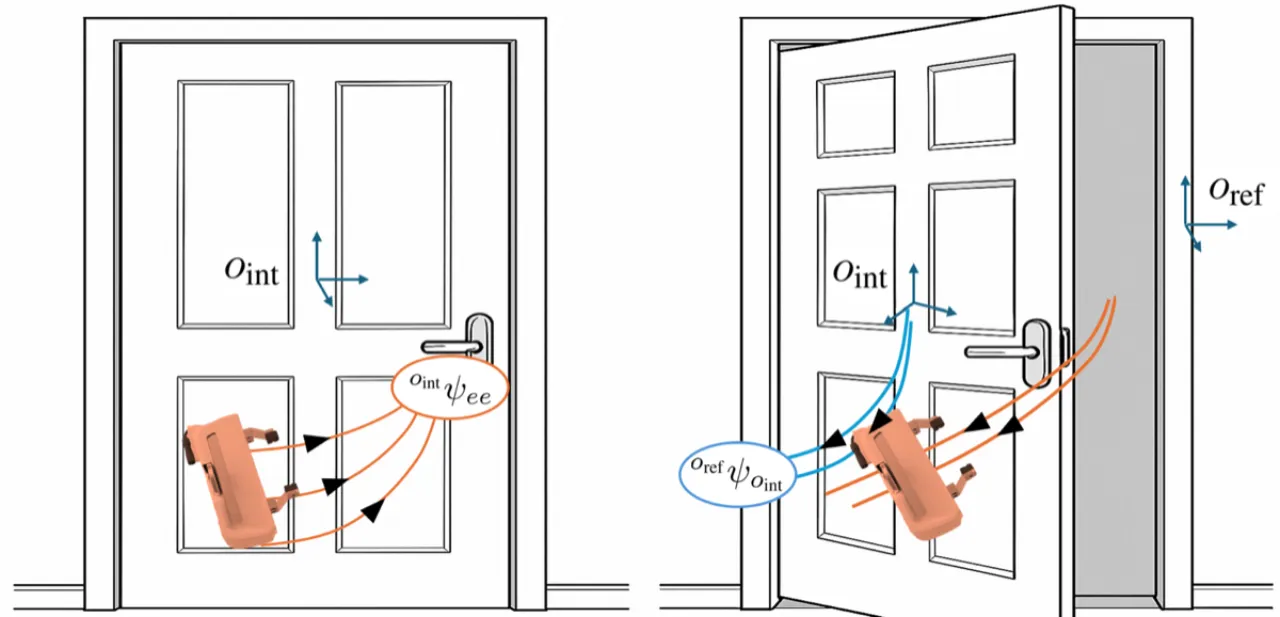
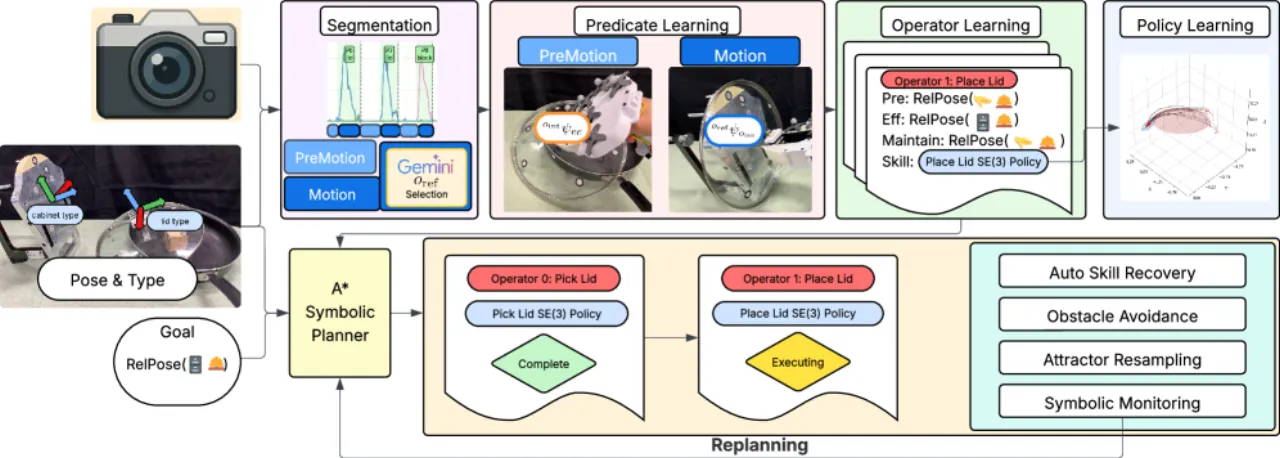
01 动机
当前机器人操作领域的两大主流范式——模仿学习与任务规划——分别存在根本性缺陷:前者缺乏可组合性,后者规划延迟高达数十秒,无法在动态环境中实时恢复故障。SymSkill 旨在融合两者的优势。
"Recent imitation learning approaches excel at reproducing skills from large datasets but tend to learn monolithic policies rather than reusable skills and predicates that compose into multi-step plans."
模仿学习的问题
- 学习的是单块式策略(monolithic policy),难以跨任务复用
- 缺乏符号结构,无法通过规划组合成多步骤计划
- 依赖大量标注演示(如 NSIL 需要 200 条)
任务与运动规划(TAMP)的问题
- 规划延迟极高(>50 秒),无法实时应对动态变化
- 需要人工设计谓词和算子,工程量大
- 低层运动规划器对扰动鲁棒性不足
1–10所需演示条数(对比 NSIL/LAMP 的 200 条)
85%RoboCasa 12 任务平均成功率
<100ms符号规划延迟(对比 LAMP/NOD-TAMP 的 >50s)
5 分钟真实机器人所需 play data 时长