01 动机
强化学习(RL)与监督学习(SL)之间有一道根本鸿沟:SL 提供误差信号(error signal), 而 RL 提供评估信号(evaluation signal)——智能体只知道动作好不好,却不知道最优动作是什么。 能否完全用 SL 来解决 RL 问题?Barto(2004)曾断言「一般情况下这是不可能的」。 UDRL 正面回应了这一挑战。
"Is it possible to learn to act in high-dimensional environments efficiently using only SL, avoiding the issues arising from non-stationary learning objectives common in traditional RL algorithms?" — Srivastava et al., 1912.02877
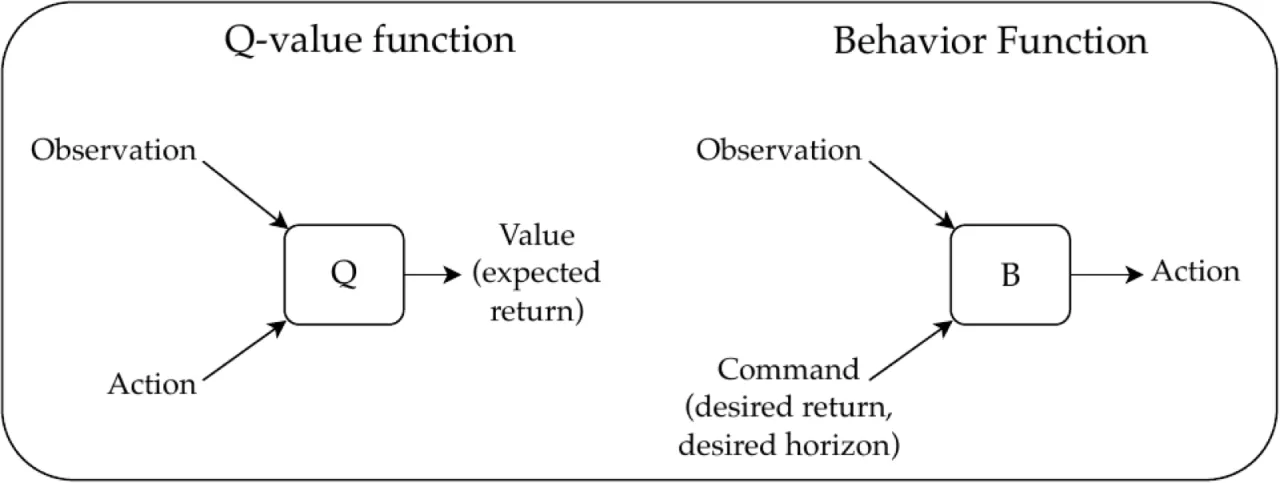
纯 SL无 TD 学习,无策略梯度,不使用 bootstrapping
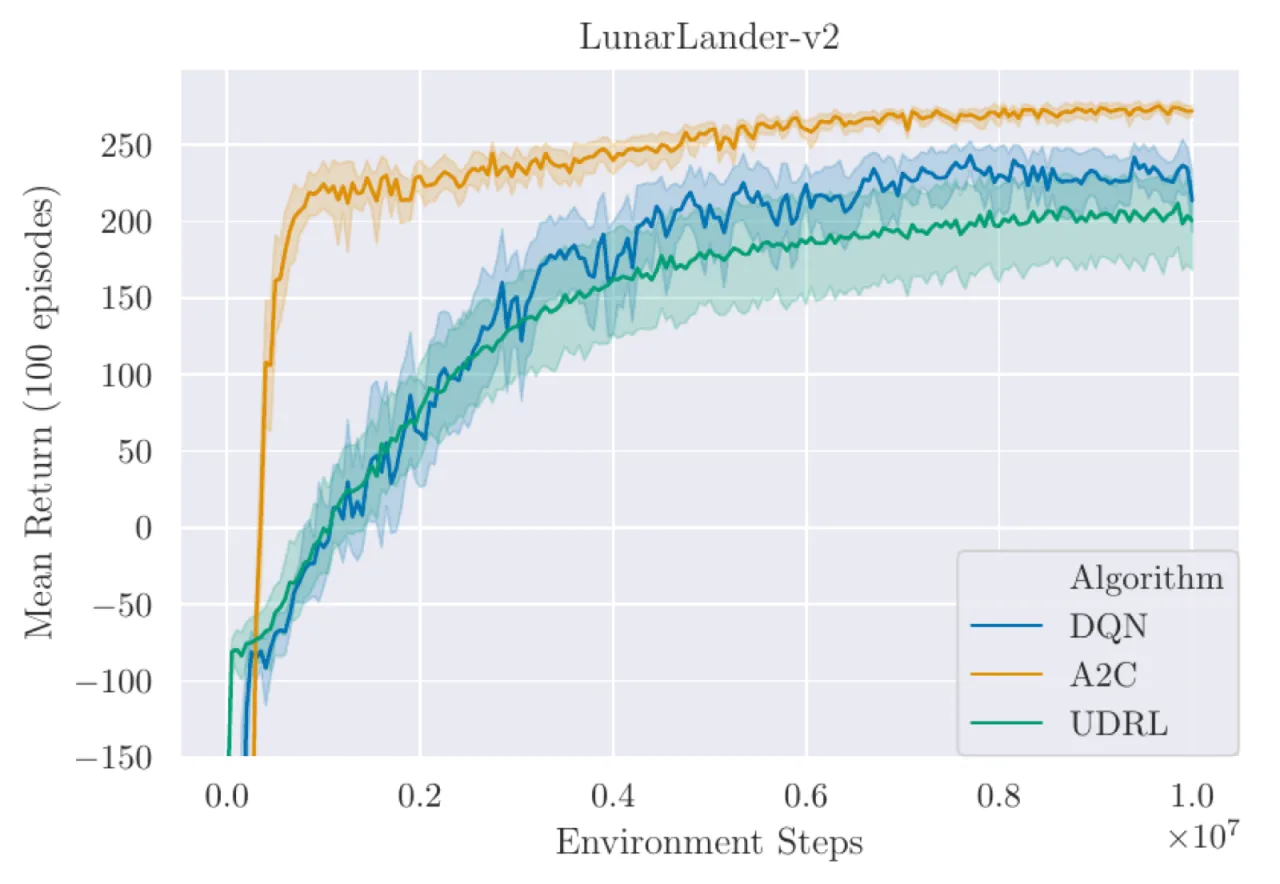
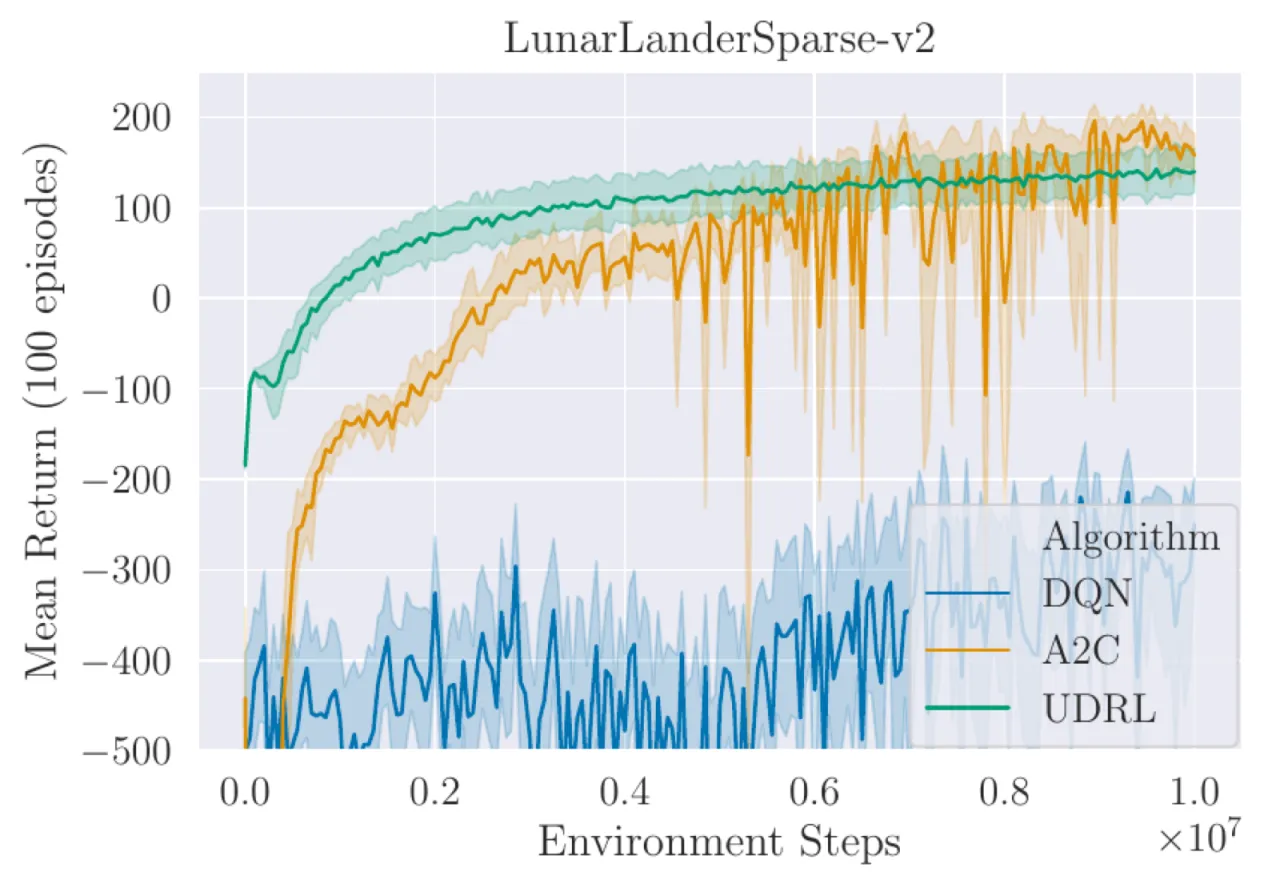
20 runs所有最终对比均使用 20 次独立实验,95% 置信区间
4 环境LunarLander-v2、TakeCover-v0、Swimmer-v2、InvertedDoublePendulum-v2
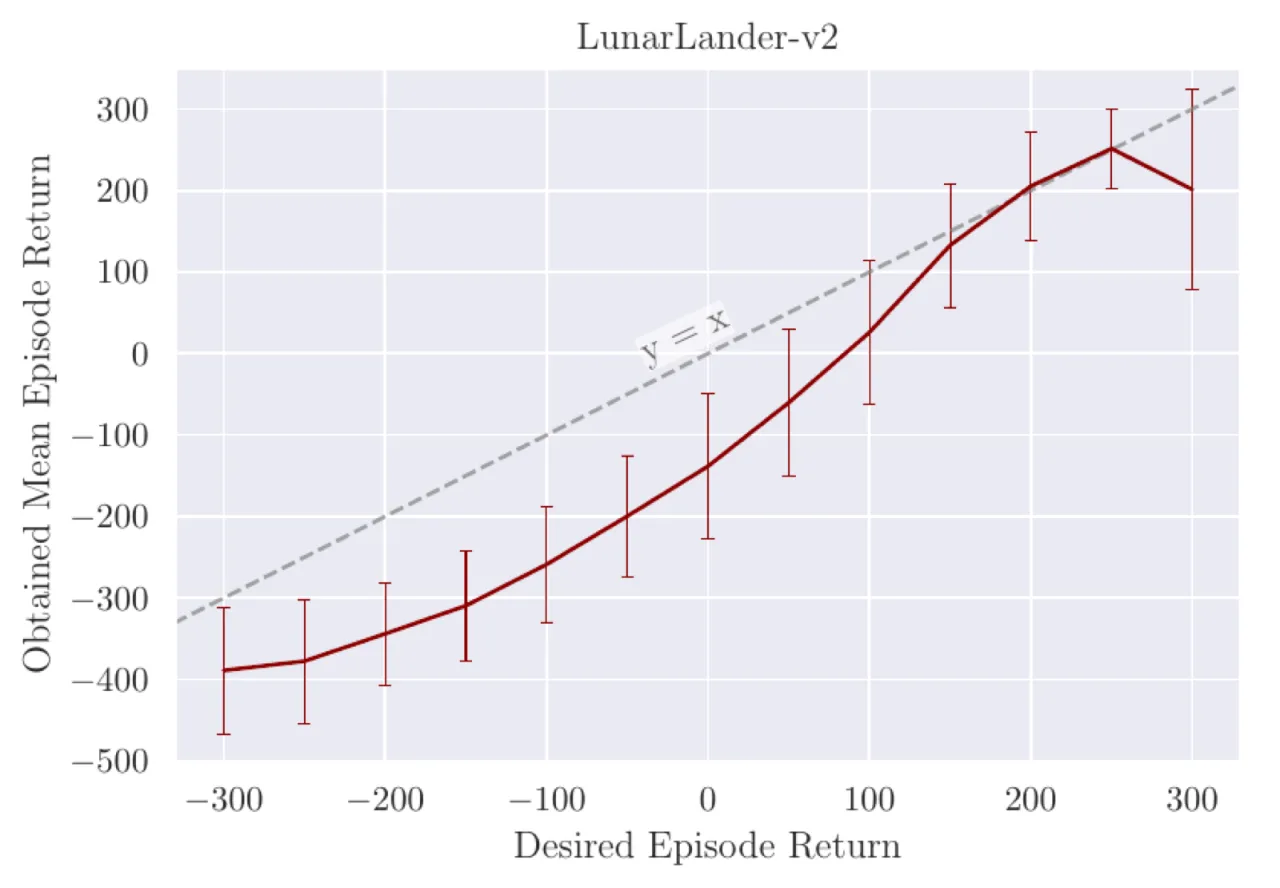
R≈0.98LunarLander-v2 上 desired vs. obtained return 的相关系数
现有大多数将 SL 引入 RL 的工作(如 target network、RUDDER)只是用 SL 来辅助 RL, 而非替代它。UDRL 则更进一步:将过去的轨迹以「事后解释」(hindsight)的方式标注, 视之为智能体成功跟随命令的示范样本,从而完全在 SL 框架内学习。 Schmidhuber(arXiv:1912.02875)给出了理论框架,Srivastava et al.(arXiv:1912.02877) 则提供了可落地的算法与实验验证。