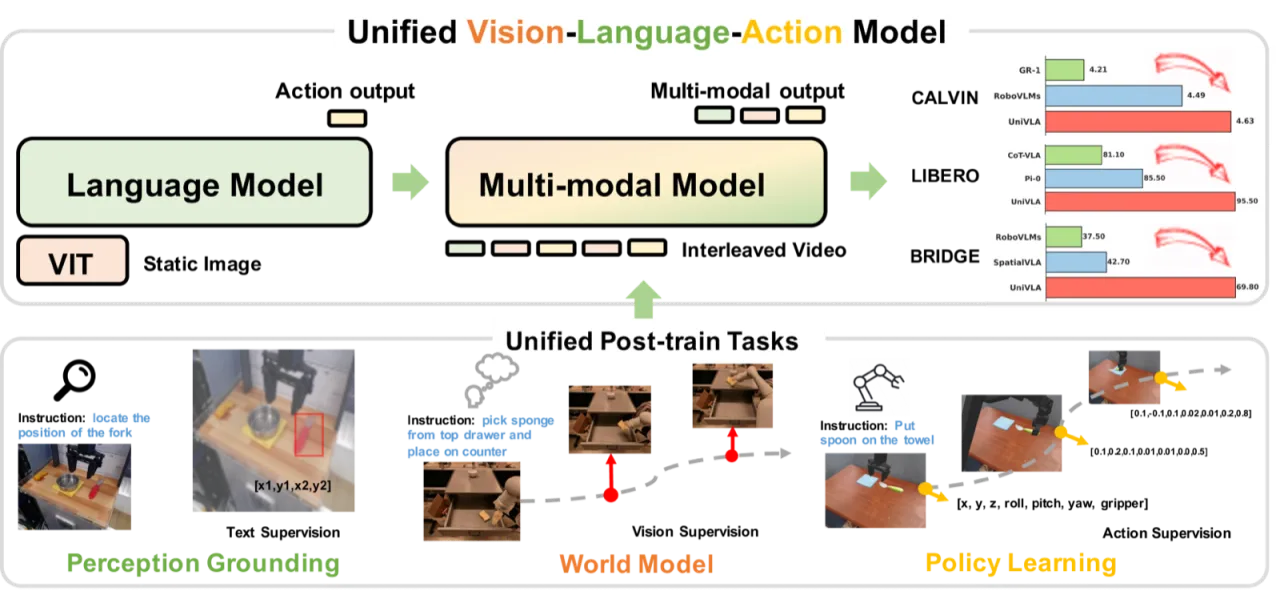
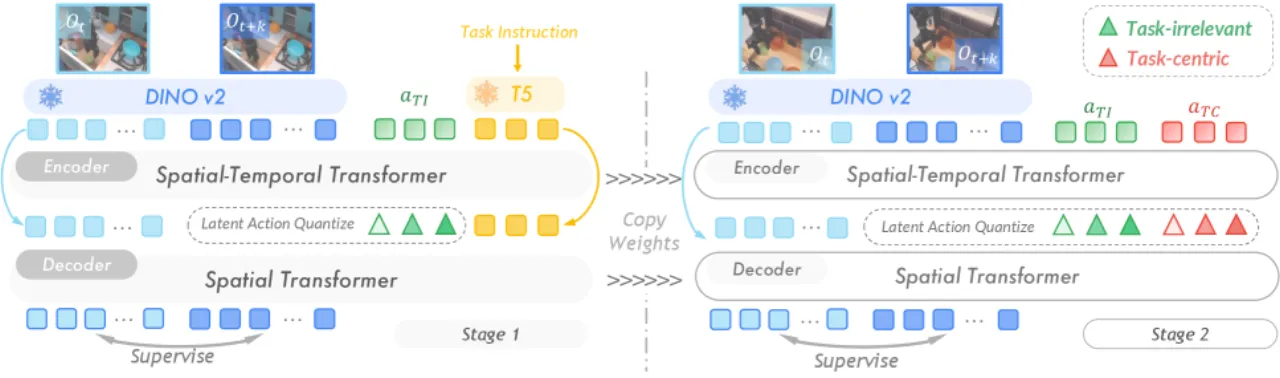
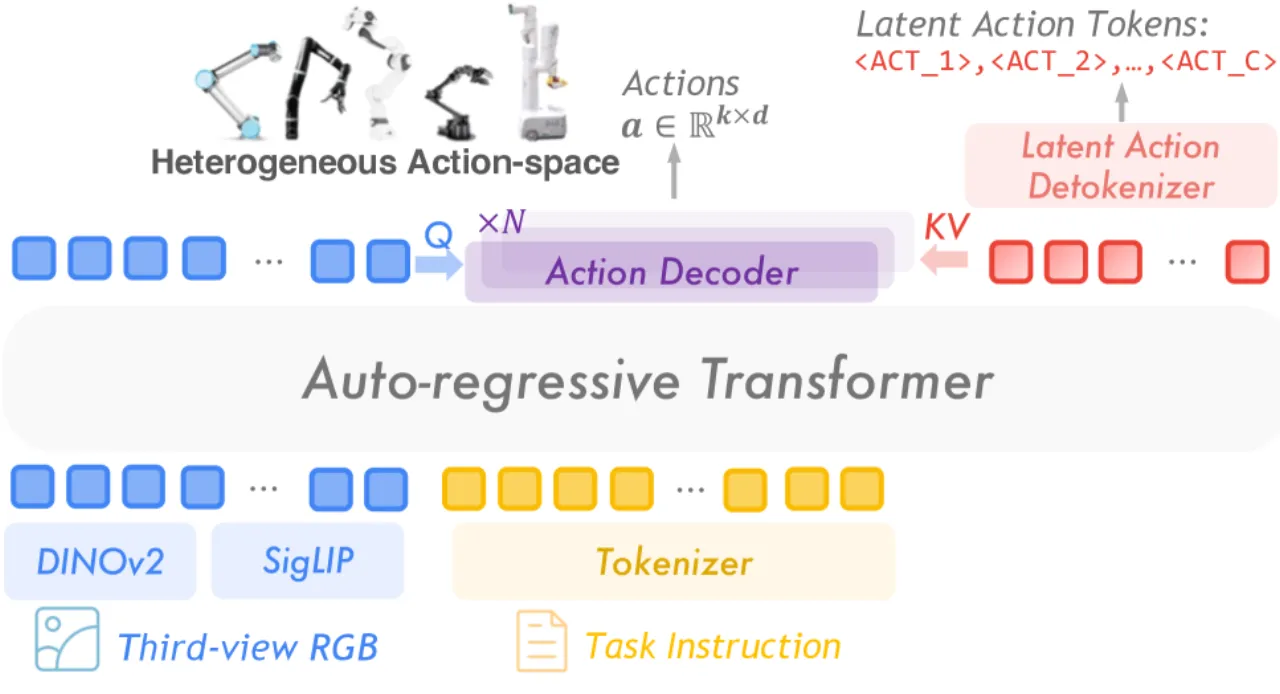
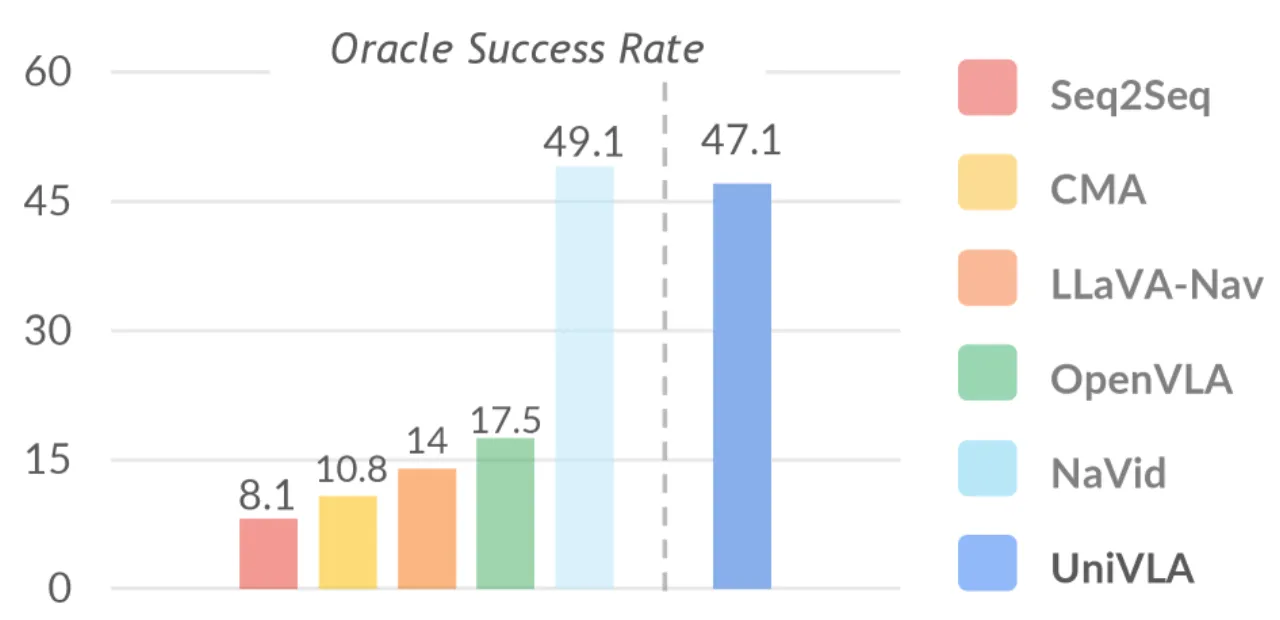
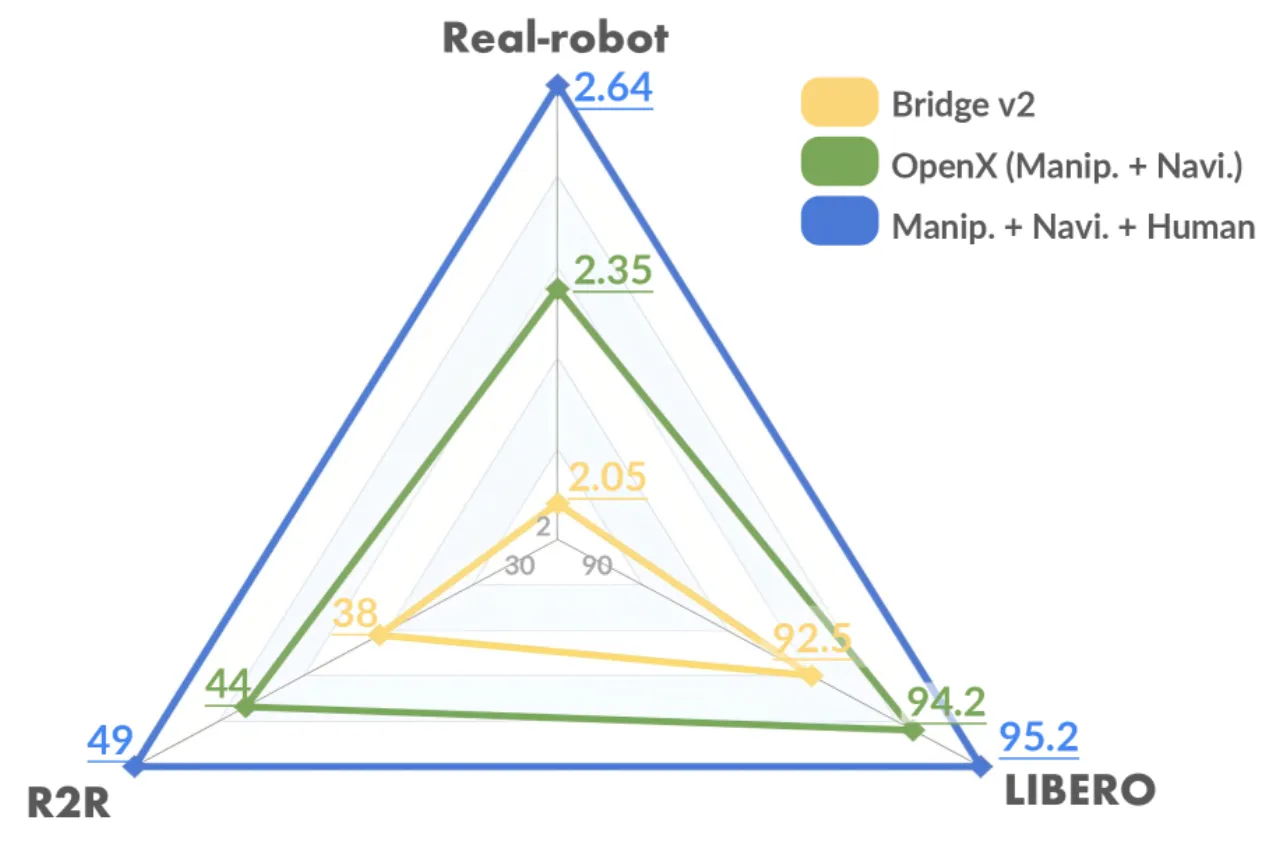
"most existing approaches heavily rely on scaling action-annotated data to enhance their capabilities … We draw inspiration from the fact that large language models learn cross-lingual shared knowledge … and propose UniVLA to derive task-centric action representations from videos."
论文指出:"The fixed granularity of the latent action and the predefined codebook size may not be optimal for all tasks or embodiments."本文主要在单臂操作场景下验证;扩展到双臂或灵巧手系统需要更复杂的动作建模,尚未得到充分探索。