01 动机
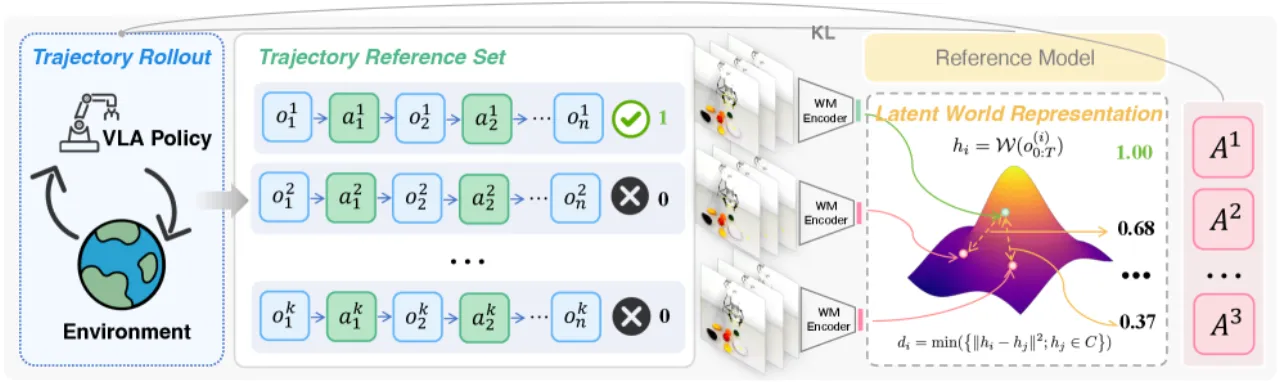
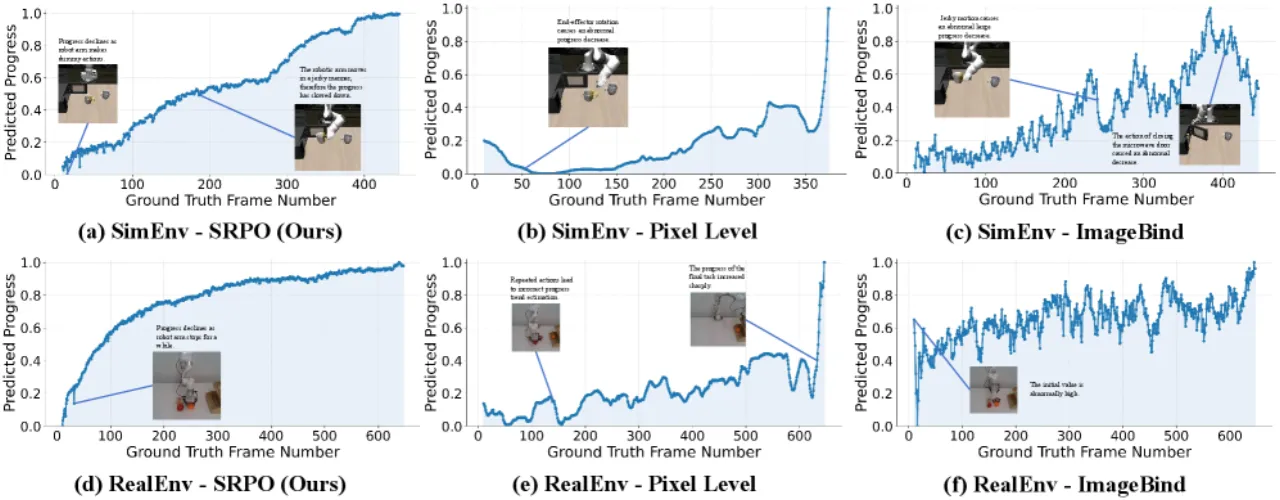
当前 VLA 模型过度依赖专家演示,导致严重的 demonstration bias(演示偏差)——模型只学会复制演示中的轨迹, 无法探索更优策略。强化学习(RL)是克服这一限制的关键,但现有 VLA-RL 方法面临两大困境: 稀疏奖励(仅依赖二值成功信号,失败轨迹的信息完全浪费) 以及繁琐的人工奖励工程(需任务相关的密集奖励,难以泛化)。
"Reinforcement learning (RL) is a vital post-training strategy to overcome these limits, yet current VLA-RL methods...are crippled by severe reward sparsity."
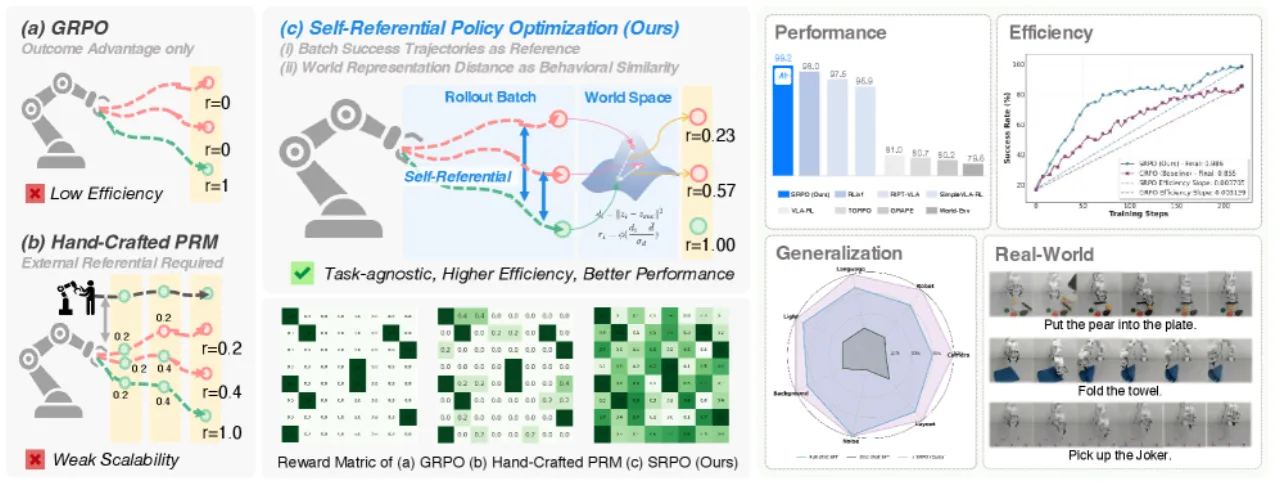
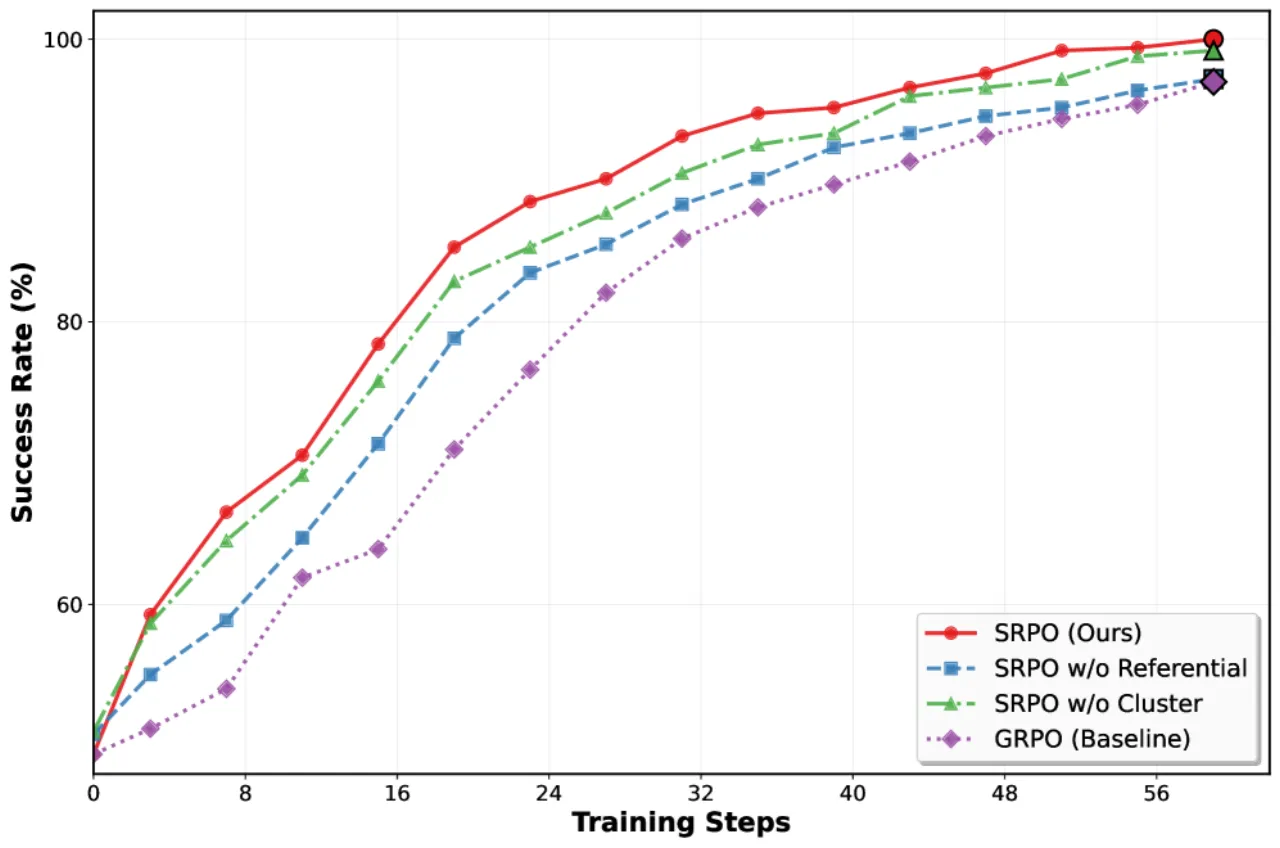
99.2%LIBERO Online SRPO 平均成功率
48.9%One-shot SFT 基线(起点)
103%相对提升(200 步内,无额外监督)
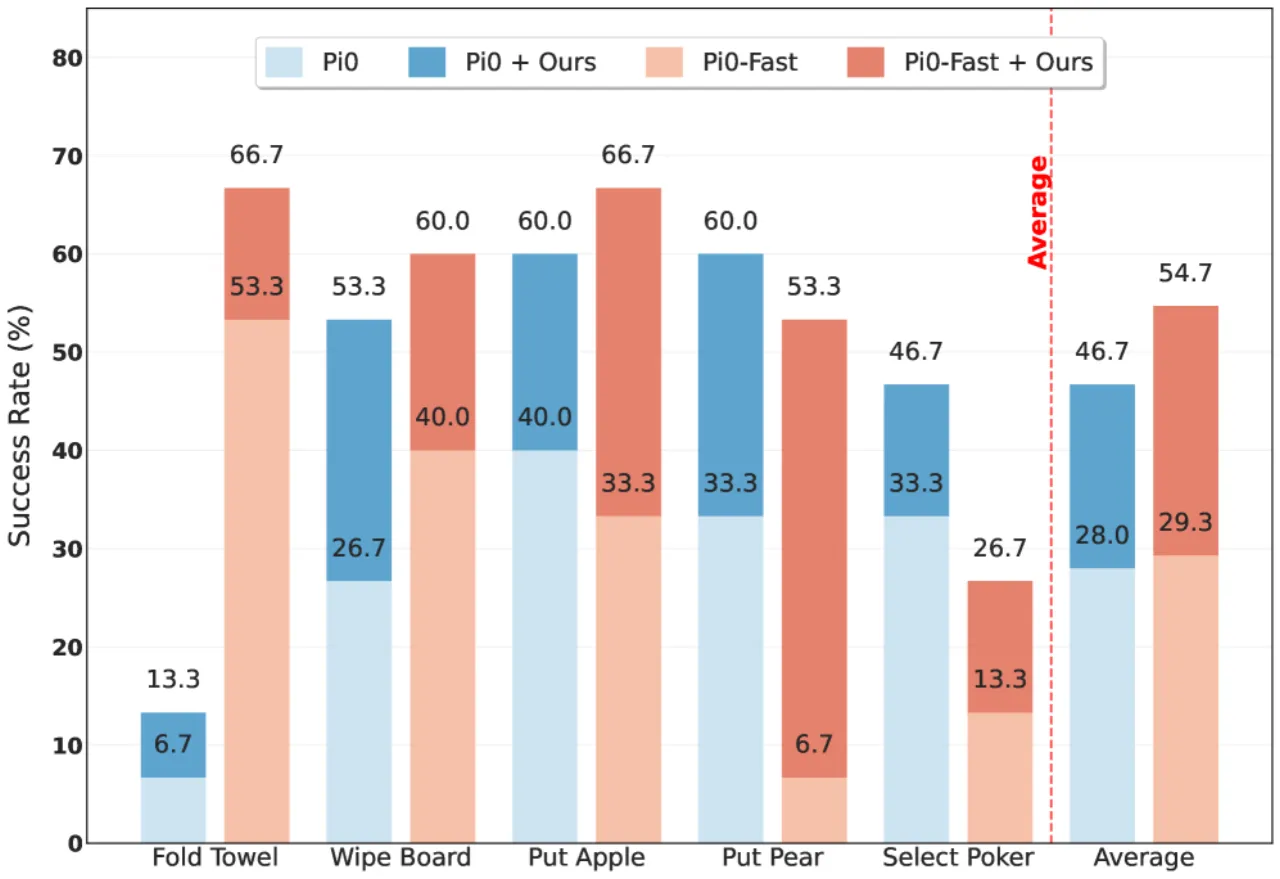
+86.7%真实机器人 π₀-FAST 改善幅度