01 动机
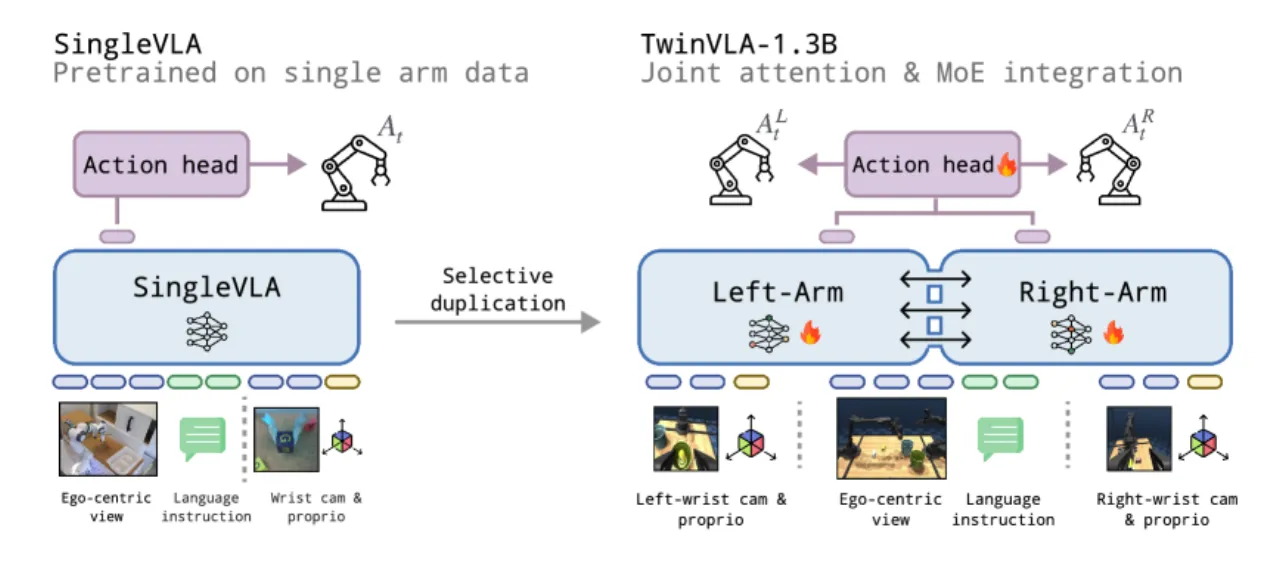
双臂操作是机器人研究的重要挑战,但大规模双臂数据集极为稀缺。现有的整体式(monolithic)双臂 VLA 模型需要海量数据与算力预训练,制约了实际应用。
"RDT-1B required massive pretraining and fine-tuning (reportedly a month on 48 H100 GPUs)... π₀ relies on a 10,000-hour proprietary dataset."
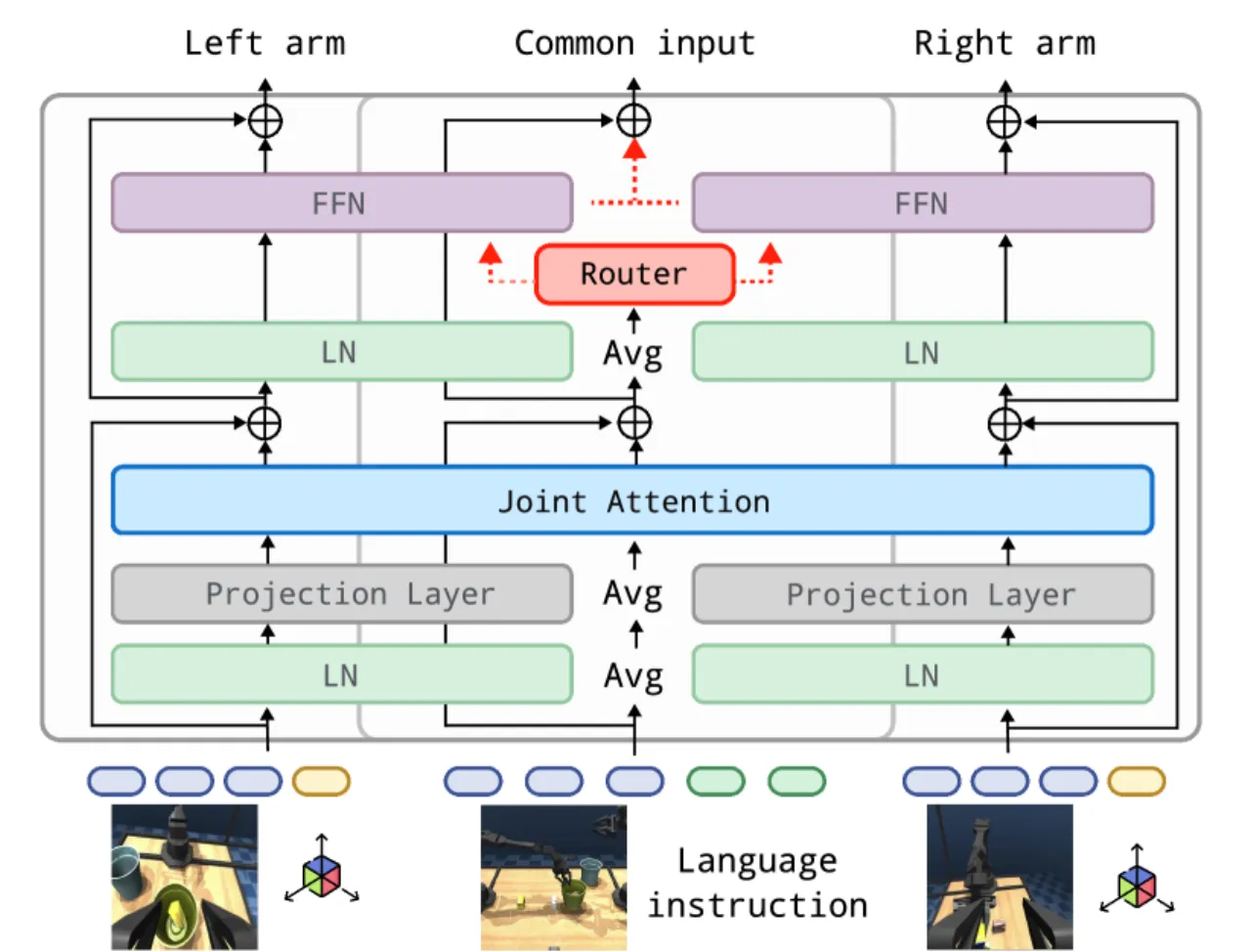
论文的核心洞察来自神经科学:"human bimanual manipulation is the coordination of arm-specific motor primitives rather than a single monolithic controller",人类双臂由专用神经回路协调同步。TwinVLA 基于此,将两个独立的单臂 VLA 模型通过轻量 Joint Attention 连接,利用公开丰富的单臂数据完成迁移,"eliminating the need for large-scale bimanual pretraining"。
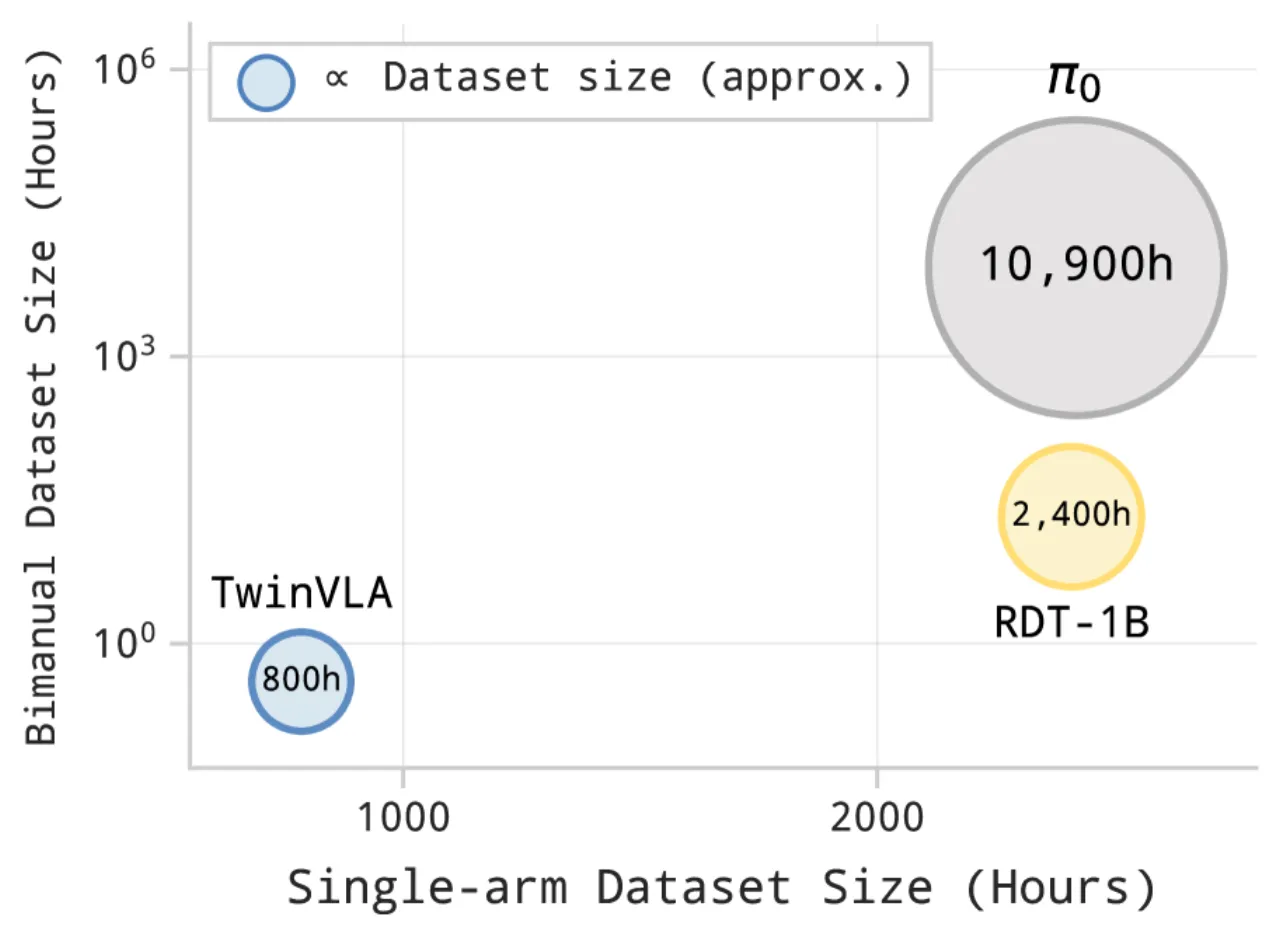
25H100 GPU-days(TwinVLA 训练)
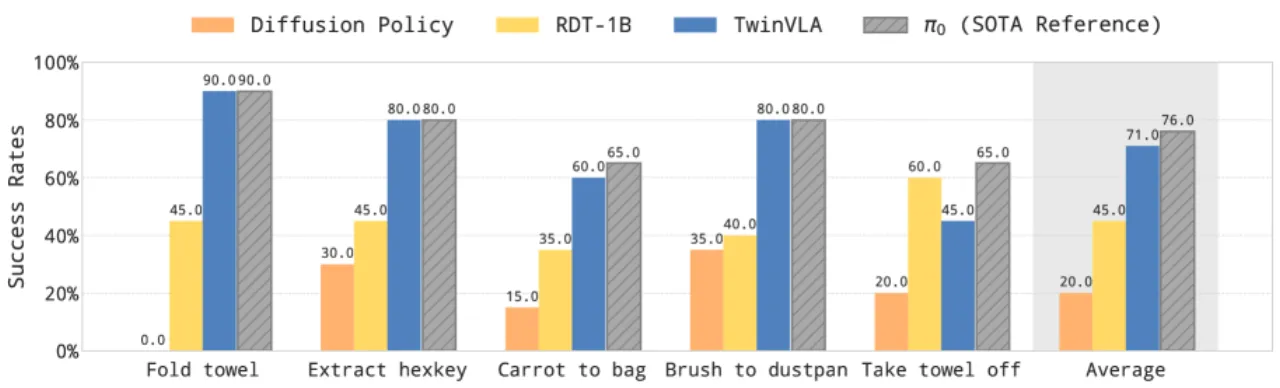
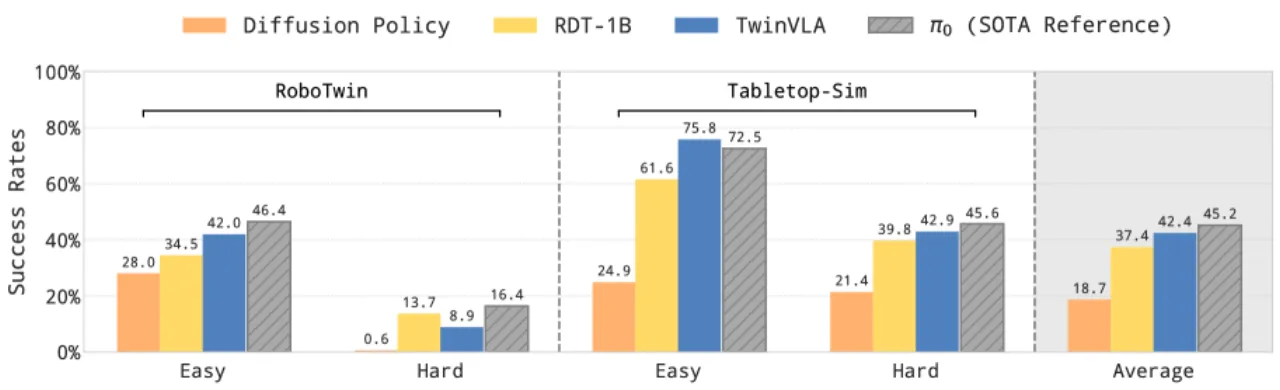
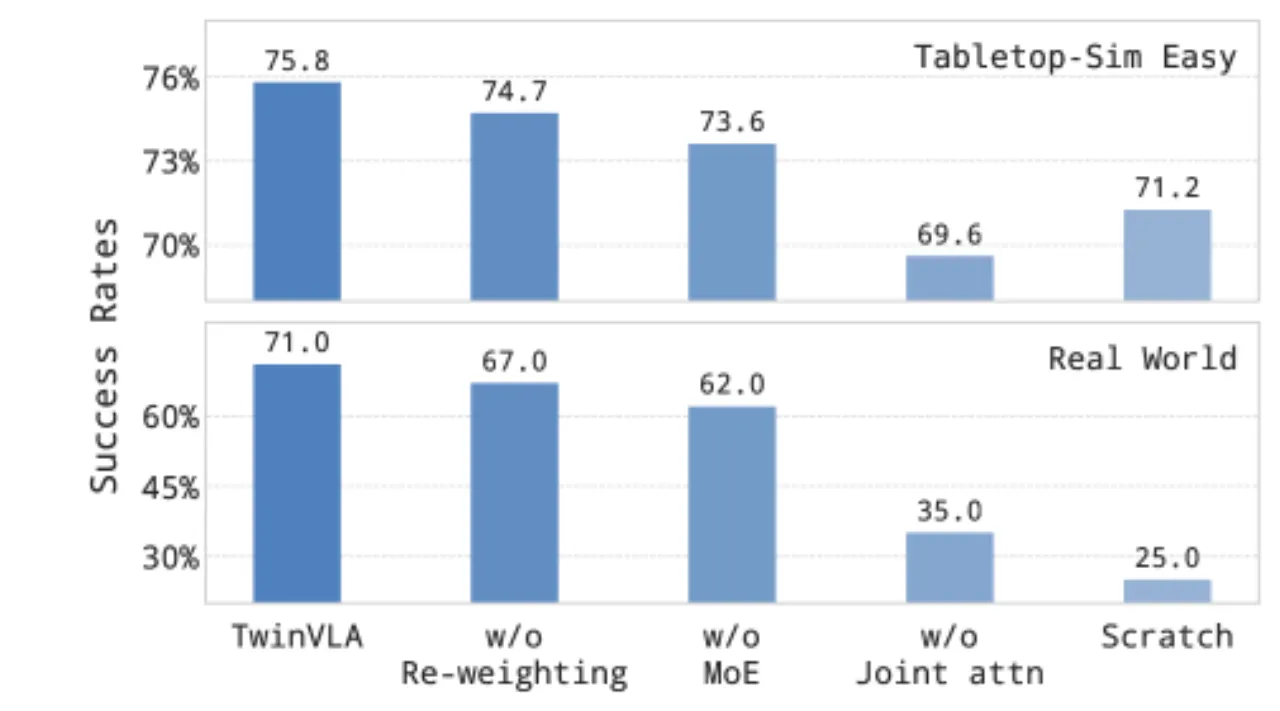
50条双臂演示即可超越 RDT-1B
1.3B参数(与 RDT-1B 1.2B 相当)
+26%真实世界相对 RDT-1B 成功率提升