01 动机
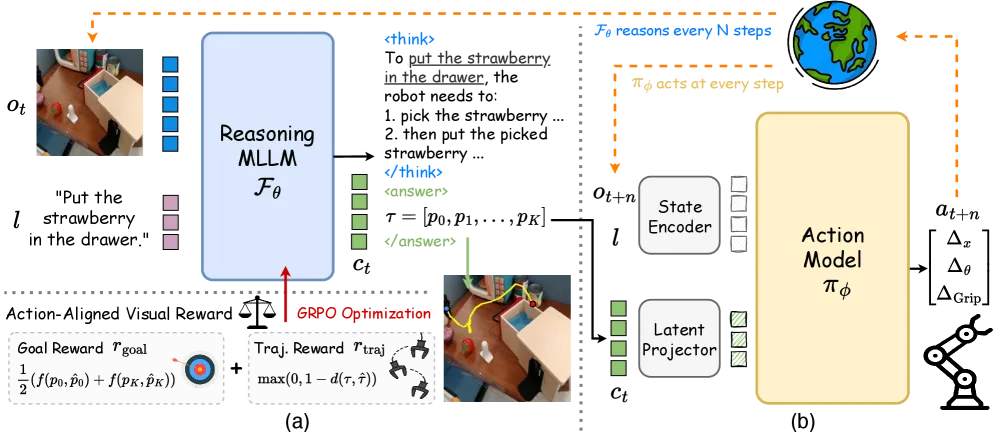
现有 VLA 模型通常以端到端方式将多模态输入直接映射到低层动作,缺乏显式推理过程,导致在多步规划和复杂任务变体上表现不足。尽管思维链(Chain-of-Thought, CoT)方法有所改进,但依赖昂贵的人工标注;基于问答(QA)风格的强化学习奖励则难以支撑具身规划的视觉基础。
"Existing approaches typically train VLA models in an end-to-end fashion, directly mapping inputs to actions without explicit reasoning, which hinders their ability to plan over multiple steps or adapt to complex task variations."

71.5%SimplerEnv Google-VM 成功率
(DiT-Policy:56.0%)
(DiT-Policy:56.0%)
84.4%LIBERO 综合成功率
(DiT-Policy:76.8%)
(DiT-Policy:76.8%)
48.2%EgoPlan-Bench2 准确率
(Qwen2.5-VL*:45.7%)
(Qwen2.5-VL*:45.7%)
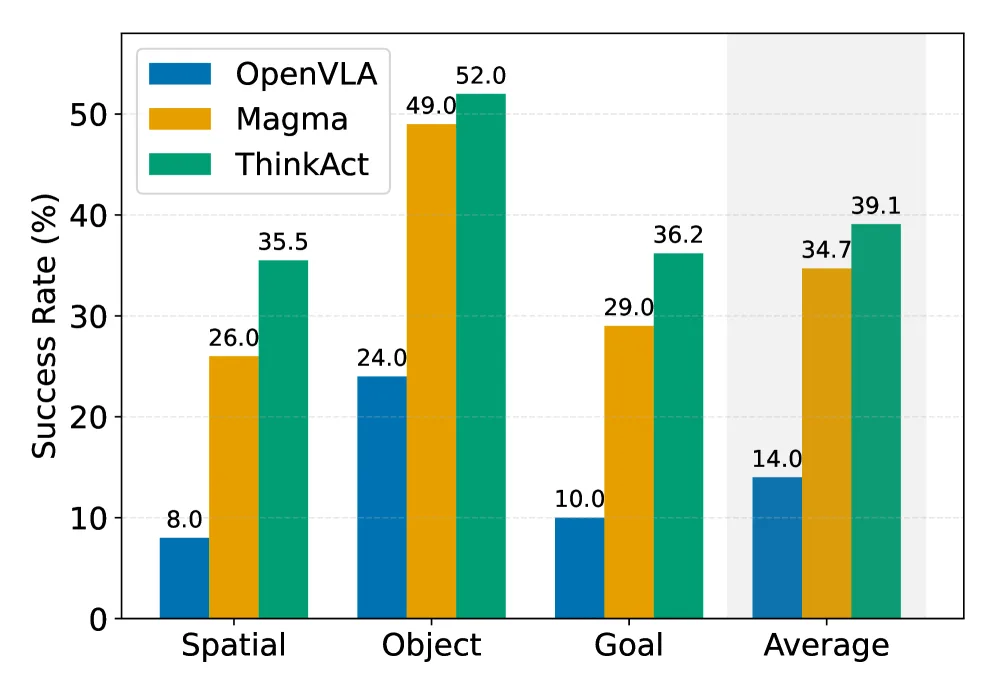
+9.5%LIBERO-Spatial 10-shot
超越 Magma 的提升幅度
超越 Magma 的提升幅度