01 动机 Motivation
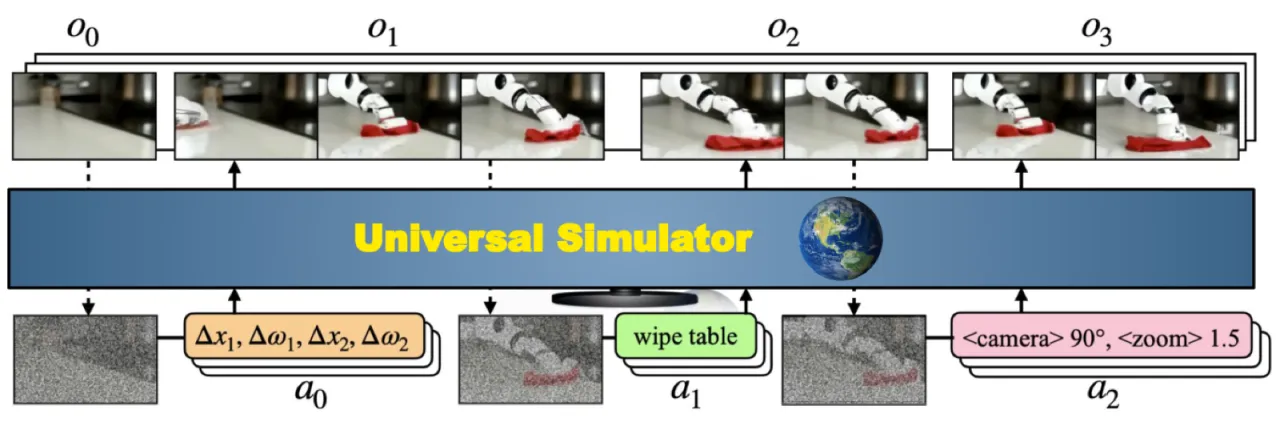
训练现实的交互式仿真器是机器人和智能体研究的核心挑战。 传统仿真器(MuJoCo、Isaac Gym 等)依赖手工设计的物理引擎, 难以捕捉真实世界的视觉多样性与复杂交互; 而已有的视频预测方法通常局限于单一场景或特定动作类型。 能否用互联网规模的多源数据训练出一个通用的、 支持多种动作接口的真实世界仿真器?
"We explore the possibility of learning a universal simulator (UniSim) of real-world interaction through generative modeling."

5.6B模型参数量
0.34RDG(仿真策略,语言桌面任务)
81%RL 训练后成功率(vs BC baseline 58%)
46.23CIDEr(仿真数据微调后,ActivityNet)