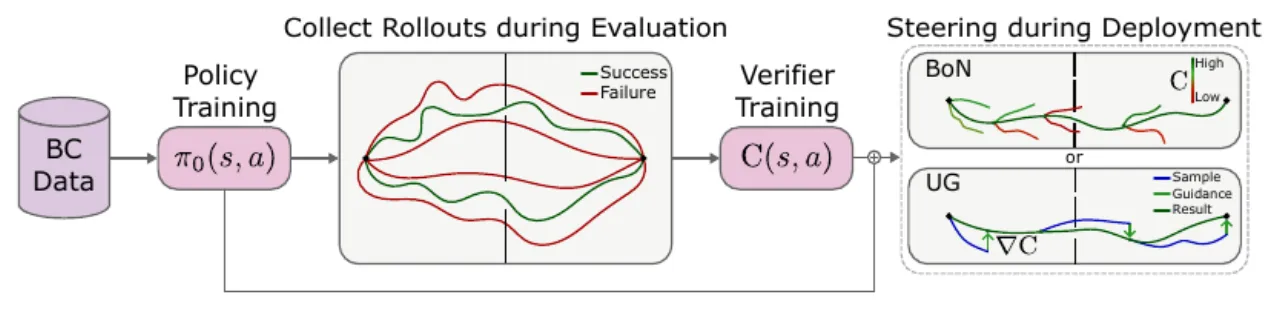
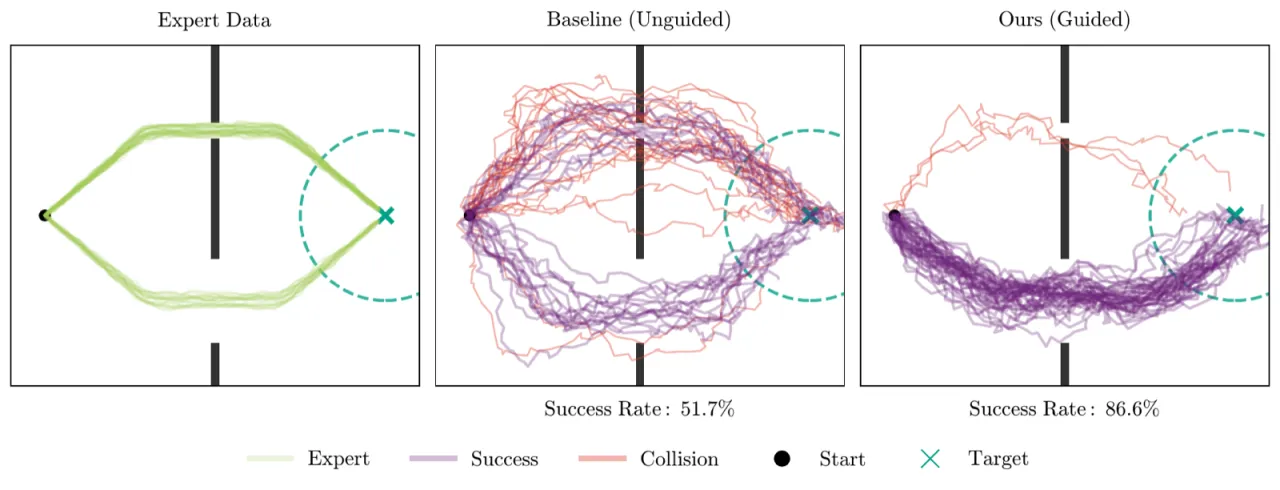
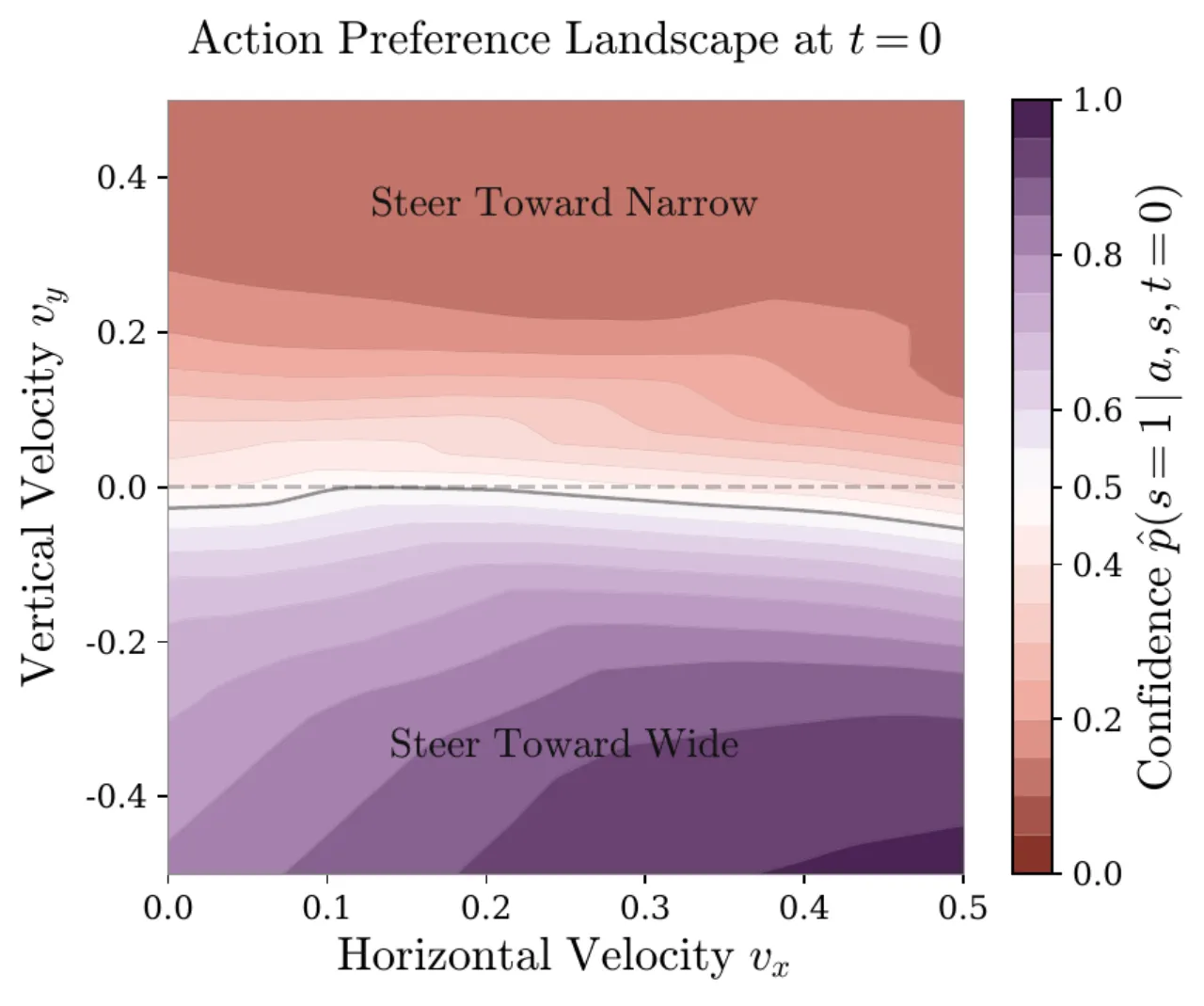
01 动机 Motivation
BC 策略在真实操作中表现出明显的脆弱性(brittleness),失败往往集中在需要精准动作的 fine-grained 交互点上。现有改进方案——如 fine-tuning、额外数据采集——代价高昂, 且可能导致灾难性遗忘(catastrophic forgetting),对 black-box 扩散策略更是难以直接适用。
"failures contain crucial information about bottleneck states that require precise manipulation… [we] leverage the policy's own evaluation data to improve its performance."
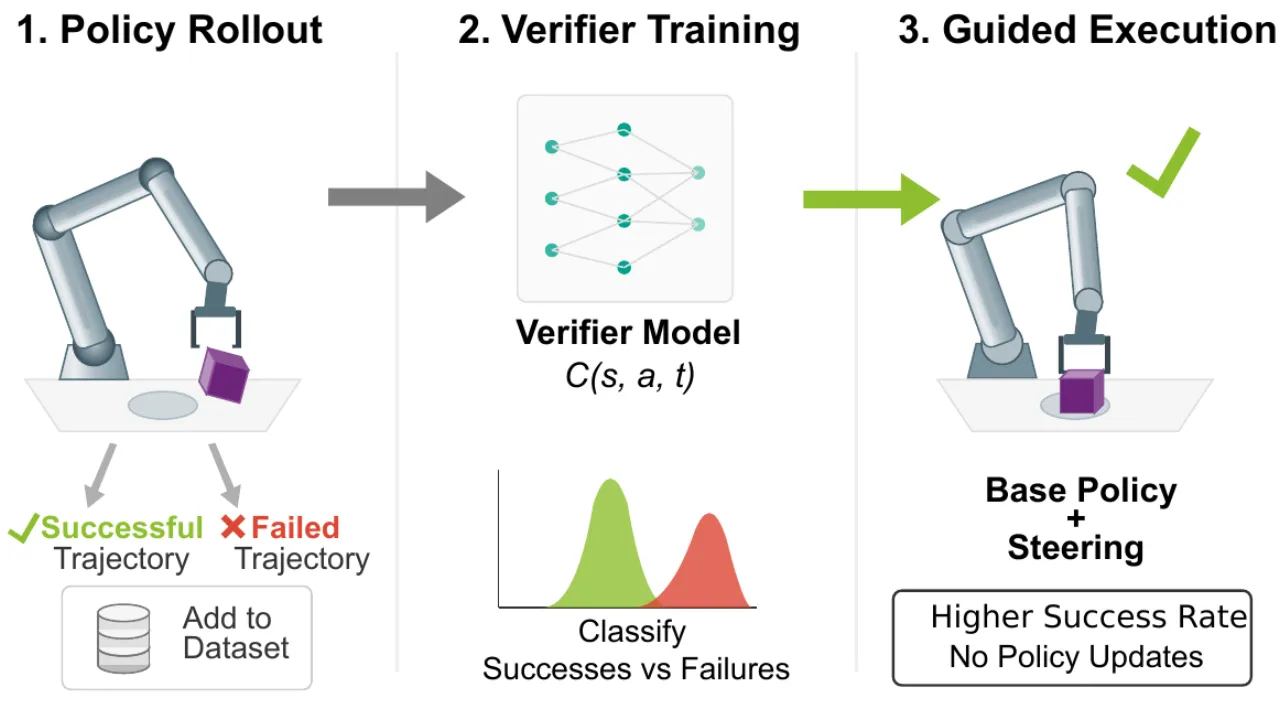
49%真实任务平均成功率提升(vs. base policy)
5真实双臂操作任务(Aloha 系统)
60verifier 训练仅需约 60 条评估轨迹/任务
0base policy 参数改动(完全 update-free)