01 动机
机器人操作策略的训练数据严重不足:远程操控需要昂贵硬件和专家操作员,而直接利用人类在野外的视频又存在巨大的动作域差(embodiment gap)。现有手持夹爪方案往往只能处理简单的拾取任务,无法支持动态投掷、双臂折叠或长时序洗碗等复杂操作。
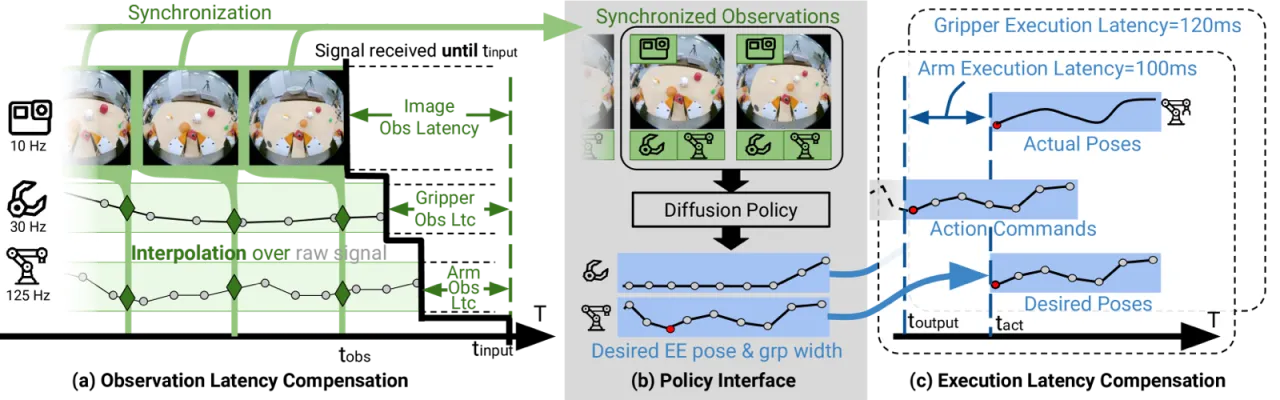
"We identify four core issues that prevent direct action transfer from human demonstration to robot execution: insufficient visual context, action imprecision, latency discrepancies, and insufficient policy representations for multimodal action distributions."

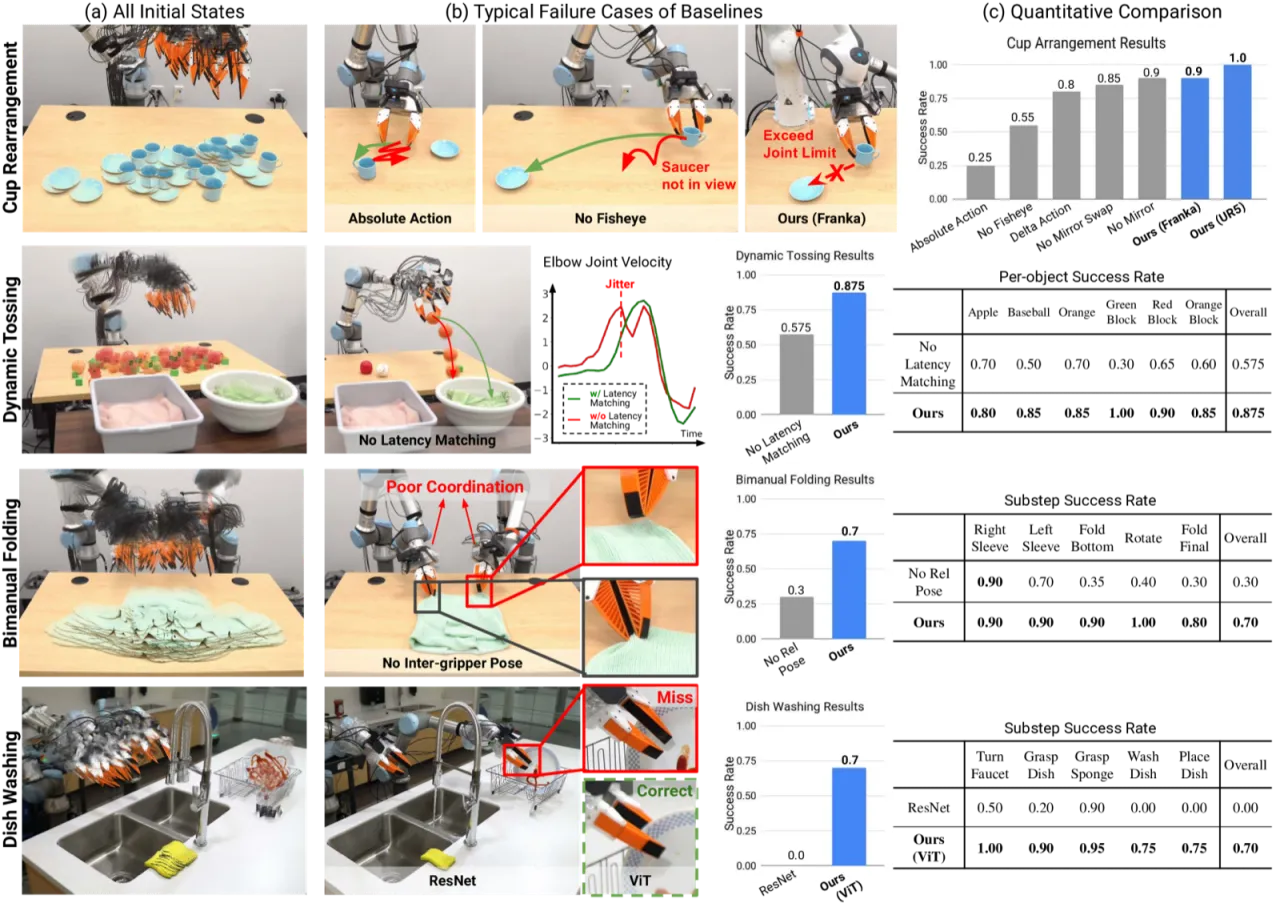
20/20杯子摆放满分成功率(Full UMI)
87.5%动态投掷成功率(105/120)
70%7步洗碗任务成功率(14/20)
$371单套夹爪总硬件成本