01 动机
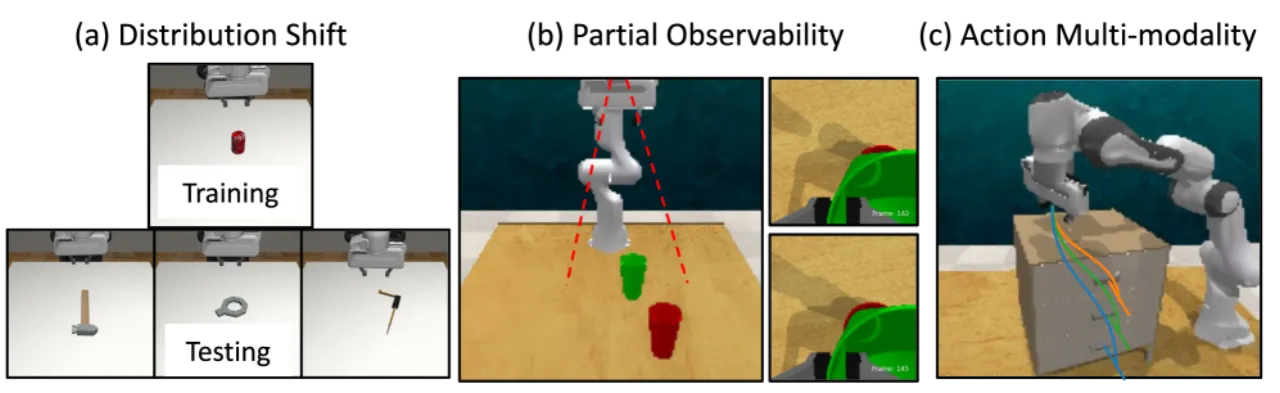
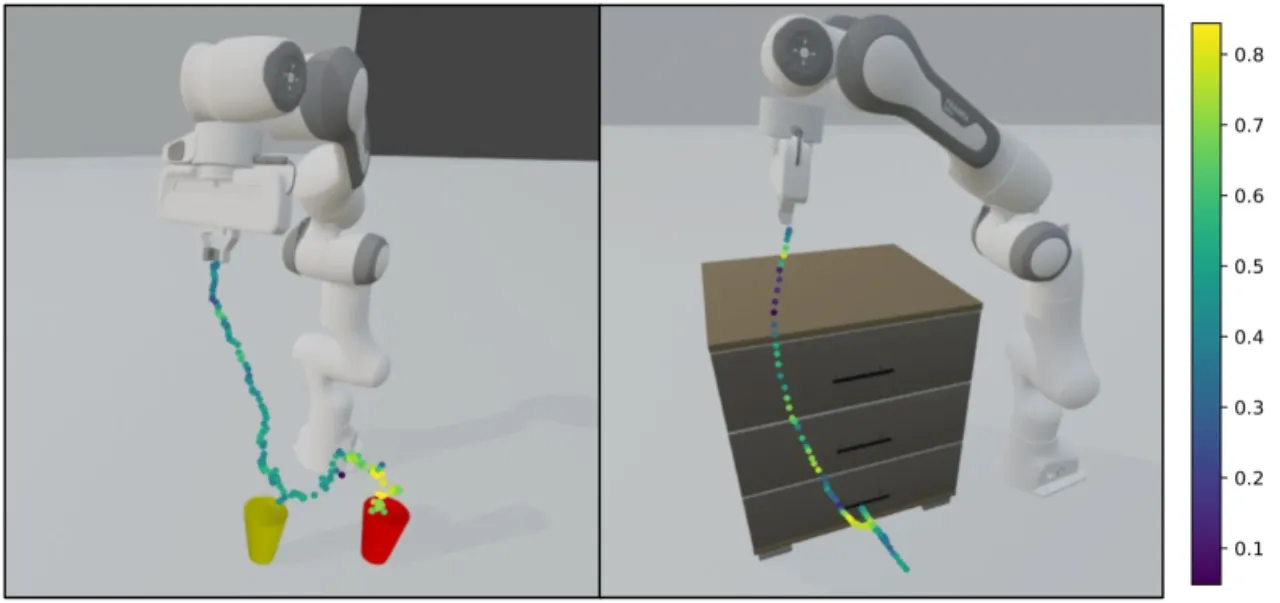
在实际机器人部署中,人工持续监控代价高昂、难以规模化。现有 HitL 方法要求人工标注干预时机,或训练额外分类器, 成本高且泛化性差。本文发现:扩散模型的去噪过程本身就隐含了丰富的不确定性信号,无需任何额外监督即可驱动智能干预请求。
"We propose using denoising uncertainty as a metric for deciding when to request (human) expert assistance." ——无需在训练时引入人工标注,不确定性信号从扩散策略的生成过程中免费获得。
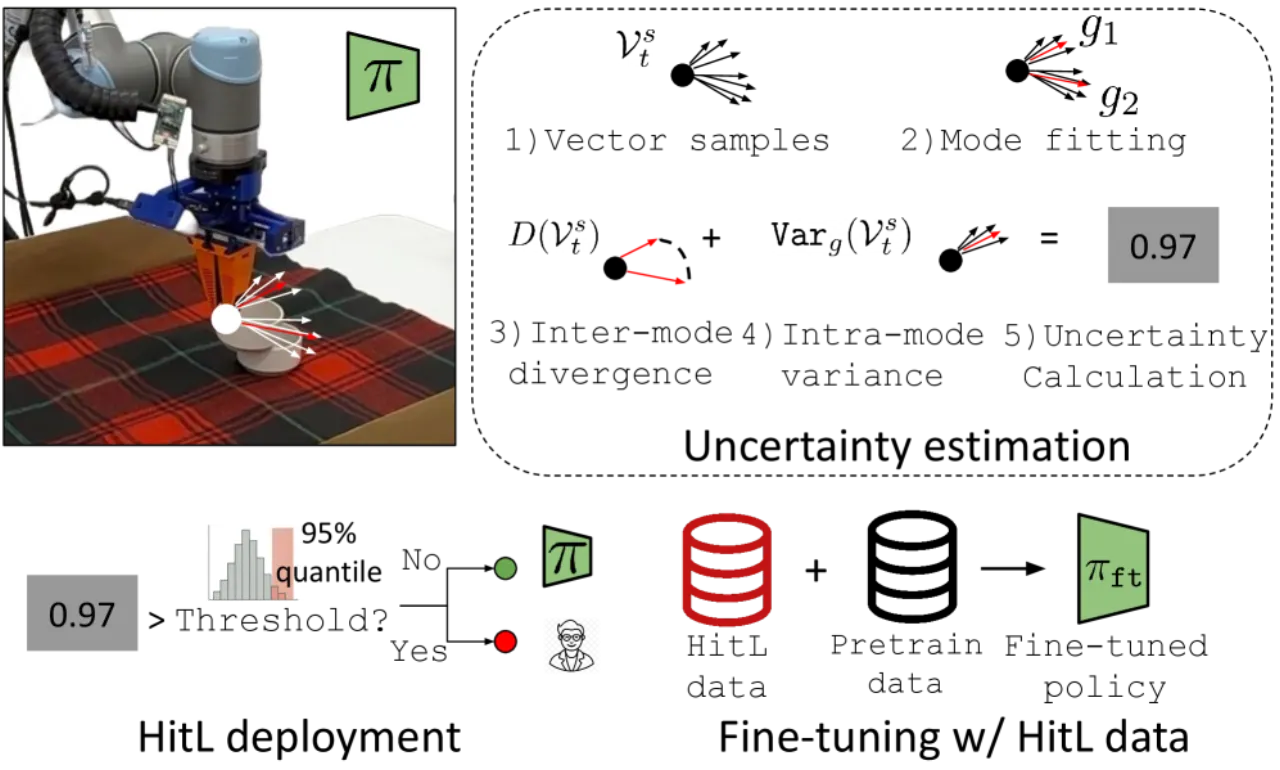
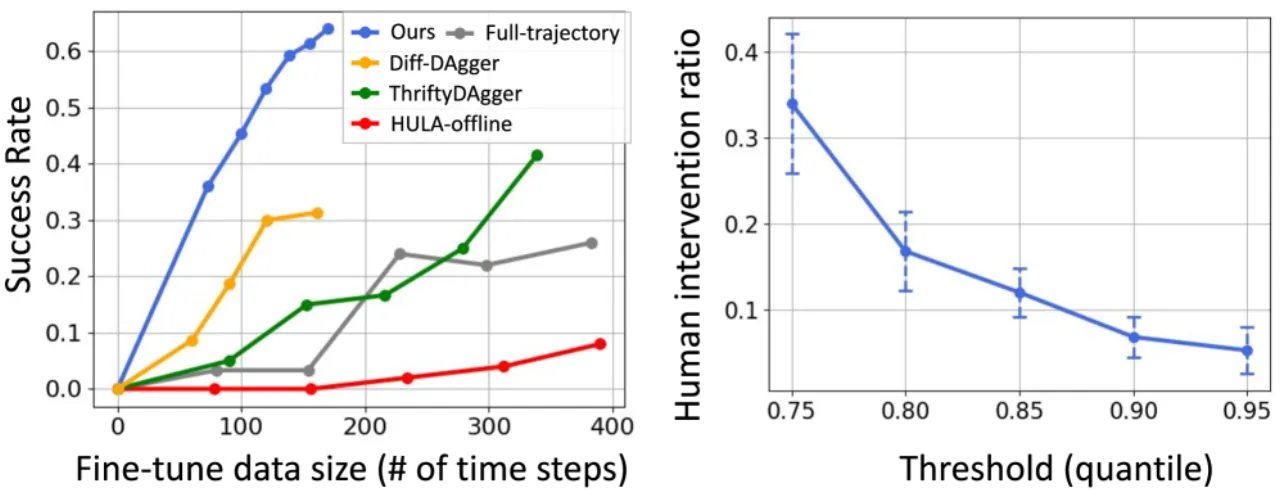
≈8.3%真实机器人实验中需人工干预的时间步比例,即可达到 100% 成功率
47%HitL 微调后平均成功率提升幅度(相比基线)
8.0开抽屉任务所需最少干预步数(vs. ThriftyDAgger 的 17.2 步)
0 额外标注训练期间无需任何人工干预标注,不确定性"免费"获得
现有方法的不足
现有 HitL 机器人策略方法可分为两类:
- 基于人工标注的方法(如 DAgger、ThriftyDAgger):需要在训练时人工标记"何时应干预",成本高、难扩展。
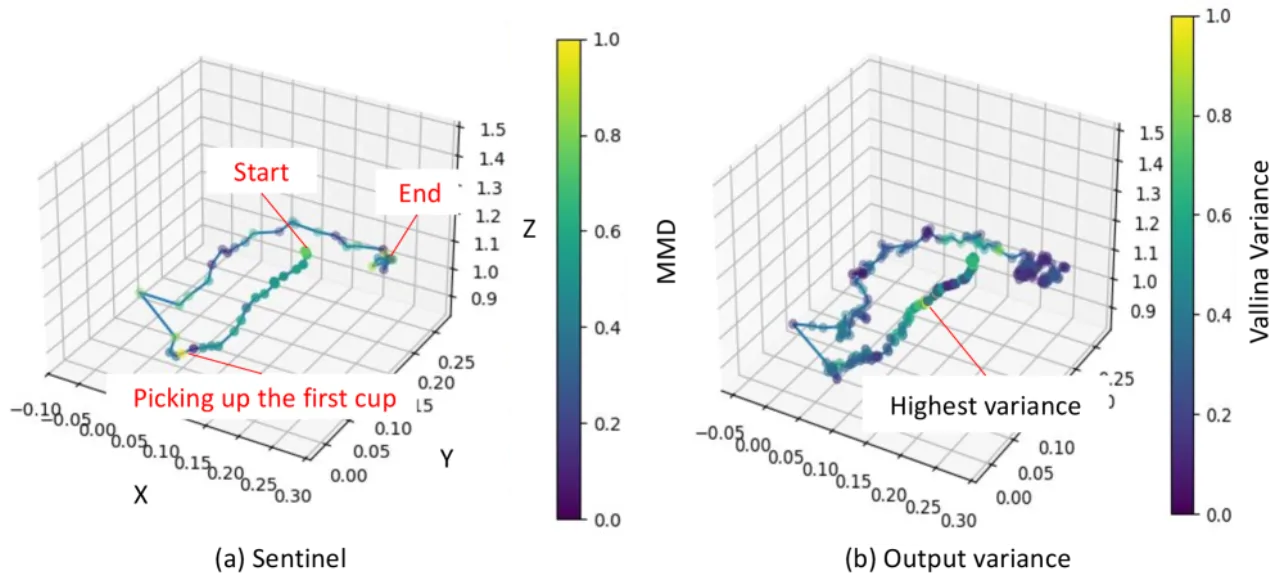
- 基于额外模型的方法(如 HULA、Sentinel):需要训练独立的风险预测模型,引入额外的数据和计算开销。
- 本文:直接复用扩散策略已学到的噪声预测机制,零成本获取不确定性,无需改变训练流程。