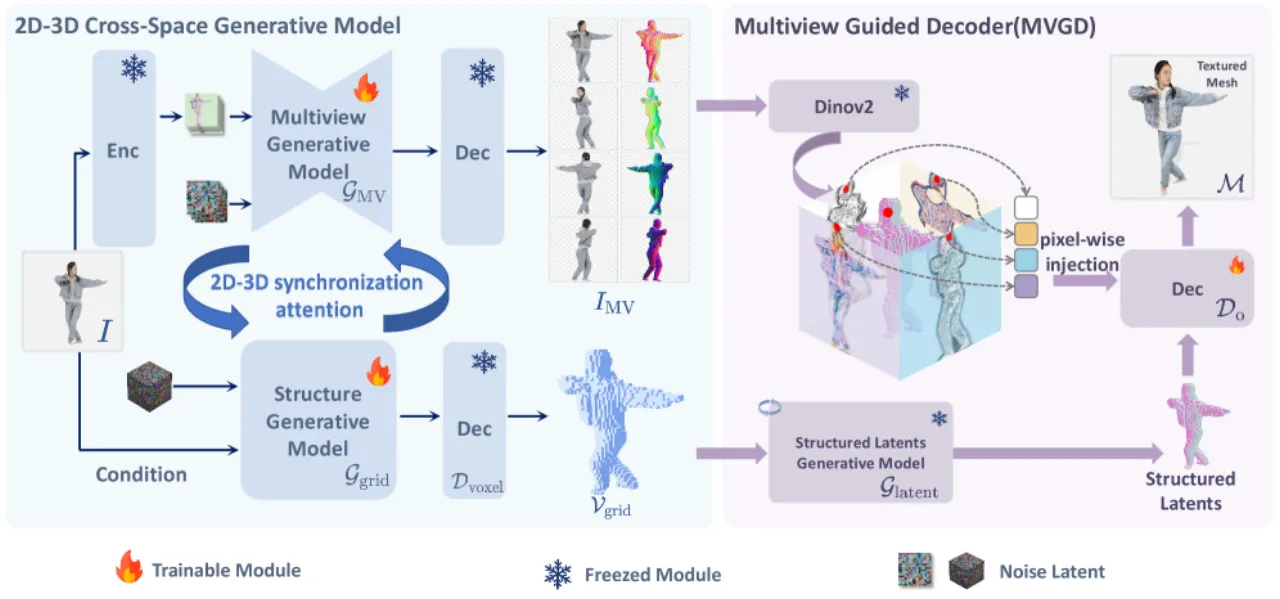
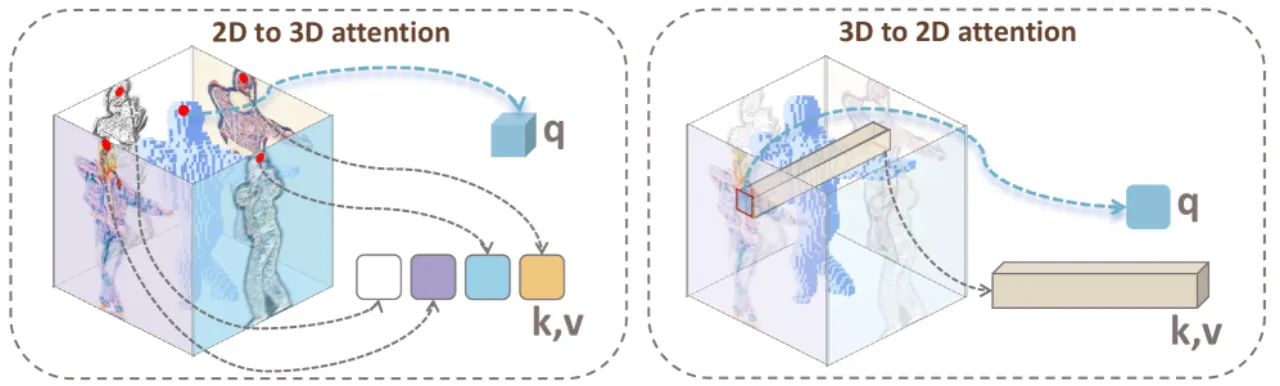
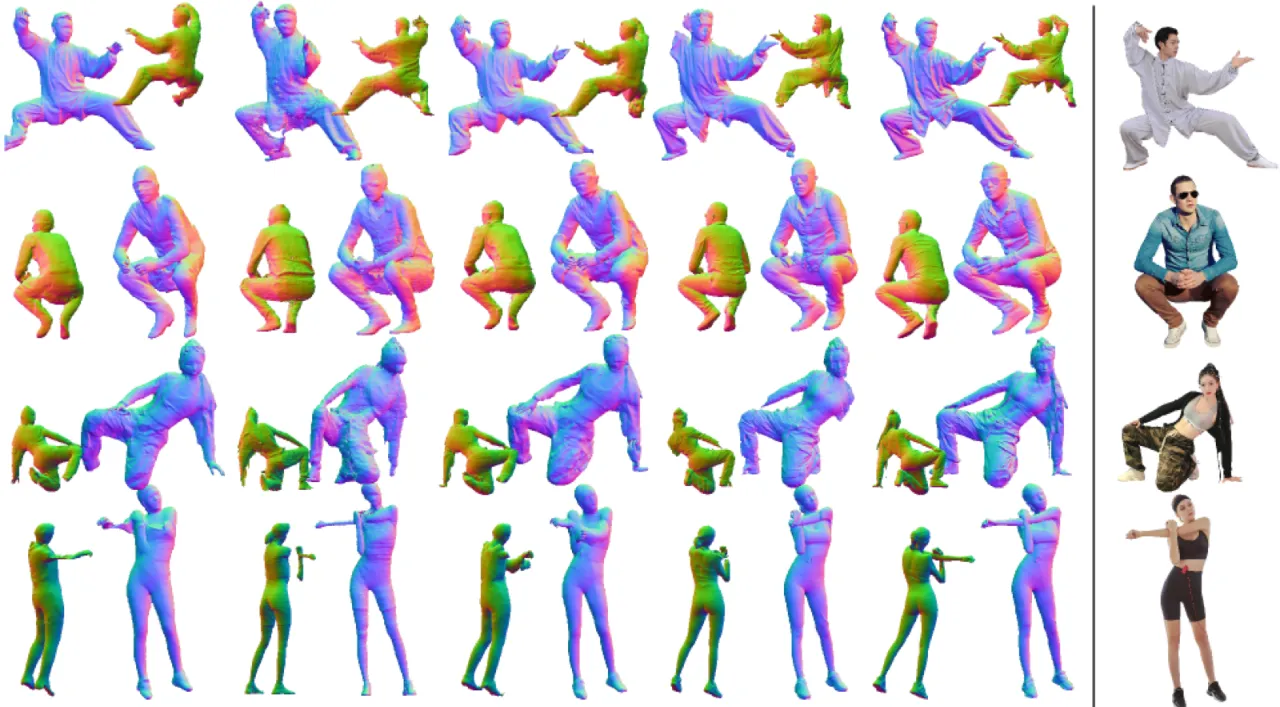01 动机
从单张图像重建穿衣人体的三维模型,是计算机视觉中的核心难题。现有方法面临两难困境:多视图 2D 生成模型(如 PSHuman)能捕捉精细纹理细节,但生成的多视图图像与三维结构缺乏一致性;而 3D 原生生成模型(如 Trellis)能生成连贯的几何形状,却缺乏精细细节,且严重依赖不准确的 SMPL 姿态估计。
"我们提出了一种新型框架,联合利用多视图和 3D 原生生成模型的优势,同时克服各自的局限性。"
0.8353Chamfer Distance ↓
(X-Humans,越低越好)
(X-Humans,越低越好)
21.84PSNR ↑
(X-Humans,越高越好)
(X-Humans,越高越好)
0.8741SSIM ↑
(X-Humans)
(X-Humans)
0.0786LPIPS ↓
(X-Humans,越低越好)
(X-Humans,越低越好)
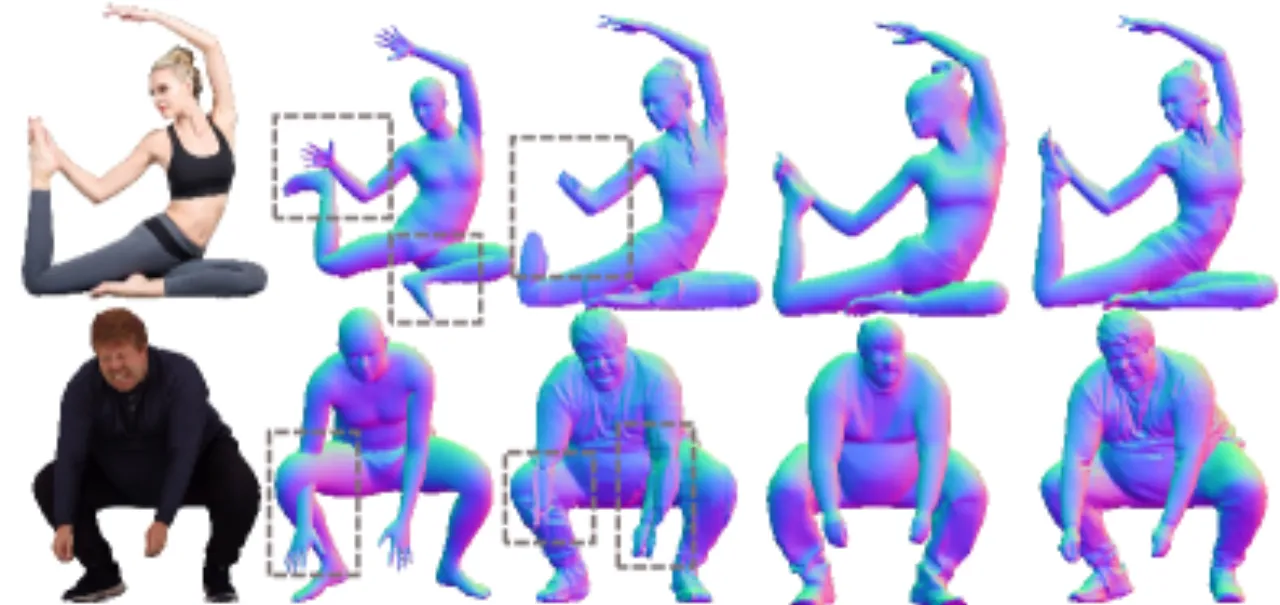
多视图 2D 方法的问题
- 多视图图像间三维结构不一致
- 从不一致视图重建导致几何误差累积
- 依赖扩散模型的随机性,无法保证跨视图一致性
3D 原生方法的问题
- 严重依赖 SMPL 姿态估计,误差传播明显
- 生成形状细节粗糙,纹理质量差
- 复杂服装结构难以保真重建