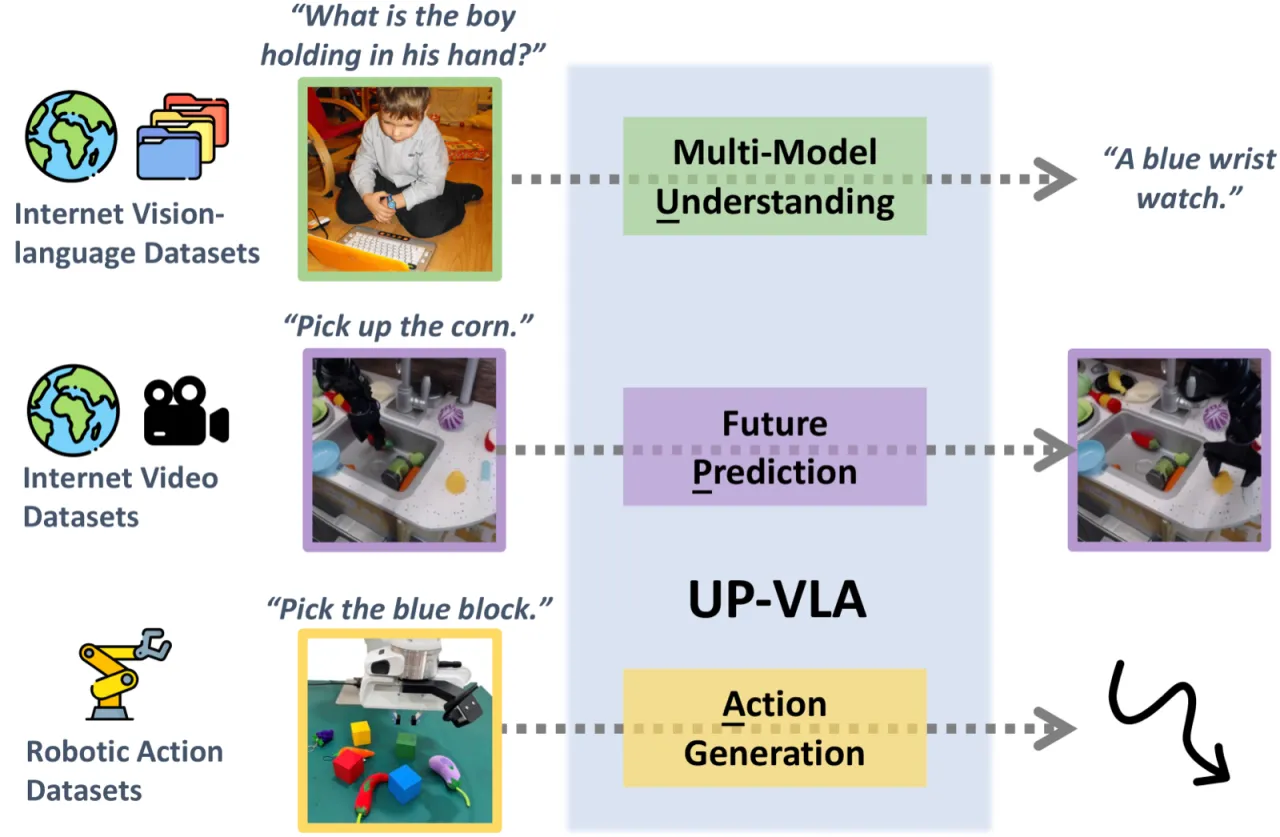
01 动机
Vision-Language-Action (VLA) 模型借助大规模预训练 VLM 的语义知识,大幅提升了机器人策略的泛化能力。然而,现有 VLM 以高层语义理解为主,对低层视觉特征(距离、尺寸、空间关系)理解不足,而这些恰是机器人精细操作任务所必需的。
"VLMs often focus on high-level semantic content and neglect low-level features, limiting their ability to capture detailed visual and spatial information. These aspects, which are crucial for robotic control tasks, remain underexplored in existing pre-training paradigms."
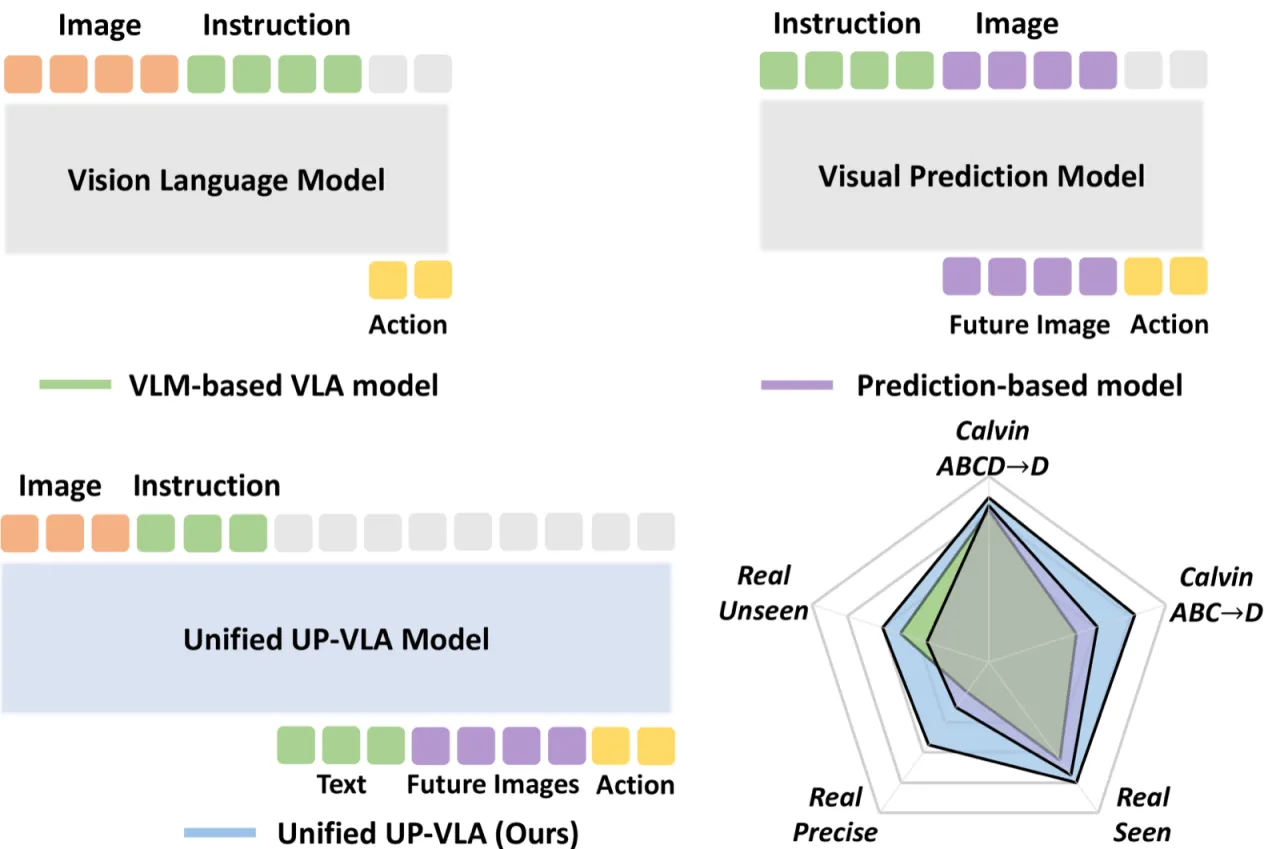
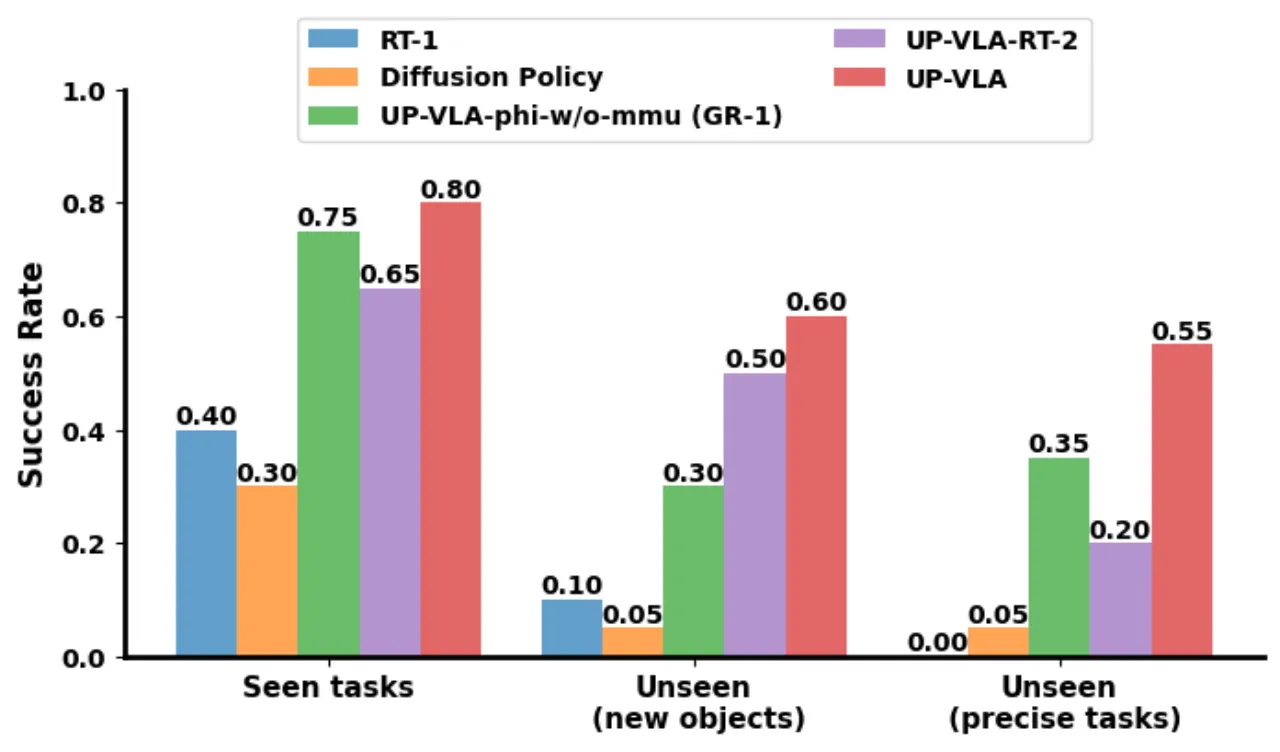
4.08Calvin ABC→D Avg. Length(UP-VLA)
+33%相对 GR-1 (3.06) 的提升幅度
80%真实机械臂已见任务成功率
58%未见物体 / 精细操作泛化成功率