01 动机
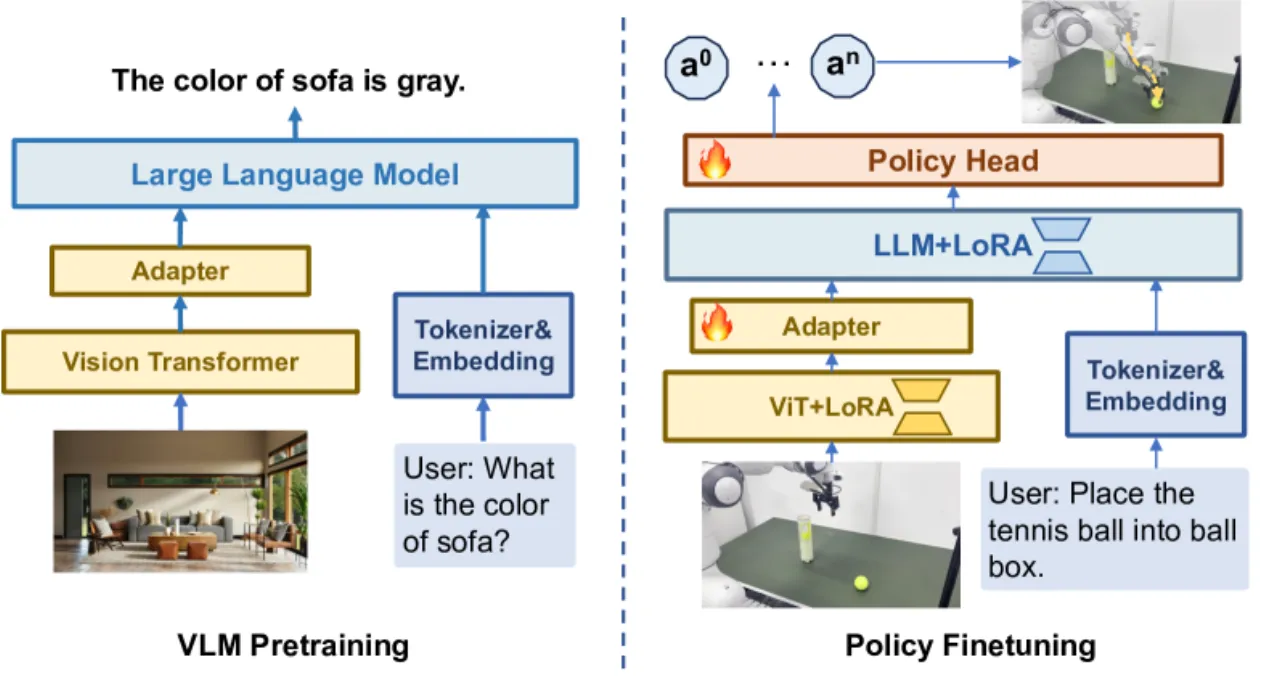
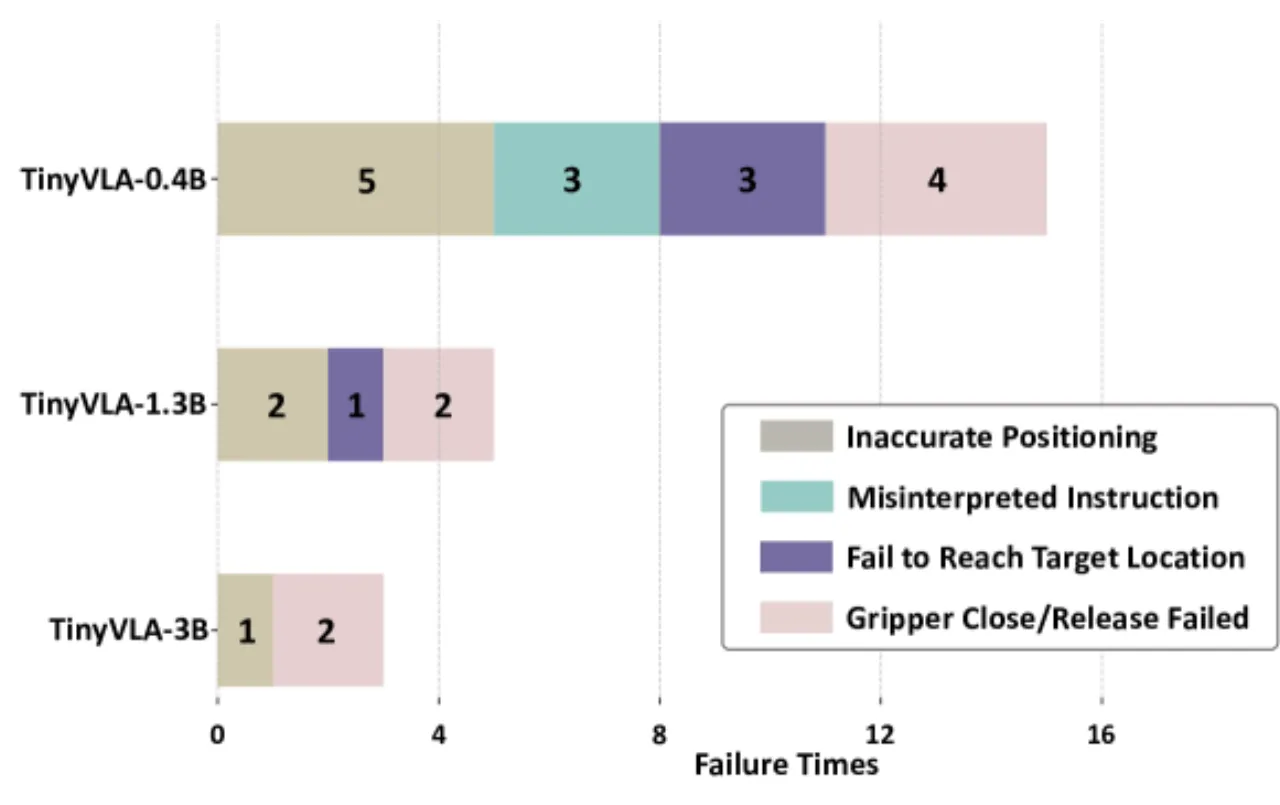
现有 VLA 模型(如 OpenVLA)存在两大核心瓶颈:其一,需要在包含 970K 条样本的大规模机器人数据集上进行耗时预训练;其二,基于 7B+ 参数语言模型的自回归 token 生成导致推理延迟高达 292ms,无法满足实时控制需求。
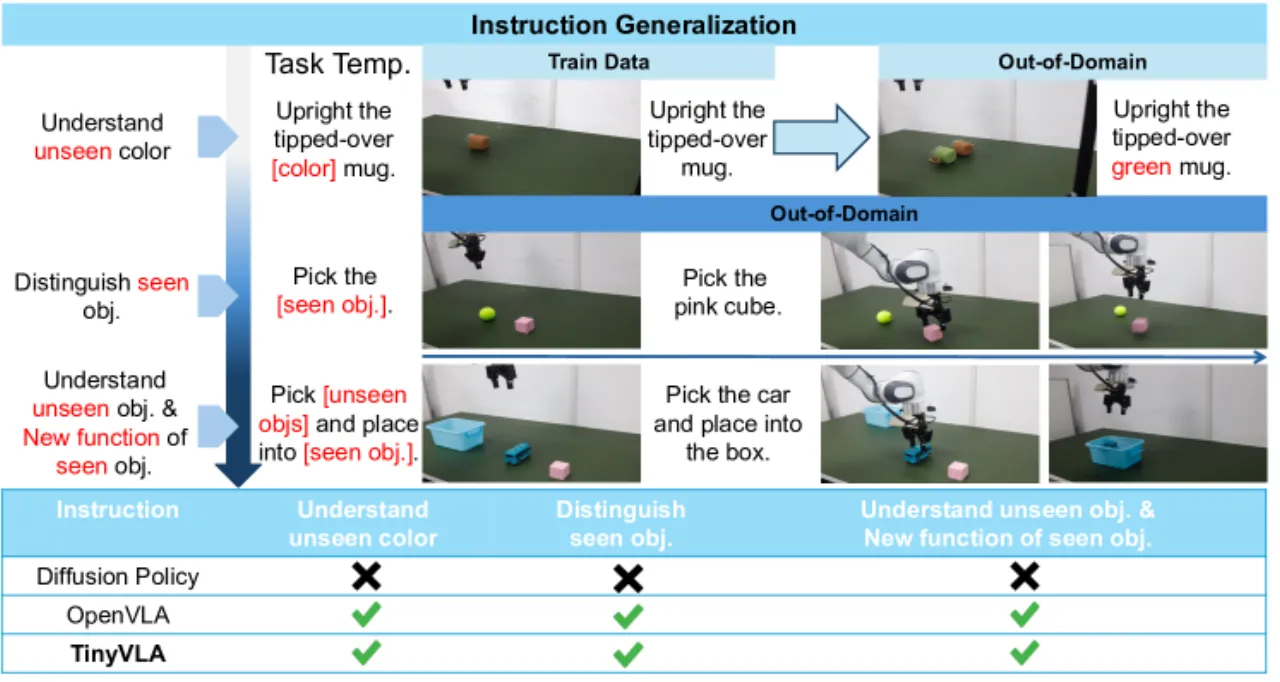
"Our framework achieves faster inference speeds, and improved data efficiency, eliminating the need for pre-training stage."
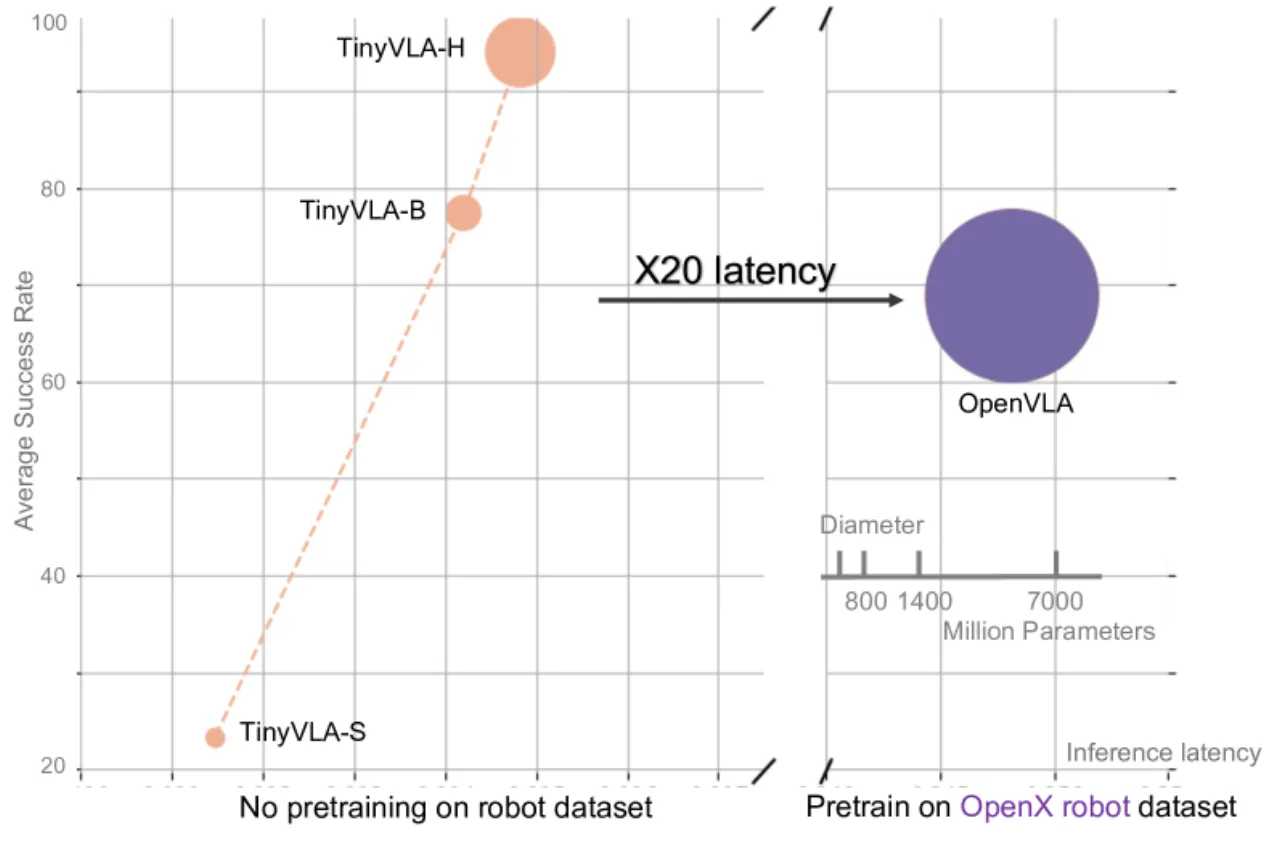
20×推理速度提升
(vs. OpenVLA-7B)
(vs. OpenVLA-7B)
14msTinyVLA-H 每步推理延迟
94.0%真实机械臂平均成功率(5 任务)
5.5×参数量减少倍数
(vs. OpenVLA)
(vs. OpenVLA)