01 动机
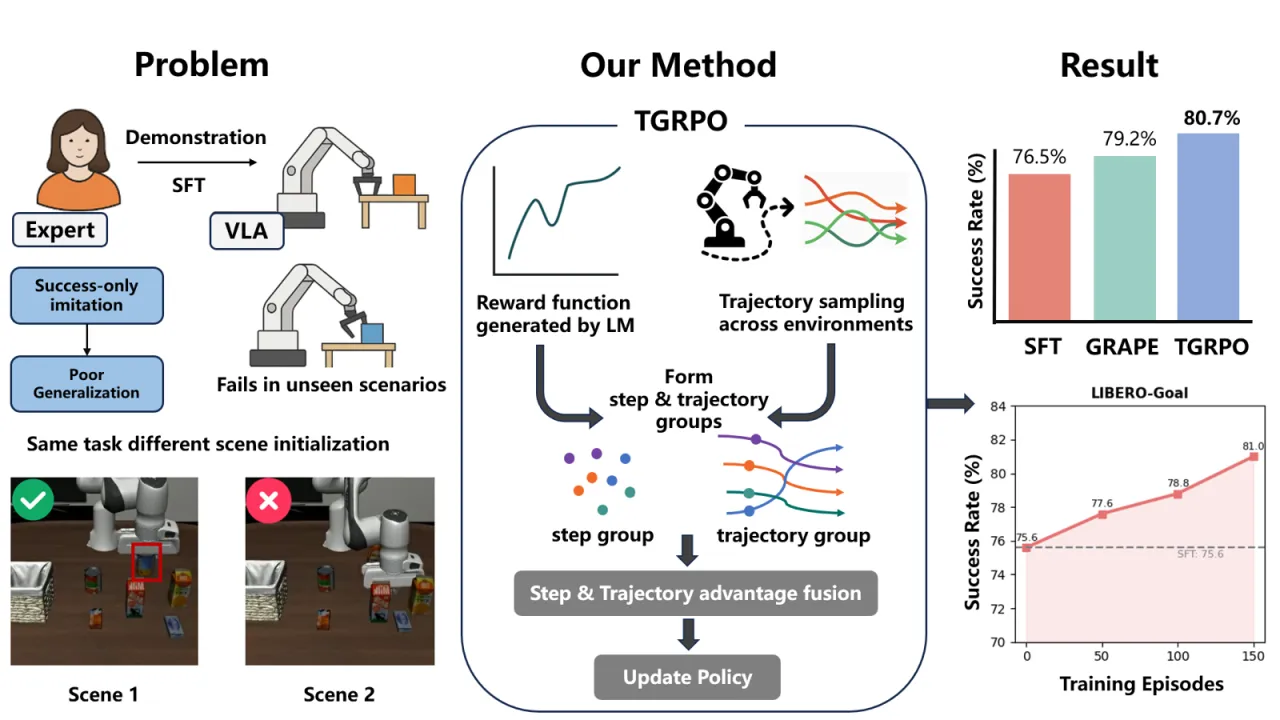
VLA 模型的 SFT 范式将机器人局限于"动作记忆",无法自主探索与自我修正。稀疏的二值奖励信号则让在线 RL 训练极为困难——这正是 TGRPO 要解决的两大核心矛盾。
"VLA models trained solely on human-provided successful demonstrations … lacks the ability to learn from failures, restricting autonomous exploration and self-correction capabilities. Additionally, reward signals in real-world robotic tasks are often highly sparse, frequently reduced to binary success/failure feedback."
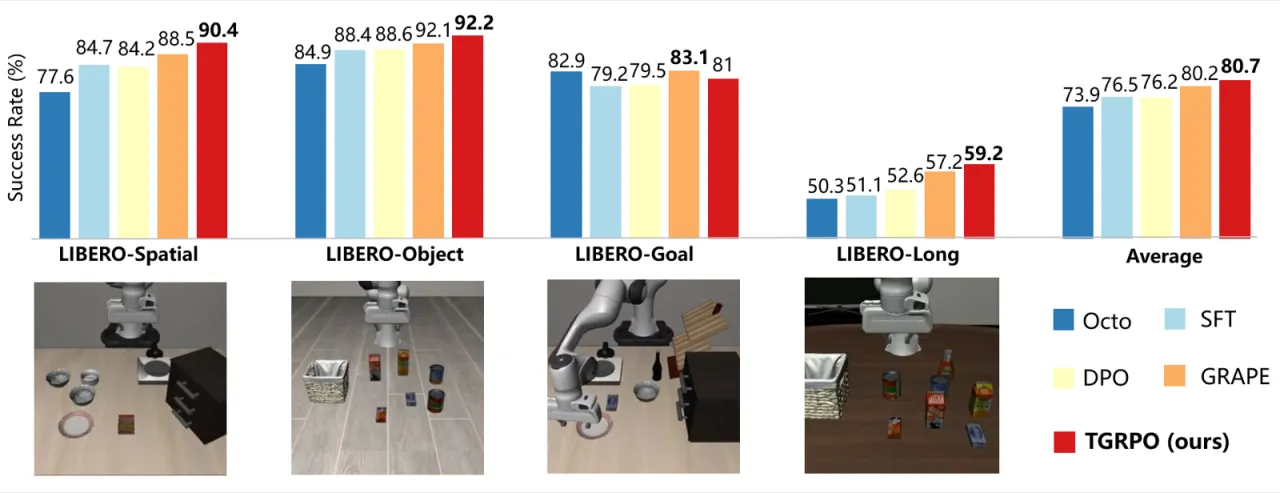
80.7%LIBERO 平均成功率(TGRPO)
+4.2%vs. SFT 基线
+8.1%LIBERO-Long vs. SFT
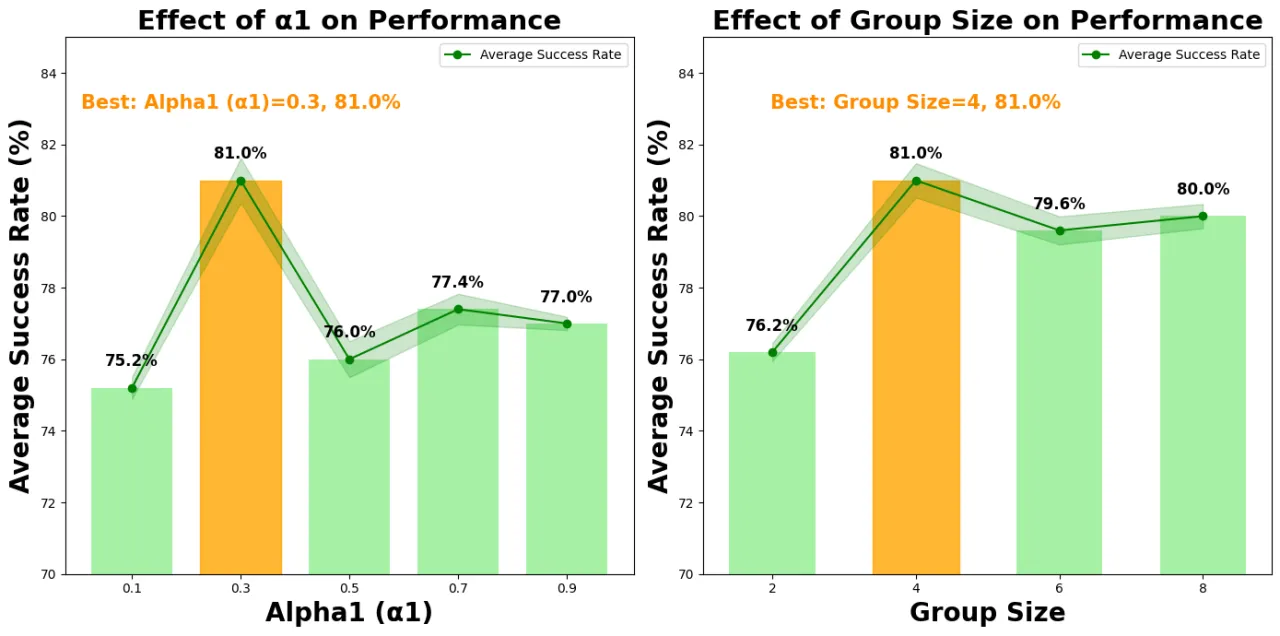
4并行环境数(N=4 最优)
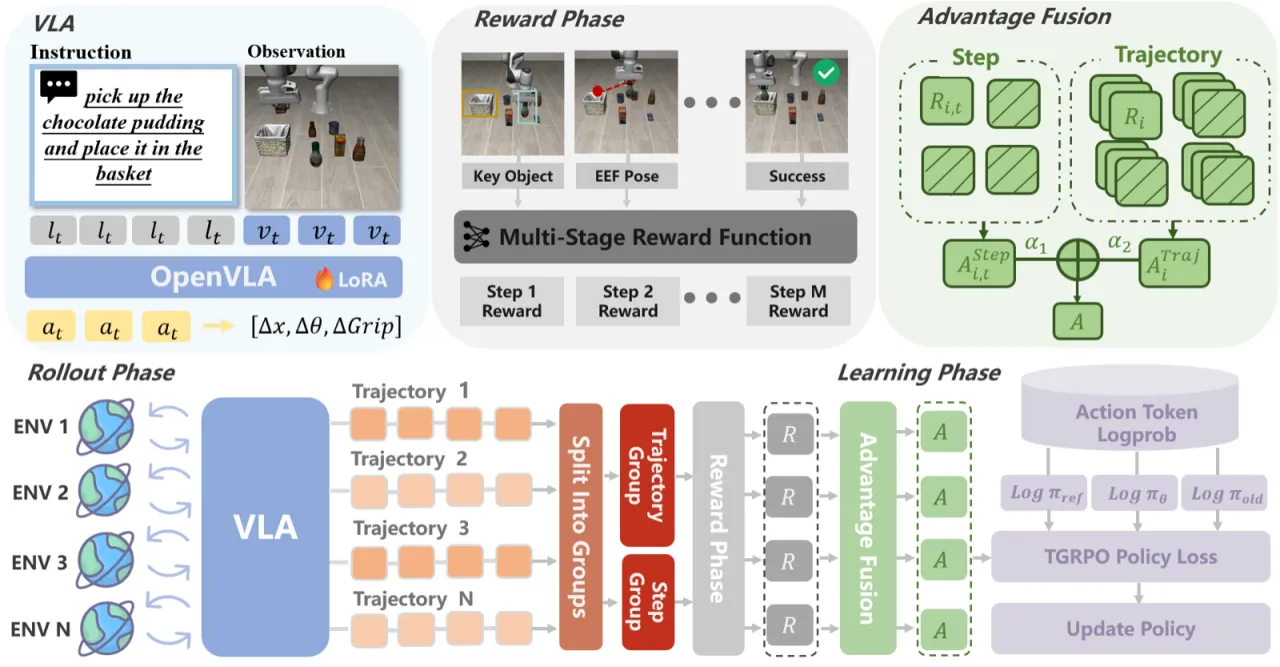
背景:GRPO 在 VLA 上的挑战
Group Relative Policy Optimization (GRPO) 通过在组内归一化奖励来估计优势,无需额外的 Critic 网络,已在 LLM 数学推理中展现出色效率。然而直接迁移到机器人操作面临两大障碍:①机器人任务奖励极稀疏,组内方差过大导致梯度估计不稳定;②原版 GRPO 以单步 token 为粒度,与轨迹级别的机器人任务不匹配。TGRPO 通过多阶段密集奖励设计与双层分组策略解决这两点。