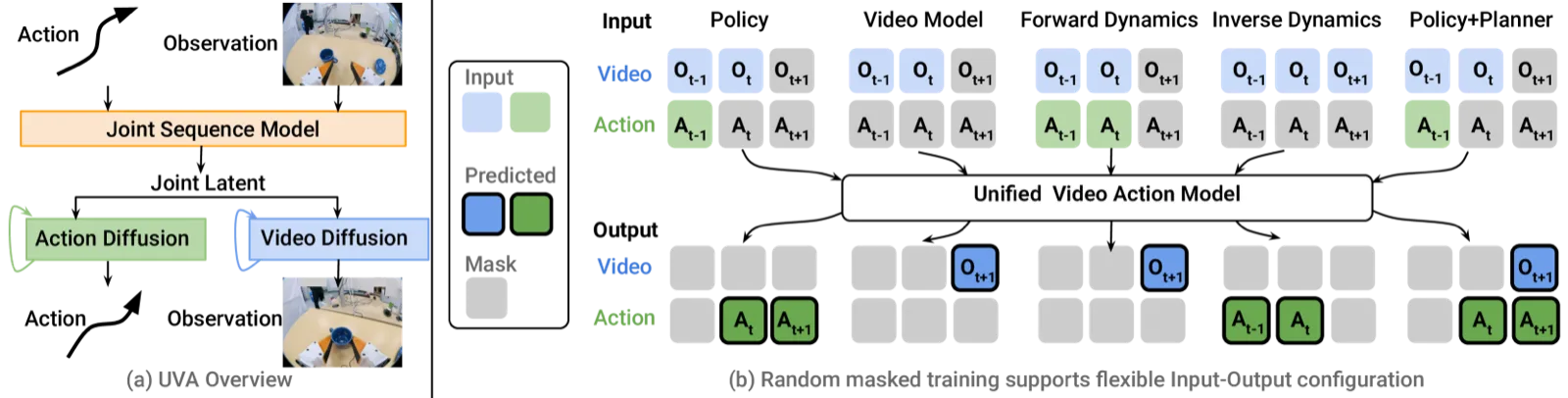
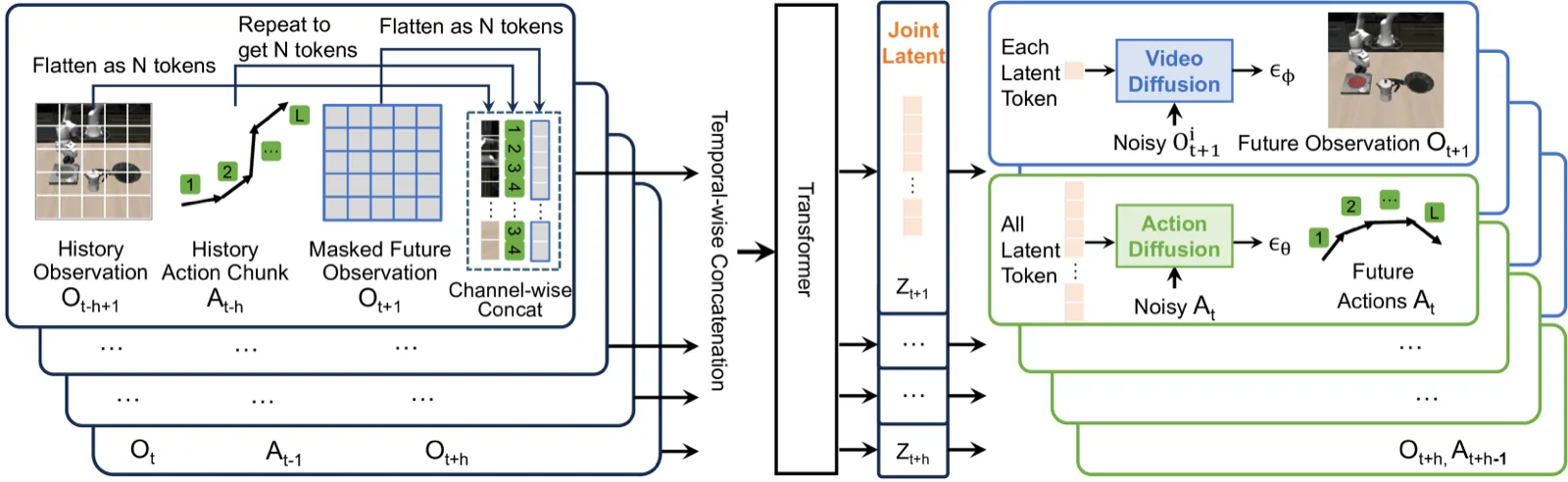
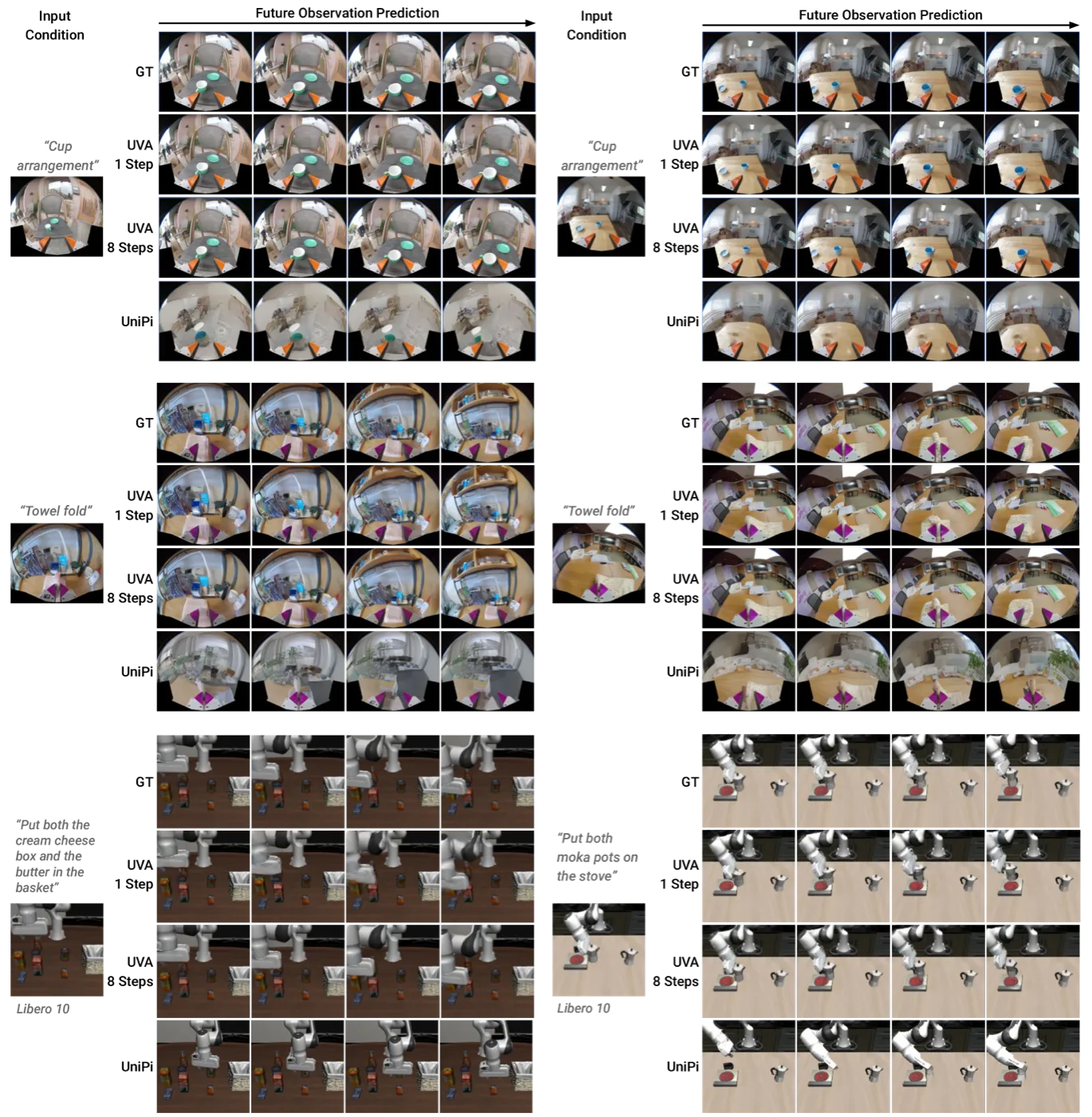
作者认为 UVA 的逆向动力学性能代表了 "a viable alternative to SLAM, which is difficult to calibrate and suffers from a high failure rate."
消融实验
移除视频生成分支(UVA-action only)后,策略成功率在多任务设置下明显下降,验证了联合视频-动作监督对策略鲁棒性的贡献。对 masking 策略的消融(application-dependent vs. application-independent,不同 mask ratio)也在附录 Table VIII 中详细报告。在 Libero10 上加入少量人类示教视频(action-free),成功率从 0.90 进一步提升至 0.91(500-test 设置),证明框架具备利用无动作视频数据的潜力。
推理速度
仿真任务单条轨迹推理耗时 0.23s(对比 DP-C Transformer 变体 0.36s);真实世界实验推理延迟 95ms。"The use of decoupled diffusion heads eliminates the need for video generation during policy inference."
04 局限性
说明: 以下局限性中,第一条为论文 Discussion 章节明确陈述(stated),其余为从方法设计中合理推断(inferred from design)。
无动作视频数据的利用尚不充分(stated)
论文明确指出,当前框架 "does not currently leverage large amounts of actionless video data, which could provide valuable additional supervision." 作者建议通过在大规模网络视频数据集上进行预训练,可以显著增强模型的泛化能力。附录实验表明加入少量人类视频数据可小幅提升性能,但系统性探索留待未来工作。