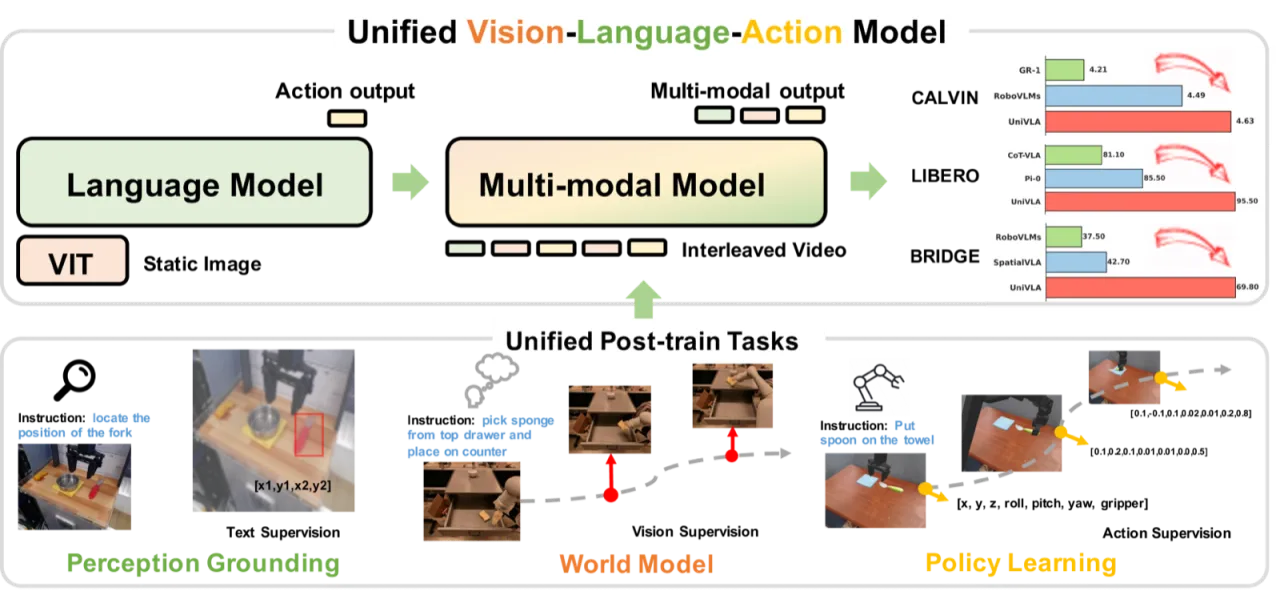
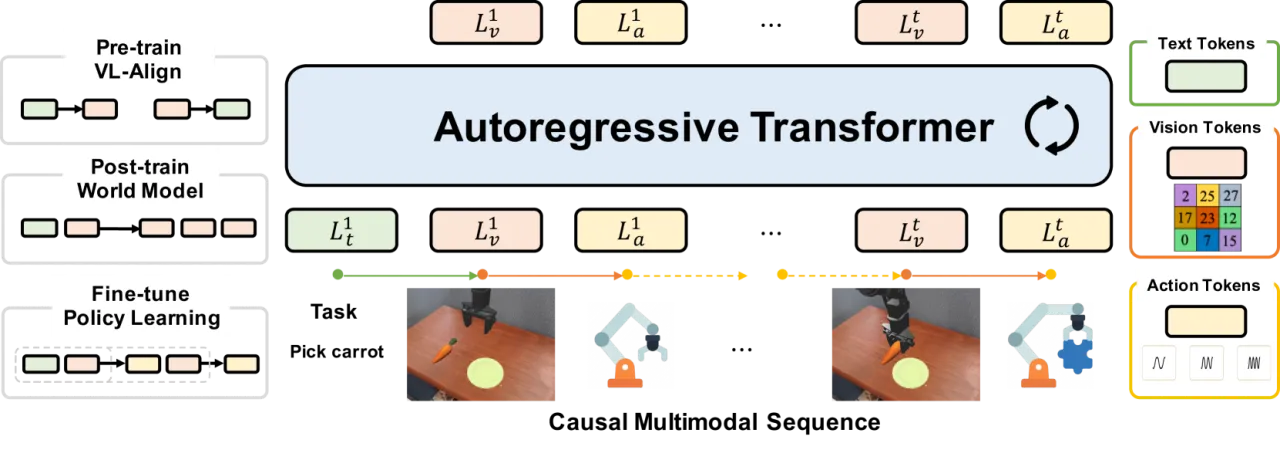
Note: 以下前两条为论文作者明确陈述(stated by the authors);第三条为从设计层面推断(inferred from the design)。
后训练规模化探索受限于算力
作者指出:"Due to limited computational resources, our investigation into post-training scalability is still in its early stages." 现有实验仅在 32 块 A100 上进行,更大规模的后训练数据与参数量对性能的影响尚未充分研究,存在进一步提升空间。
与强化学习的整合有待深入
论文承认当前方法需要 "further research to fully integrate it with reinforcement learning paradigms, enabling more robust and adaptive policy learning"。现阶段仅依赖模仿学习,RL 闭环训练(探索、奖励设计等)尚未实现。