01 动机
Vision-Language-Action (VLA) 模型凭借强大的视觉-语言先验在机器人操作中展现出令人印象深刻的泛化能力, 但在接触密集型任务中,它们仍无法将抽象的语义意图精确地落地为细粒度的力控交互。 力感知(tactile sensing)是弥补这一鸿沟的关键缺失环节。
"We advance VLAs' implicit knowledge beyond identifying what to do, towards guiding how to physically interact with real world."

90%充电器插拔成功率(Tactile-VLA)
基线 π₀: 40%
基线 π₀: 40%
9.13 N"hard" 零样本力控
基线无法区分指令
基线无法区分指令
80%黑板擦拭成功率(Tactile-VLA-CoT)
所有基线: 0%
所有基线: 0%
少量示范即可激活 VLM 的物理先验
实现零样本泛化
实现零样本泛化
问题背景
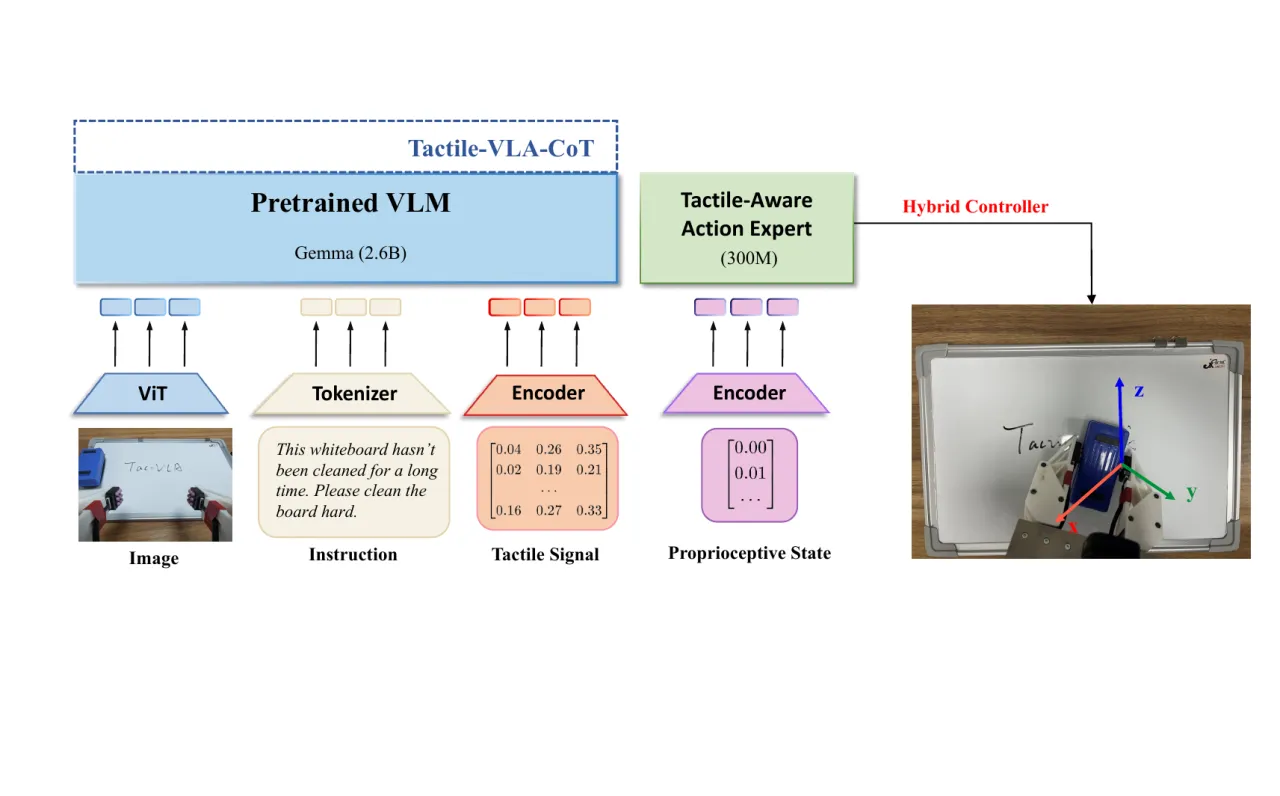
当前 VLA 模型(如 π₀、π₀-fast)擅长高层次规划,但在接触密集型场景中缺乏对力控制的精细感知与调节能力。 现有将触觉/力觉引入机器人框架的工作通常将其作为附加感知模态,而非直接参与动作生成的核心要素。 Tactile-VLA 的核心洞见是:VLA 模型的语言骨干已隐式编码了丰富的物理交互知识(例如"softly"与"firmly"对应的力度差异), 只需将触觉传感器与少量示范数据"桥接"进来,便可将这种先验激活并泛化至全新场景。
论文聚焦三类泛化能力,分别对应三个研究问题:
- RQ1 (Tactile-Aware Instruction Following):模型能否从一个任务中学习力相关语言的语义,并零样本迁移至新任务?
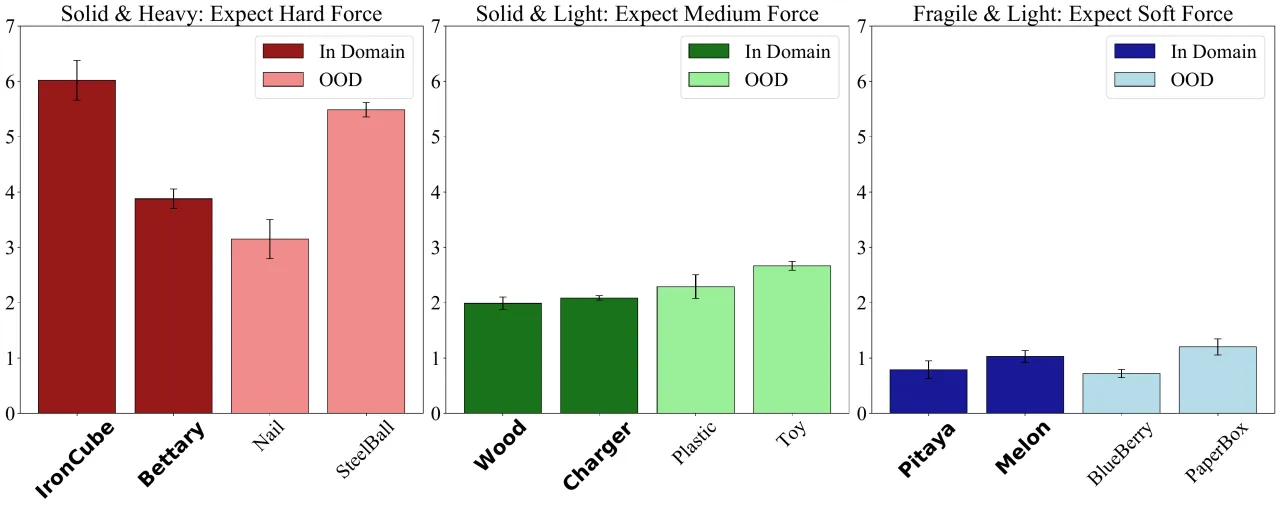
- RQ2 (Tactile-Relevant Common Sense):模型能否利用 VLM 的常识推断未见物体所需的交互力?
- RQ3 (Tactile-Involved Reasoning):触觉反馈能否驱动模型识别任务失败并自主调整策略?