"Unlike chatbots or search engines, embodied agents must operate in real time. The feedback loop between an agent's actions and its environment necessitates reactivity — like a human athlete, an agent cannot simply 'stop and think' while the outside world changes."
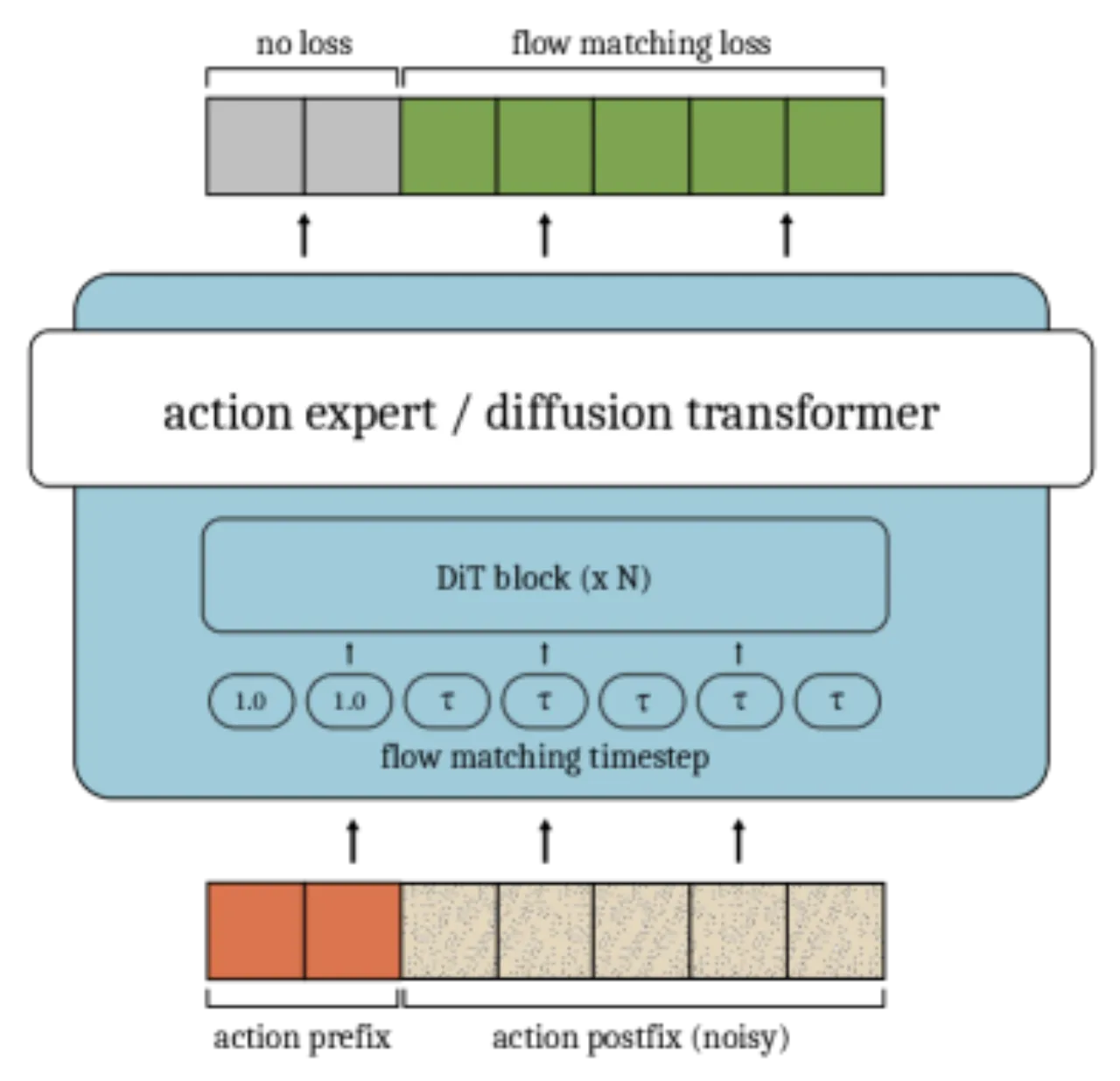
Figure 1:两个重叠 action chunk 的示意图。时刻 t 到 t+d 之间的 d 个动作来自上一个 chunk,称为 action prefix(红色);从 t+d 开始到 chunk 末尾的动作为 action postfix(需要新生成)。Inference-time RTC 利用所有 H−s 个重叠动作(红+黄)做 guidance;training-time RTC 只使用前 d 个动作(红色)作为条件。
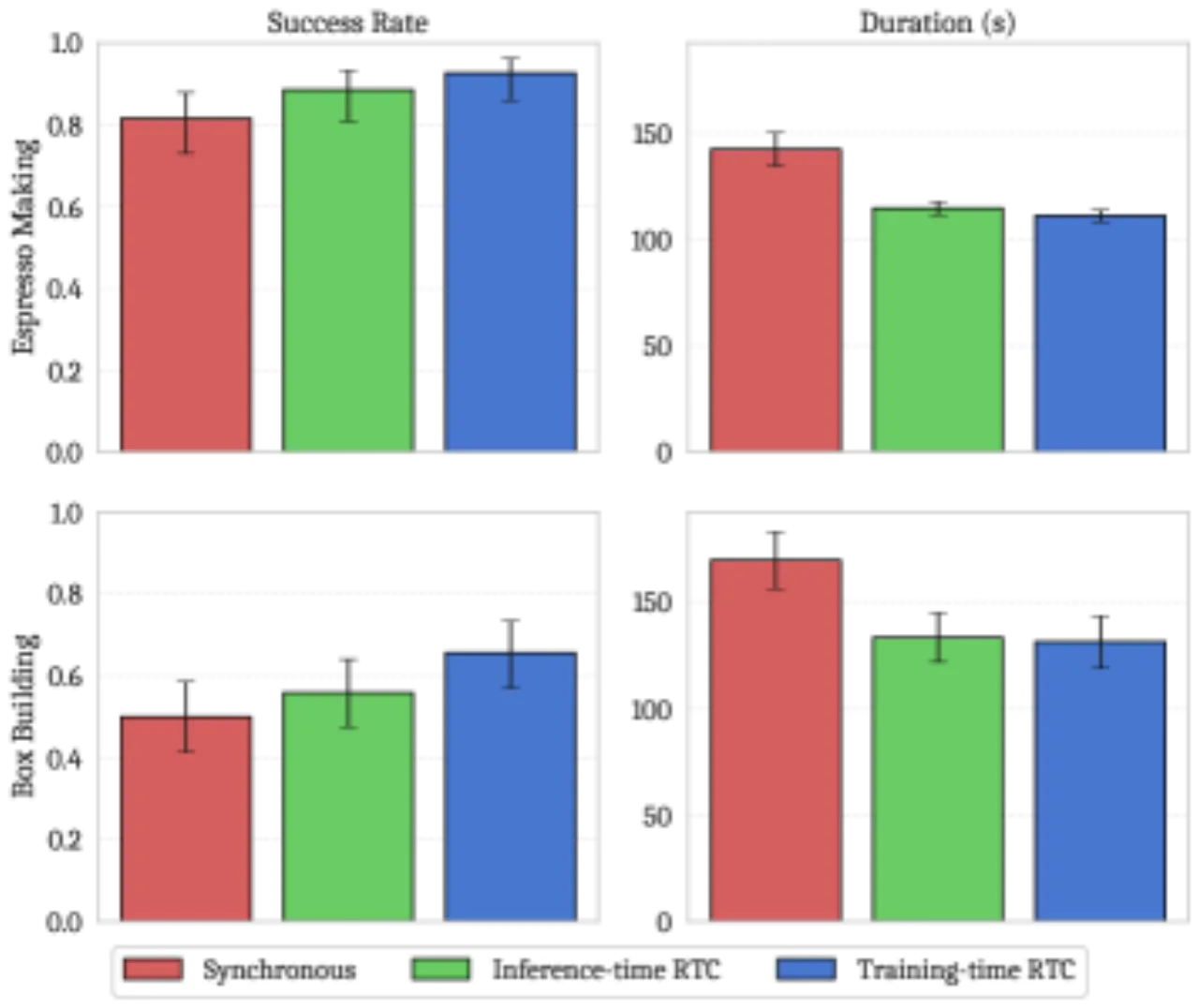
注:论文图表(Figure 5)以柱状图形式呈现具体成功率和时长,原文未在正文以数字明确列出精确百分比。实验结论为 "training-time RTC maintains both task performance and speed parity with inference-time RTC while being computationally cheaper"。
关键结论
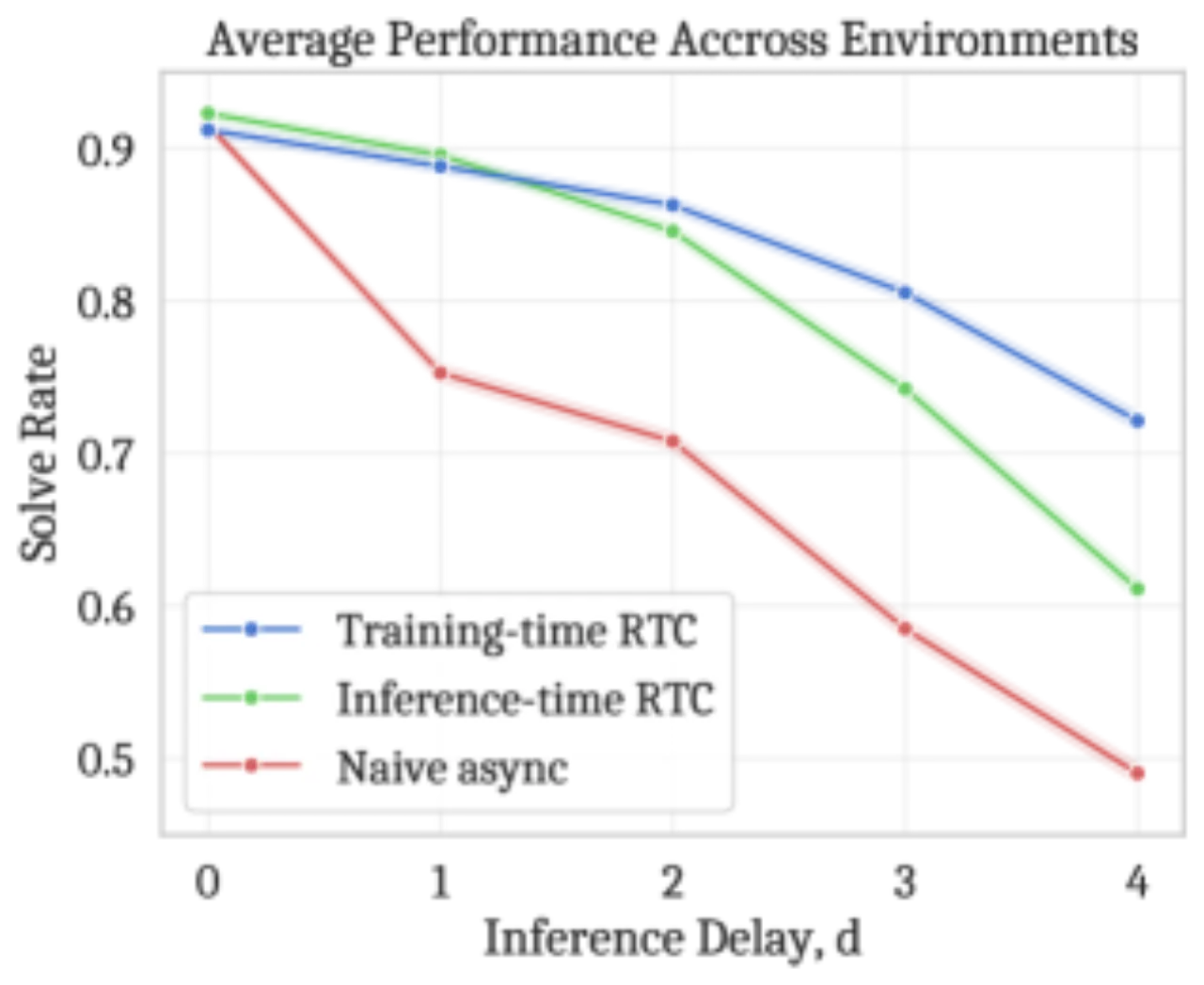
Training-time RTC 与 inference-time RTC 在两个真实任务上性能持平,同时减少了推理延迟(108ms vs. 135ms)。
如原文所述:"training-time RTC is fundamentally less flexible than inference-time RTC; it only supports conditioning on a 'hard' action prefix corresponding to the inference delay, whereas inference-time RTC can 'softly' incorporate additional actions beyond the prefix."
即 training-time RTC 只能处理固定 d 步的 hard prefix,无法像 inference-time RTC 那样对 prefix 之外的重叠动作进行软性加权引导。