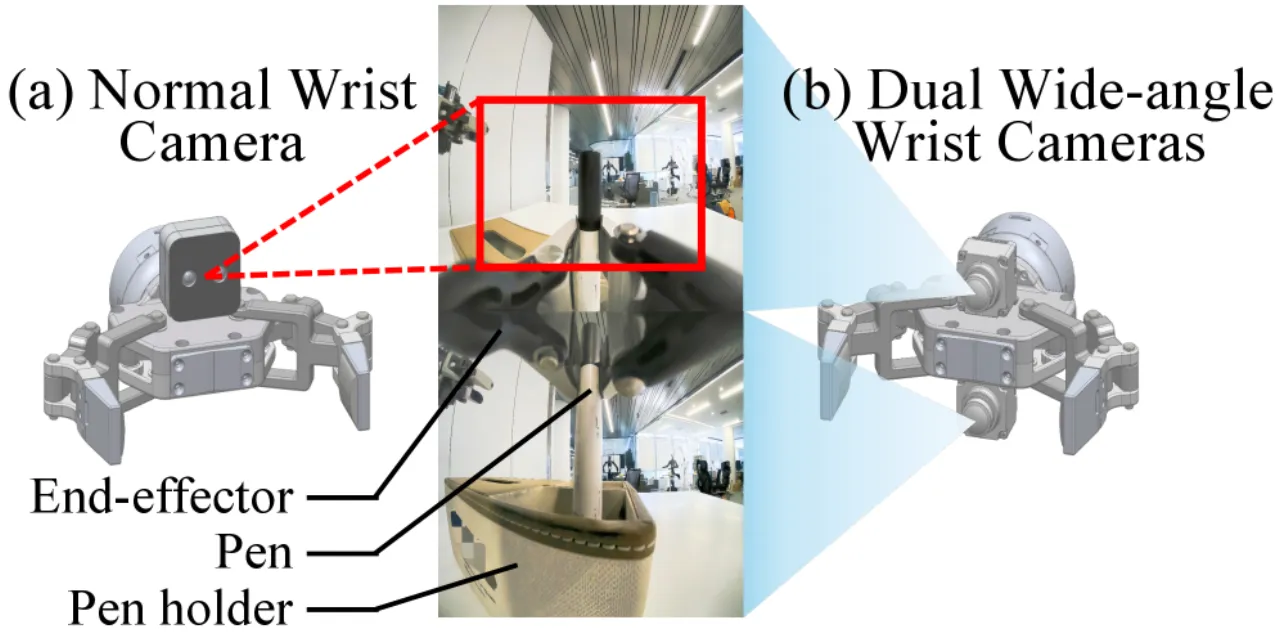
01 动机
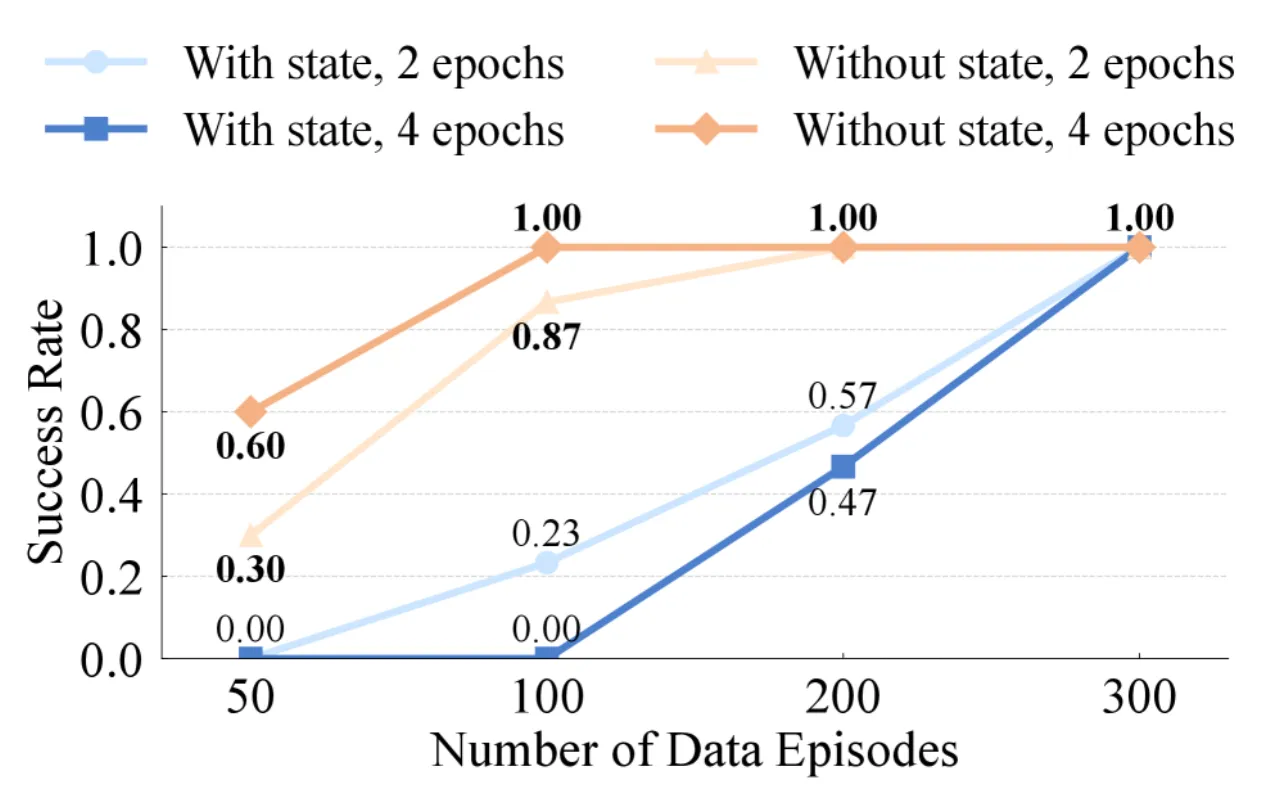
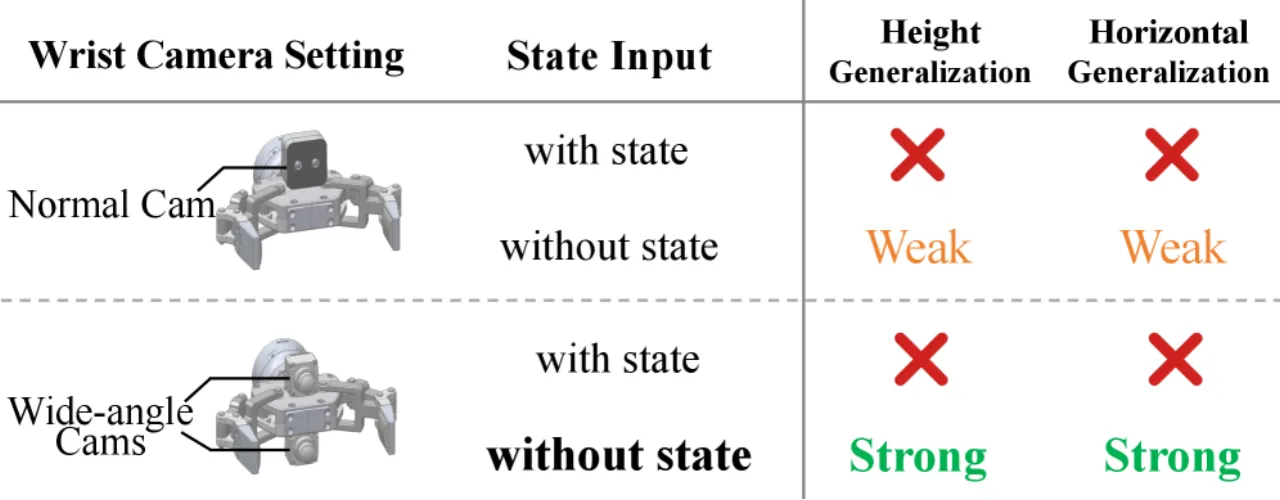
本体感知状态(关节角度、末端执行器绝对位姿等)长期以来被视为视觉运动策略的必要输入——但它真的有帮助吗?作者通过系统实验发现,状态输入反而会让策略"走捷径":在固定高度、固定位置训练后,只要物体位置稍有变动,成功率就从98%骤降至0%。
"State inputs may act as shortcuts that enable policies to memorize training trajectories tied to specific states, rather than developing true visual reasoning for task completion."
0% → 98.4%Pick Pen 高度泛化提升
6% → 58.4%Pick Pen 水平泛化提升
18.3% → 83.4%Fold Shirt 水平泛化提升
11.7% → 78.4%Fetch Bottle 全身机器人泛化提升
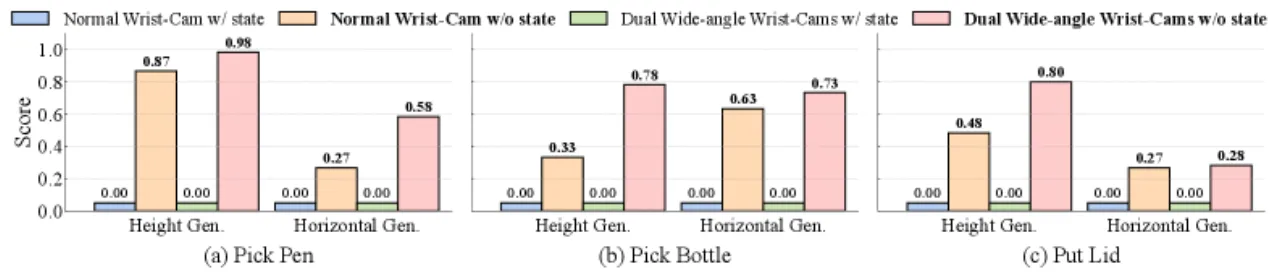
传统的 state-based 策略在域内(in-domain)表现良好,但当桌子高度变化±10cm 或物体水平偏移5~10cm 时,性能急剧下降。这种脆弱性在真实部署中代价极高。作者验证了该现象在三种不同机器人平台(双臂类人机器人、Arx5 系统、26自由度全身机器人)上均普遍存在。