01 动机
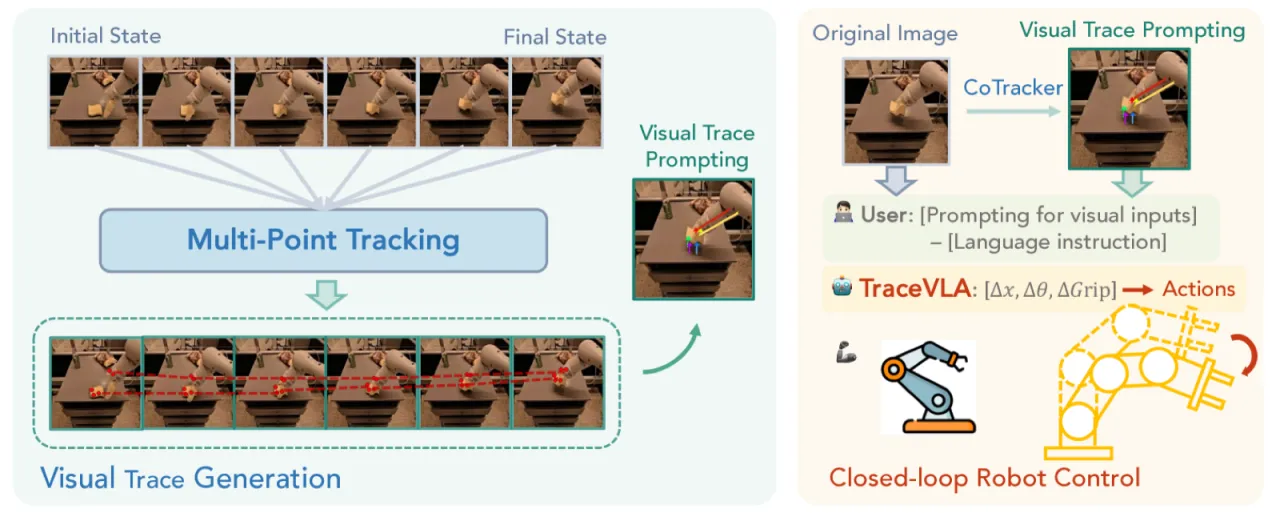
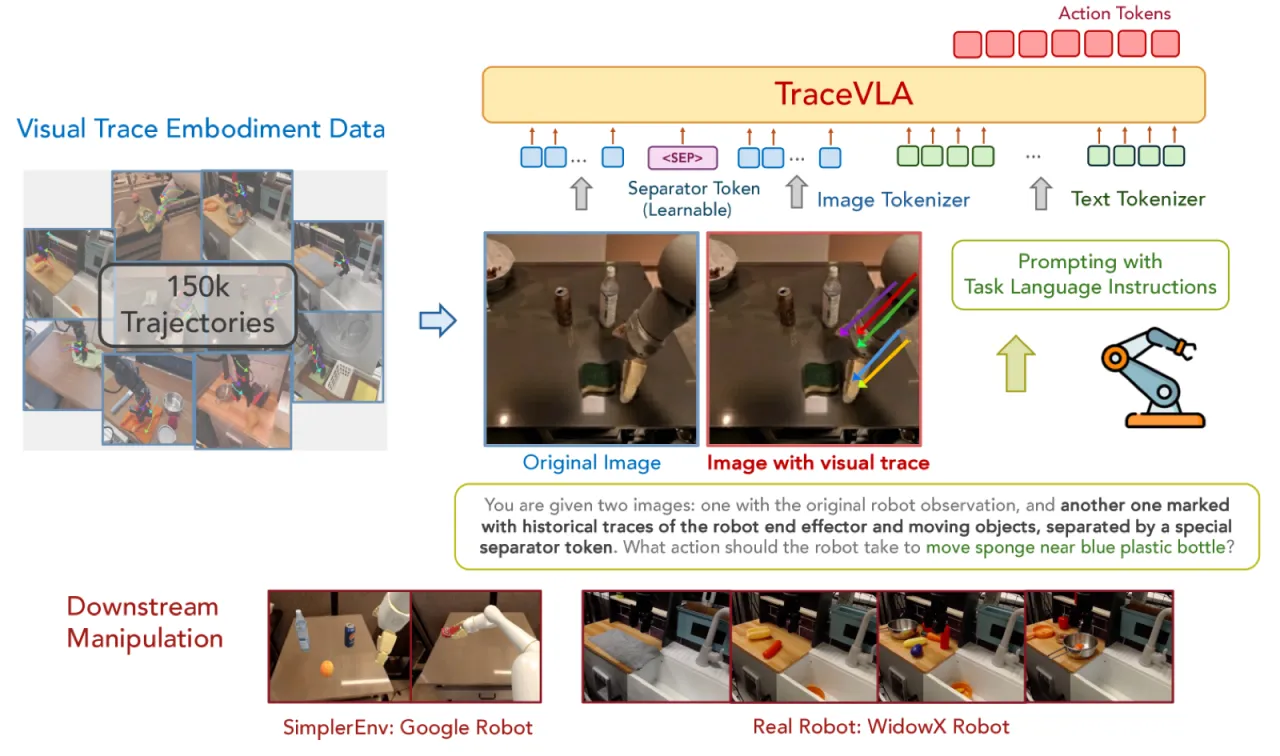
大型视觉-语言-动作(VLA)模型在机器人操控领域展现出强大的泛化能力,但它们往往只"看当下"——忽视了机器人自身的历史运动轨迹,导致决策更多是对当前帧的被动反应,而非对空间历史的主动推理。
"VLA-powered robots often struggle to maintain awareness of their past movements, leading to decisions that are more reactive to current inputs rather than informed by spatial history."
已有方法尝试将历史帧拼接输入或用文本坐标描述轨迹,但效果有限:拼接六帧历史图像反而使性能下降 6%;文本轨迹描述仅带来约 2.4% 的提升。根本原因在于 VLA 的 backbone(视觉编码器)并未针对时序感知专门训练,无法从原始图像差异中有效提取运动信息。
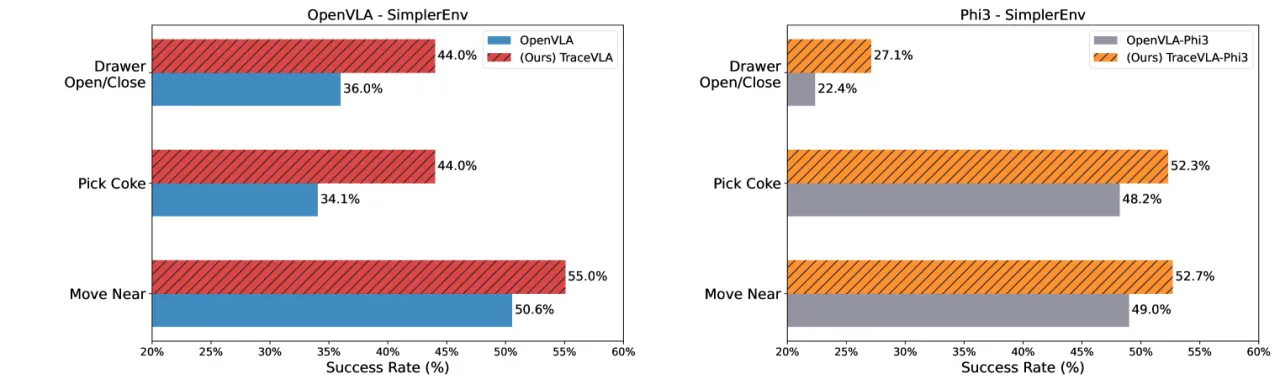
~10%SimplerEnv 137 项平均提升
(vs. OpenVLA 7B)
(vs. OpenVLA 7B)
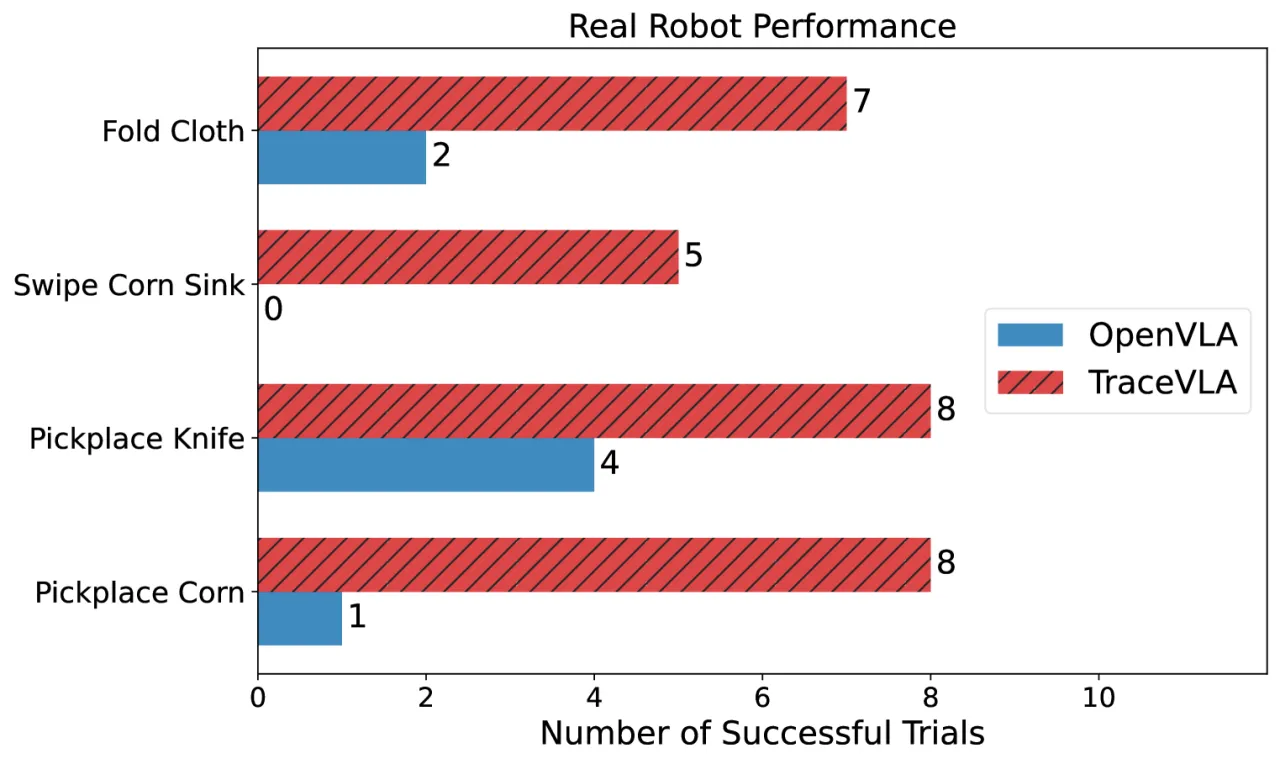
3.5×真实机器人任务成功率提升
(WidowX-250)
(WidowX-250)
+4.2%LIBERO 四套基准平均提升
(74.8% vs. 70.6%)
(74.8% vs. 70.6%)
8/10非训练任务 pick-place corn
(OpenVLA 仅 1/10)
(OpenVLA 仅 1/10)